 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooC: Effective Low-Dimensional Codebook for Compositional Vector Quantization
Jan 01, 2026Vector quantization (VQ) is a prevalent and fundamental technique that discretizes continuous feature vectors by approximating them using a codebook. As the diversity and complexity of data and models continue to increase, there is an urgent need for high-capacity, yet more compact VQ methods. This paper aims to reconcile this conflict by presenting a new approach called LooC, which utilizes an effective Low-dimensional codebook for Compositional vector quantization. Firstly, LooC introduces a parameter-efficient codebook by reframing the relationship between codevectors and feature vectors, significantly expanding its solution space. Instead of individually matching codevectors with feature vectors, LooC treats them as lower-dimensional compositional units within feature vectors and combines them, resulting in a more compact codebook with improved performance. Secondly, LooC incorporates a parameter-free extrapolation-by-interpolation mechanism to enhance and smooth features during the VQ process, which allows for better preservation of details and fidelity in feature approximation. The design of LooC leads to full codebook usage, effectively utilizing the compact codebook while avoiding the problem of collapse. Thirdly, LooC can serve as a plug-and-play module for existing methods for different downstream tasks based on VQ. Finally, extensive evaluations on different tasks, datasets, and architectures demonstrate that LooC outperforms existing VQ methods, achieving state-of-the-art performance with a significantly smaller codebook.
Unison: A Fully Automatic, Task-Universal, and Low-Cost Framework for Unified Understanding and Generation
Dec 08, 2025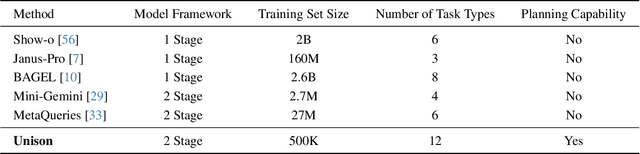
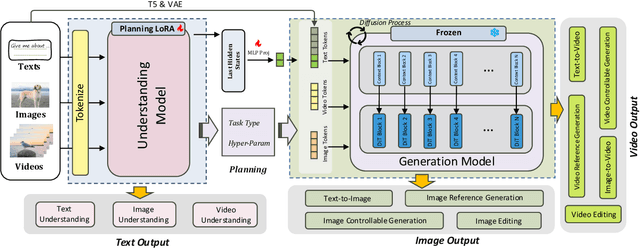


Unified understanding and generation is a highly appealing research direction in multimodal learning. There exist two approaches: one trains a transformer via an auto-regressive paradigm, and the other adopts a two-stage scheme connecting pre-trained understanding and generative models for alignment fine-tuning. The former demands massive data and computing resources unaffordable for ordinary researchers. Though the latter requires a lower training cost, existing works often suffer from limited task coverage or poor generation quality. Both approaches lack the ability to parse input meta-information (such as task type, image resolution, video duration, etc.) and require manual parameter configuration that is tedious and non-intelligent. In this paper, we propose Unison which adopts the two-stage scheme while preserving the capabilities of the pre-trained models well. With an extremely low training cost, we cover a variety of multimodal understanding tasks, including text, image, and video understanding, as well as diverse generation tasks, such as text-to-visual content generation, editing, controllable generation, and IP-based reference generation. We also equip our model with the ability to automatically parse user intentions, determine the target task type, and accurately extract the meta-information required for the corresponding task. This enables full automation of various multimodal tasks without human intervention. Experiments demonstrate that, under a low-cost setting of only 500k training samples and 50 GPU hours, our model can accurately and automatically identify tasks and extract relevant parameters, and achieve superior performance across a variety of understanding and generation tasks.
Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Jun 09, 2025



Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our codes are publicly available at \href{https://github.com/Vchitect/TACA}
SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
Apr 27, 2025Evaluating the step-by-step reliability of large language model (LLM) reasoning, such as Chain-of-Thought, remains challenging due to the difficulty and cost of obtaining high-quality step-level supervision. In this paper, we introduce Self-Play Critic (SPC), a novel approach where a critic model evolves its ability to assess reasoning steps through adversarial self-play games, eliminating the need for manual step-level annotation. SPC involves fine-tuning two copies of a base model to play two roles, namely a "sneaky generator" that deliberately produces erroneous steps designed to be difficult to detect, and a "critic" that analyzes the correctness of reasoning steps. These two models engage in an adversarial game in which the generator aims to fool the critic, while the critic model seeks to identify the generator's errors. Using reinforcement learning based on the game outcomes, the models iteratively improve; the winner of each confrontation receives a positive reward and the loser receives a negative reward, driving continuous self-evolution. Experiments on three reasoning process benchmarks (ProcessBench, PRM800K, DeltaBench) demonstrate that our SPC progressively enhances its error detection capabilities (e.g., accuracy increases from 70.8% to 77.7% on ProcessBench) and surpasses strong baselines, including distilled R1 model. Furthermore, applying SPC to guide the test-time search of diverse LLMs significantly improves their mathematical reasoning performance on MATH500 and AIME2024, outperforming state-of-the-art process reward models.
VipDiff: Towards Coherent and Diverse Video Inpainting via Training-free Denoising Diffusion Models
Jan 21, 2025



Recent video inpainting methods have achieved encouraging improvements by leveraging optical flow to guide pixel propagation from reference frames either in the image space or feature space. However, they would produce severe artifacts in the mask center when the masked area is too large and no pixel correspondences can be found for the center. Recently, diffusion models have demonstrated impressive performance in generating diverse and high-quality images, and have been exploited in a number of works for image inpainting. These methods, however, cannot be applied directly to videos to produce temporal-coherent inpainting results. In this paper, we propose a training-free framework, named VipDiff, for conditioning diffusion model on the reverse diffusion process to produce temporal-coherent inpainting results without requiring any training data or fine-tuning the pre-trained diffusion models. VipDiff takes optical flow as guidance to extract valid pixels from reference frames to serve as constraints in optimizing the randomly sampled Gaussian noise, and uses the generated results for further pixel propagation and conditional generation. VipDiff also allows for generating diverse video inpainting results over different sampled noise. Experiments demonstrate that VipDiff can largely outperform state-of-the-art video inpainting methods in terms of both spatial-temporal coherence and fidelity.
FasterCache: Training-Free Video Diffusion Model Acceleration with High Quality
Oct 25, 2024



In this paper, we present \textbf{\textit{FasterCache}}, a novel training-free strategy designed to accelerate the inference of video diffusion models with high-quality generation. By analyzing existing cache-based methods, we observe that \textit{directly reusing adjacent-step features degrades video quality due to the loss of subtle variations}. We further perform a pioneering investigation of the acceleration potential of classifier-free guidance (CFG) and reveal significant redundancy between conditional and unconditional features within the same timestep. Capitalizing on these observations, we introduce FasterCache to substantially accelerate diffusion-based video generation. Our key contributions include a dynamic feature reuse strategy that preserves both feature distinction and temporal continuity, and CFG-Cache which optimizes the reuse of conditional and unconditional outputs to further enhance inference speed without compromising video quality. We empirically evaluate FasterCache on recent video diffusion models. Experimental results show that FasterCache can significantly accelerate video generation (\eg 1.67$\times$ speedup on Vchitect-2.0) while keeping video quality comparable to the baseline, and consistently outperform existing methods in both inference speed and video quality.
BiGR: Harnessing Binary Latent Codes for Image Generation and Improved Visual Representation Capabilities
Oct 18, 2024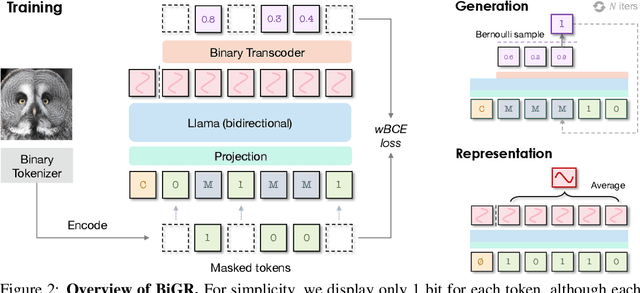
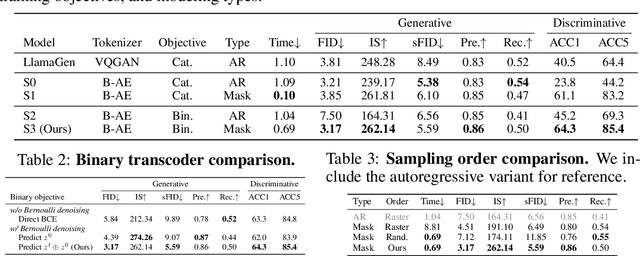
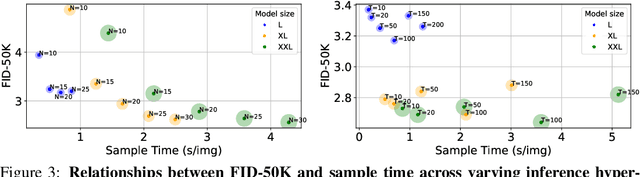
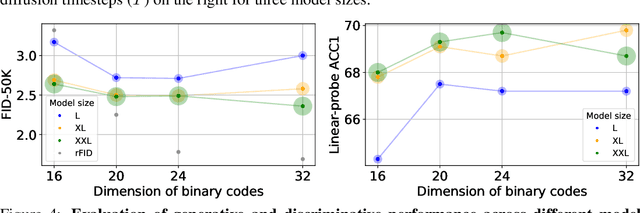
We introduce BiGR, a novel conditional image generation model using compact binary latent codes for generative training, focusing on enhancing both generation and representation capabilities. BiGR is the first conditional generative model that unifies generation and discrimination within the same framework. BiGR features a binary tokenizer, a masked modeling mechanism, and a binary transcoder for binary code prediction. Additionally, we introduce a novel entropy-ordered sampling method to enable efficient image generation. Extensive experiments validate BiGR's superior performance in generation quality, as measured by FID-50k, and representation capabilities, as evidenced by linear-probe accuracy. Moreover, BiGR showcases zero-shot generalization across various vision tasks, enabling applications such as image inpainting, outpainting, editing, interpolation, and enrichment, without the need for structural modifications. Our findings suggest that BiGR unifies generative and discriminative tasks effectively, paving the way for further advancements in the field.
AvatarGO: Zero-shot 4D Human-Object Interaction Generation and Animation
Oct 09, 2024



Recent advancements in diffusion models have led to significant improvements in the generation and animation of 4D full-body human-object interactions (HOI). Nevertheless, existing methods primarily focus on SMPL-based motion generation, which is limited by the scarcity of realistic large-scale interaction data. This constraint affects their ability to create everyday HOI scenes. This paper addresses this challenge using a zero-shot approach with a pre-trained diffusion model. Despite this potential, achieving our goals is difficult due to the diffusion model's lack of understanding of ''where'' and ''how'' objects interact with the human body. To tackle these issues, we introduce AvatarGO, a novel framework designed to generate animatable 4D HOI scenes directly from textual inputs. Specifically, 1) for the ''where'' challenge, we propose LLM-guided contact retargeting, which employs Lang-SAM to identify the contact body part from text prompts, ensuring precise representation of human-object spatial relations. 2) For the ''how'' challenge, we introduce correspondence-aware motion optimization that constructs motion fields for both human and object models using the linear blend skinning function from SMPL-X. Our framework not only generates coherent compositional motions, but also exhibits greater robustness in handling penetration issues. Extensive experiments with existing methods validate AvatarGO's superior generation and animation capabilities on a variety of human-object pairs and diverse poses. As the first attempt to synthesize 4D avatars with object interactions, we hope AvatarGO could open new doors for human-centric 4D content creation.
ArtiFade: Learning to Generate High-quality Subject from Blemished Images
Sep 05, 2024

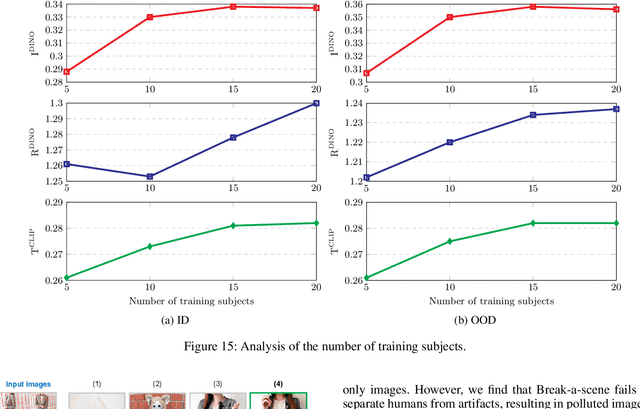
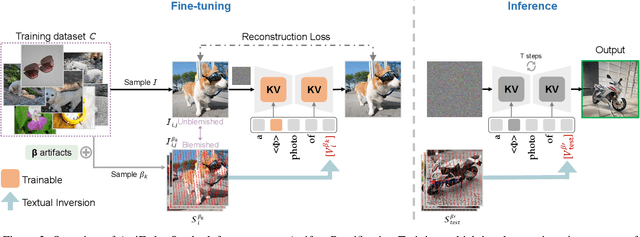
Subject-driven text-to-image generation has witnessed remarkable advancements in its ability to learn and capture characteristics of a subject using only a limited number of images. However, existing methods commonly rely on high-quality images for training and may struggle to generate reasonable images when the input images are blemished by artifacts. This is primarily attributed to the inadequate capability of current techniques in distinguishing subject-related features from disruptive artifacts. In this paper, we introduce ArtiFade to tackle this issue and successfully generate high-quality artifact-free images from blemished datasets. Specifically, ArtiFade exploits fine-tuning of a pre-trained text-to-image model, aiming to remove artifacts. The elimination of artifacts is achieved by utilizing a specialized dataset that encompasses both unblemished images and their corresponding blemished counterparts during fine-tuning. ArtiFade also ensures the preservation of the original generative capabilities inherent within the diffusion model, thereby enhancing the overall performance of subject-driven methods in generating high-quality and artifact-free images. We further devise evaluation benchmarks tailored for this task. Through extensive qualitative and quantitative experiments, we demonstrate the generalizability of ArtiFade in effective artifact removal under both in-distribution and out-of-distribution scenarios.
ConceptExpress: Harnessing Diffusion Models for Single-image Unsupervised Concept Extraction
Jul 09, 2024



While personalized text-to-image generation has enabled the learning of a single concept from multiple images, a more practical yet challenging scenario involves learning multiple concepts within a single image. However, existing works tackling this scenario heavily rely on extensive human annotations. In this paper, we introduce a novel task named Unsupervised Concept Extraction (UCE) that considers an unsupervised setting without any human knowledge of the concepts. Given an image that contains multiple concepts, the task aims to extract and recreate individual concepts solely relying on the existing knowledge from pretrained diffusion models. To achieve this, we present ConceptExpress that tackles UCE by unleashing the inherent capabilities of pretrained diffusion models in two aspects. Specifically, a concept localization approach automatically locates and disentangles salient concepts by leveraging spatial correspondence from diffusion self-attention; and based on the lookup association between a concept and a conceptual token, a concept-wise optimization process learns discriminative tokens that represent each individual concept. Finally, we establish an evaluation protocol tailored for the UCE task. Extensive experiments demonstrate that ConceptExpress is a promising solution to the UCE task. Our code and data are available at: https://github.com/haoosz/ConceptExpress