 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamAvatar: Streaming Diffusion Models for Real-Time Interactive Human Avatars
Dec 26, 2025Real-time, streaming interactive avatars represent a critical yet challenging goal in digital human research. Although diffusion-based human avatar generation methods achieve remarkable success, their non-causal architecture and high computational costs make them unsuitable for streaming. Moreover, existing interactive approaches are typically limited to head-and-shoulder region, limiting their ability to produce gestures and body motions. To address these challenges, we propose a two-stage autoregressive adaptation and acceleration framework that applies autoregressive distillation and adversarial refinement to adapt a high-fidelity human video diffusion model for real-time, interactive streaming. To ensure long-term stability and consistency, we introduce three key components: a Reference Sink, a Reference-Anchored Positional Re-encoding (RAPR) strategy, and a Consistency-Aware Discriminator. Building on this framework, we develop a one-shot, interactive, human avatar model capable of generating both natural talking and listening behaviors with coherent gestures. Extensive experiments demonstrate that our method achieves state-of-the-art performance, surpassing existing approaches in generation quality, real-time efficiency, and interaction naturalness. Project page: https://streamavatar.github.io .
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
HunyuanVideo-HOMA: Generic Human-Object Interaction in Multimodal Driven Human Animation
Jun 10, 2025To address key limitations in human-object interaction (HOI) video generation -- specifically the reliance on curated motion data, limited generalization to novel objects/scenarios, and restricted accessibility -- we introduce HunyuanVideo-HOMA, a weakly conditioned multimodal-driven framework. HunyuanVideo-HOMA enhances controllability and reduces dependency on precise inputs through sparse, decoupled motion guidance. It encodes appearance and motion signals into the dual input space of a multimodal diffusion transformer (MMDiT), fusing them within a shared context space to synthesize temporally consistent and physically plausible interactions. To optimize training, we integrate a parameter-space HOI adapter initialized from pretrained MMDiT weights, preserving prior knowledge while enabling efficient adaptation, and a facial cross-attention adapter for anatomically accurate audio-driven lip synchronization. Extensive experiments confirm state-of-the-art performance in interaction naturalness and generalization under weak supervision. Finally, HunyuanVideo-HOMA demonstrates versatility in text-conditioned generation and interactive object manipulation, supported by a user-friendly demo interface. The project page is at https://anonymous.4open.science/w/homa-page-0FBE/.
Exploring Timeline Control for Facial Motion Generation
May 27, 2025This paper introduces a new control signal for facial motion generation: timeline control. Compared to audio and text signals, timelines provide more fine-grained control, such as generating specific facial motions with precise timing. Users can specify a multi-track timeline of facial actions arranged in temporal intervals, allowing precise control over the timing of each action. To model the timeline control capability, We first annotate the time intervals of facial actions in natural facial motion sequences at a frame-level granularity. This process is facilitated by Toeplitz Inverse Covariance-based Clustering to minimize human labor. Based on the annotations, we propose a diffusion-based generation model capable of generating facial motions that are natural and accurately aligned with input timelines. Our method supports text-guided motion generation by using ChatGPT to convert text into timelines. Experimental results show that our method can annotate facial action intervals with satisfactory accuracy, and produces natural facial motions accurately aligned with timelines.
HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters
May 26, 2025Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. To address these challenges, we propose HunyuanVideo-Avatar, a multimodal diffusion transformer (MM-DiT)-based model capable of simultaneously generating dynamic, emotion-controllable, and multi-character dialogue videos. Concretely, HunyuanVideo-Avatar introduces three key innovations: (i) A character image injection module is designed to replace the conventional addition-based character conditioning scheme, eliminating the inherent condition mismatch between training and inference. This ensures the dynamic motion and strong character consistency; (ii) An Audio Emotion Module (AEM) is introduced to extract and transfer the emotional cues from an emotion reference image to the target generated video, enabling fine-grained and accurate emotion style control; (iii) A Face-Aware Audio Adapter (FAA) is proposed to isolate the audio-driven character with latent-level face mask, enabling independent audio injection via cross-attention for multi-character scenarios. These innovations empower HunyuanVideo-Avatar to surpass state-of-the-art methods on benchmark datasets and a newly proposed wild dataset, generating realistic avatars in dynamic, immersive scenarios.
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Sep 14, 2024



Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Aug 18, 2024
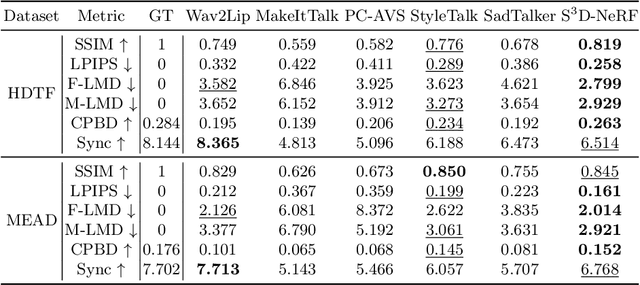
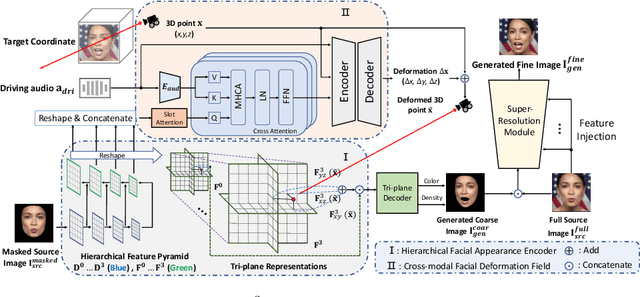
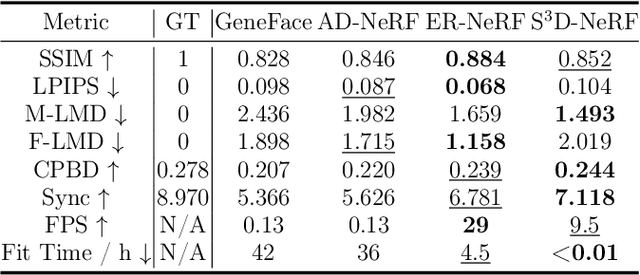
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models
Dec 15, 2023Diffusion models have shown remarkable success in a variety of downstream generative tasks, yet remain under-explored in the important and challenging expressive talking head generation. In this work, we propose a DreamTalk framework to fulfill this gap, which employs meticulous design to unlock the potential of diffusion models in generating expressive talking heads. Specifically, DreamTalk consists of three crucial components: a denoising network, a style-aware lip expert, and a style predictor. The diffusion-based denoising network is able to consistently synthesize high-quality audio-driven face motions across diverse expressions. To enhance the expressiveness and accuracy of lip motions, we introduce a style-aware lip expert that can guide lip-sync while being mindful of the speaking styles. To eliminate the need for expression reference video or text, an extra diffusion-based style predictor is utilized to predict the target expression directly from the audio. By this means, DreamTalk can harness powerful diffusion models to generate expressive faces effectively and reduce the reliance on expensive style references. Experimental results demonstrate that DreamTalk is capable of generating photo-realistic talking faces with diverse speaking styles and achieving accurate lip motions, surpassing existing state-of-the-art counterparts.
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Apr 01, 2023In order to produce facial-expression-specified talking head videos, previous audio-driven one-shot talking head methods need to use a reference video with a matching speaking style (i.e., facial expressions). However, finding videos with a desired style may not be easy, potentially restricting their application. In this work, we propose an expression-controllable one-shot talking head method, dubbed TalkCLIP, where the expression in a speech is specified by the natural language. This would significantly ease the difficulty of searching for a video with a desired speaking style. Here, we first construct a text-video paired talking head dataset, in which each video has alternative prompt-alike descriptions. Specifically, our descriptions involve coarse-level emotion annotations and facial action unit (AU) based fine-grained annotations. Then, we introduce a CLIP-based style encoder that first projects natural language descriptions to the CLIP text embedding space and then aligns the textual embeddings to the representations of speaking styles. As extensive textual knowledge has been encoded by CLIP, our method can even generalize to infer a speaking style whose description has not been seen during training. Extensive experiments demonstrate that our method achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles
Jan 03, 2023



Different people speak with diverse personalized speaking styles. Although existing one-shot talking head methods have made significant progress in lip sync, natural facial expressions, and stable head motions, they still cannot generate diverse speaking styles in the final talking head videos. To tackle this problem, we propose a one-shot style-controllable talking face generation framework. In a nutshell, we aim to attain a speaking style from an arbitrary reference speaking video and then drive the one-shot portrait to speak with the reference speaking style and another piece of audio. Specifically, we first develop a style encoder to extract dynamic facial motion patterns of a style reference video and then encode them into a style code. Afterward, we introduce a style-controllable decoder to synthesize stylized facial animations from the speech content and style code. In order to integrate the reference speaking style into generated videos, we design a style-aware adaptive transformer, which enables the encoded style code to adjust the weights of the feed-forward layers accordingly. Thanks to the style-aware adaptation mechanism, the reference speaking style can be better embedded into synthesized videos during decoding. Extensive experiments demonstrate that our method is capable of generating talking head videos with diverse speaking styles from only one portrait image and an audio clip while achieving authentic visual effects. Project Page: https://github.com/FuxiVirtualHuman/styletalk.