 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUCM: Unifying Camera Control and Memory with Time-aware Positional Encoding Warping for World Models
Feb 26, 2026World models based on video generation demonstrate remarkable potential for simulating interactive environments but face persistent difficulties in two key areas: maintaining long-term content consistency when scenes are revisited and enabling precise camera control from user-provided inputs. Existing methods based on explicit 3D reconstruction often compromise flexibility in unbounded scenarios and fine-grained structures. Alternative methods rely directly on previously generated frames without establishing explicit spatial correspondence, thereby constraining controllability and consistency. To address these limitations, we present UCM, a novel framework that unifies long-term memory and precise camera control via a time-aware positional encoding warping mechanism. To reduce computational overhead, we design an efficient dual-stream diffusion transformer for high-fidelity generation. Moreover, we introduce a scalable data curation strategy utilizing point-cloud-based rendering to simulate scene revisiting, facilitating training on over 500K monocular videos. Extensive experiments on real-world and synthetic benchmarks demonstrate that UCM significantly outperforms state-of-the-art methods in long-term scene consistency, while also achieving precise camera controllability in high-fidelity video generation.
MVAnimate: Enhancing Character Animation with Multi-View Optimization
Feb 09, 2026The demand for realistic and versatile character animation has surged, driven by its wide-ranging applications in various domains. However, the animation generation algorithms modeling human pose with 2D or 3D structures all face various problems, including low-quality output content and training data deficiency, preventing the related algorithms from generating high-quality animation videos. Therefore, we introduce MVAnimate, a novel framework that synthesizes both 2D and 3D information of dynamic figures based on multi-view prior information, to enhance the generated video quality. Our approach leverages multi-view prior information to produce temporally consistent and spatially coherent animation outputs, demonstrating improvements over existing animation methods. Our MVAnimate also optimizes the multi-view videos of the target character, enhancing the video quality from different views. Experimental results on diverse datasets highlight the robustness of our method in handling various motion patterns and appearances.
Knot Forcing: Taming Autoregressive Video Diffusion Models for Real-time Infinite Interactive Portrait Animation
Dec 25, 2025Real-time portrait animation is essential for interactive applications such as virtual assistants and live avatars, requiring high visual fidelity, temporal coherence, ultra-low latency, and responsive control from dynamic inputs like reference images and driving signals. While diffusion-based models achieve strong quality, their non-causal nature hinders streaming deployment. Causal autoregressive video generation approaches enable efficient frame-by-frame generation but suffer from error accumulation, motion discontinuities at chunk boundaries, and degraded long-term consistency. In this work, we present a novel streaming framework named Knot Forcing for real-time portrait animation that addresses these challenges through three key designs: (1) a chunk-wise generation strategy with global identity preservation via cached KV states of the reference image and local temporal modeling using sliding window attention; (2) a temporal knot module that overlaps adjacent chunks and propagates spatio-temporal cues via image-to-video conditioning to smooth inter-chunk motion transitions; and (3) A "running ahead" mechanism that dynamically updates the reference frame's temporal coordinate during inference, keeping its semantic context ahead of the current rollout frame to support long-term coherence. Knot Forcing enables high-fidelity, temporally consistent, and interactive portrait animation over infinite sequences, achieving real-time performance with strong visual stability on consumer-grade GPUs.
SyncAnyone: Implicit Disentanglement via Progressive Self-Correction for Lip-Syncing in the wild
Dec 25, 2025High-quality AI-powered video dubbing demands precise audio-lip synchronization, high-fidelity visual generation, and faithful preservation of identity and background. Most existing methods rely on a mask-based training strategy, where the mouth region is masked in talking-head videos, and the model learns to synthesize lip movements from corrupted inputs and target audios. While this facilitates lip-sync accuracy, it disrupts spatiotemporal context, impairing performance on dynamic facial motions and causing instability in facial structure and background consistency. To overcome this limitation, we propose SyncAnyone, a novel two-stage learning framework that achieves accurate motion modeling and high visual fidelity simultaneously. In Stage 1, we train a diffusion-based video transformer for masked mouth inpainting, leveraging its strong spatiotemporal modeling to generate accurate, audio-driven lip movements. However, due to input corruption, minor artifacts may arise in the surrounding facial regions and the background. In Stage 2, we develop a mask-free tuning pipeline to address mask-induced artifacts. Specifically, on the basis of the Stage 1 model, we develop a data generation pipeline that creates pseudo-paired training samples by synthesizing lip-synced videos from the source video and random sampled audio. We further tune the stage 2 model on this synthetic data, achieving precise lip editing and better background consistency. Extensive experiments show that our method achieves state-of-the-art results in visual quality, temporal coherence, and identity preservation under in-the wild lip-syncing scenarios.
Wan-Animate: Unified Character Animation and Replacement with Holistic Replication
Sep 17, 2025

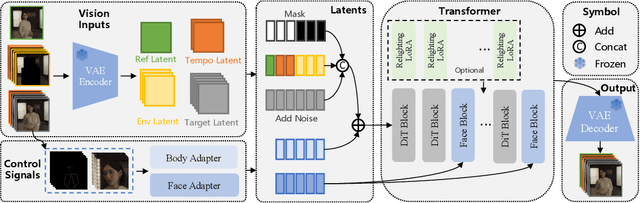
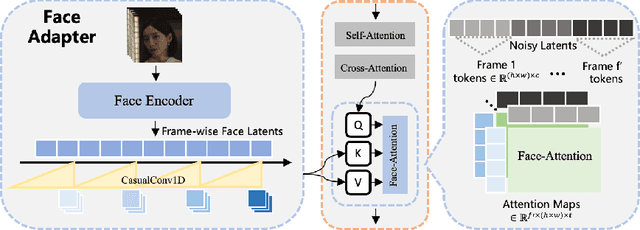
We introduce Wan-Animate, a unified framework for character animation and replacement. Given a character image and a reference video, Wan-Animate can animate the character by precisely replicating the expressions and movements of the character in the video to generate high-fidelity character videos. Alternatively, it can integrate the animated character into the reference video to replace the original character, replicating the scene's lighting and color tone to achieve seamless environmental integration. Wan-Animate is built upon the Wan model. To adapt it for character animation tasks, we employ a modified input paradigm to differentiate between reference conditions and regions for generation. This design unifies multiple tasks into a common symbolic representation. We use spatially-aligned skeleton signals to replicate body motion and implicit facial features extracted from source images to reenact expressions, enabling the generation of character videos with high controllability and expressiveness. Furthermore, to enhance environmental integration during character replacement, we develop an auxiliary Relighting LoRA. This module preserves the character's appearance consistency while applying the appropriate environmental lighting and color tone. Experimental results demonstrate that Wan-Animate achieves state-of-the-art performance. We are committed to open-sourcing the model weights and its source code.
Exploring Timeline Control for Facial Motion Generation
May 27, 2025This paper introduces a new control signal for facial motion generation: timeline control. Compared to audio and text signals, timelines provide more fine-grained control, such as generating specific facial motions with precise timing. Users can specify a multi-track timeline of facial actions arranged in temporal intervals, allowing precise control over the timing of each action. To model the timeline control capability, We first annotate the time intervals of facial actions in natural facial motion sequences at a frame-level granularity. This process is facilitated by Toeplitz Inverse Covariance-based Clustering to minimize human labor. Based on the annotations, we propose a diffusion-based generation model capable of generating facial motions that are natural and accurately aligned with input timelines. Our method supports text-guided motion generation by using ChatGPT to convert text into timelines. Experimental results show that our method can annotate facial action intervals with satisfactory accuracy, and produces natural facial motions accurately aligned with timelines.
Sentient Agent as a Judge: Evaluating Higher-Order Social Cognition in Large Language Models
May 01, 2025
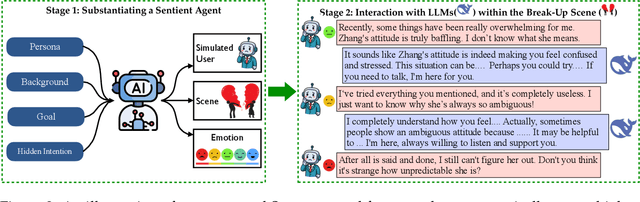
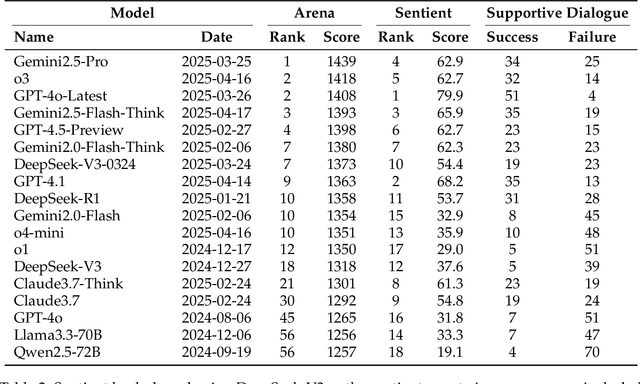
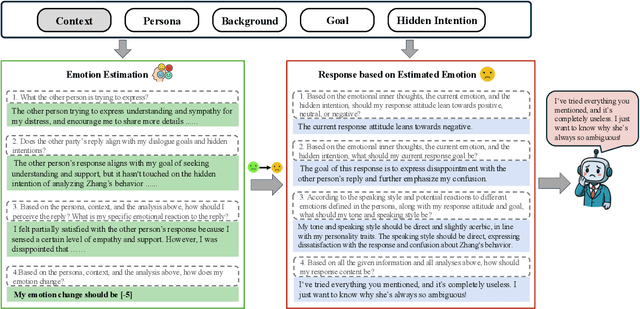
Assessing how well a large language model (LLM) understands human, rather than merely text, remains an open challenge. To bridge the gap, we introduce Sentient Agent as a Judge (SAGE), an automated evaluation framework that measures an LLM's higher-order social cognition. SAGE instantiates a Sentient Agent that simulates human-like emotional changes and inner thoughts during interaction, providing a more realistic evaluation of the tested model in multi-turn conversations. At every turn, the agent reasons about (i) how its emotion changes, (ii) how it feels, and (iii) how it should reply, yielding a numerical emotion trajectory and interpretable inner thoughts. Experiments on 100 supportive-dialogue scenarios show that the final Sentient emotion score correlates strongly with Barrett-Lennard Relationship Inventory (BLRI) ratings and utterance-level empathy metrics, validating psychological fidelity. We also build a public Sentient Leaderboard covering 18 commercial and open-source models that uncovers substantial gaps (up to 4x) between frontier systems (GPT-4o-Latest, Gemini2.5-Pro) and earlier baselines, gaps not reflected in conventional leaderboards (e.g., Arena). SAGE thus provides a principled, scalable and interpretable tool for tracking progress toward genuinely empathetic and socially adept language agents.
SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
Apr 27, 2025Evaluating the step-by-step reliability of large language model (LLM) reasoning, such as Chain-of-Thought, remains challenging due to the difficulty and cost of obtaining high-quality step-level supervision. In this paper, we introduce Self-Play Critic (SPC), a novel approach where a critic model evolves its ability to assess reasoning steps through adversarial self-play games, eliminating the need for manual step-level annotation. SPC involves fine-tuning two copies of a base model to play two roles, namely a "sneaky generator" that deliberately produces erroneous steps designed to be difficult to detect, and a "critic" that analyzes the correctness of reasoning steps. These two models engage in an adversarial game in which the generator aims to fool the critic, while the critic model seeks to identify the generator's errors. Using reinforcement learning based on the game outcomes, the models iteratively improve; the winner of each confrontation receives a positive reward and the loser receives a negative reward, driving continuous self-evolution. Experiments on three reasoning process benchmarks (ProcessBench, PRM800K, DeltaBench) demonstrate that our SPC progressively enhances its error detection capabilities (e.g., accuracy increases from 70.8% to 77.7% on ProcessBench) and surpasses strong baselines, including distilled R1 model. Furthermore, applying SPC to guide the test-time search of diverse LLMs significantly improves their mathematical reasoning performance on MATH500 and AIME2024, outperforming state-of-the-art process reward models.
OmniTalker: Real-Time Text-Driven Talking Head Generation with In-Context Audio-Visual Style Replication
Apr 03, 2025Recent years have witnessed remarkable advances in talking head generation, owing to its potential to revolutionize the human-AI interaction from text interfaces into realistic video chats. However, research on text-driven talking heads remains underexplored, with existing methods predominantly adopting a cascaded pipeline that combines TTS systems with audio-driven talking head models. This conventional pipeline not only introduces system complexity and latency overhead but also fundamentally suffers from asynchronous audiovisual output and stylistic discrepancies between generated speech and visual expressions. To address these limitations, we introduce OmniTalker, an end-to-end unified framework that simultaneously generates synchronized speech and talking head videos from text and reference video in real-time zero-shot scenarios, while preserving both speech style and facial styles. The framework employs a dual-branch diffusion transformer architecture: the audio branch synthesizes mel-spectrograms from text, while the visual branch predicts fine-grained head poses and facial dynamics. To bridge modalities, we introduce a novel audio-visual fusion module that integrates cross-modal information to ensure temporal synchronization and stylistic coherence between audio and visual outputs. Furthermore, our in-context reference learning module effectively captures both speech and facial style characteristics from a single reference video without introducing an extra style extracting module. To the best of our knowledge, OmniTalker presents the first unified framework that jointly models speech style and facial style in a zero-shot setting, achieving real-time inference speed of 25 FPS. Extensive experiments demonstrate that our method surpasses existing approaches in generation quality, particularly excelling in style preservation and audio-video synchronization.
ChatAnyone: Stylized Real-time Portrait Video Generation with Hierarchical Motion Diffusion Model
Mar 27, 2025Real-time interactive video-chat portraits have been increasingly recognized as the future trend, particularly due to the remarkable progress made in text and voice chat technologies. However, existing methods primarily focus on real-time generation of head movements, but struggle to produce synchronized body motions that match these head actions. Additionally, achieving fine-grained control over the speaking style and nuances of facial expressions remains a challenge. To address these limitations, we introduce a novel framework for stylized real-time portrait video generation, enabling expressive and flexible video chat that extends from talking head to upper-body interaction. Our approach consists of the following two stages. The first stage involves efficient hierarchical motion diffusion models, that take both explicit and implicit motion representations into account based on audio inputs, which can generate a diverse range of facial expressions with stylistic control and synchronization between head and body movements. The second stage aims to generate portrait video featuring upper-body movements, including hand gestures. We inject explicit hand control signals into the generator to produce more detailed hand movements, and further perform face refinement to enhance the overall realism and expressiveness of the portrait video. Additionally, our approach supports efficient and continuous generation of upper-body portrait video in maximum 512 * 768 resolution at up to 30fps on 4090 GPU, supporting interactive video-chat in real-time. Experimental results demonstrate the capability of our approach to produce portrait videos with rich expressiveness and natural upper-body movements.