 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Aug 18, 2024
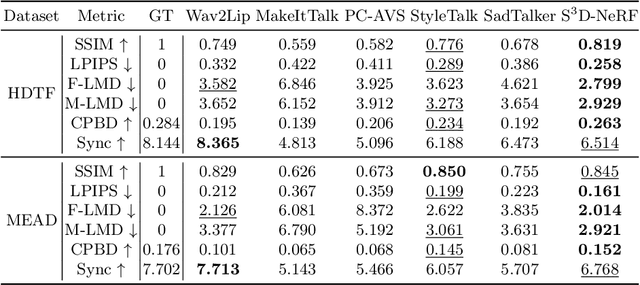
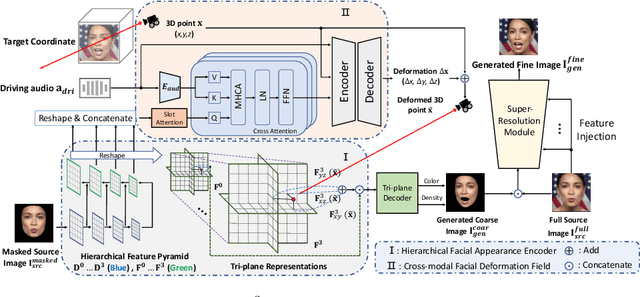
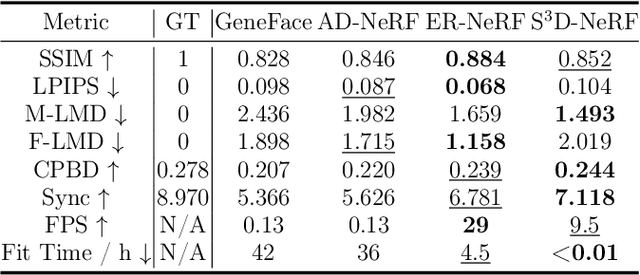
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis
Jun 12, 2024



Testing is a major approach to ensuring the quality of deep learning (DL) libraries. Existing testing techniques commonly adopt differential testing to relieve the need for test oracle construction. However, these techniques are limited in finding implementations that offer the same functionality and generating diverse test inputs for differential testing. This paper introduces DLLens, a novel differential testing technique for DL library testing. Our insight is that APIs in different DL libraries are commonly designed to accomplish various computations for the same set of published DL algorithms. Although the mapping of these APIs is not often one-to-one, we observe that their computations can be mutually simulated after proper composition and adaptation. The use of these simulation counterparts facilitates differential testing for the detection of functional DL library bugs. Leveraging the insight, we propose DLLens as a novel mechanism that utilizes a large language model (LLM) to synthesize valid counterparts of DL library APIs. To generate diverse test inputs, DLLens incorporates a static analysis method aided by LLM to extract path constraints from all execution paths in each API and its counterpart's implementations. These path constraints are then used to guide the generation of diverse test inputs. We evaluate DLLens on two popular DL libraries, TensorFlow and PyTorch. Our evaluation shows that DLLens can synthesize counterparts for more than twice as many APIs found by state-of-the-art techniques on these libraries. Moreover, DLLens can extract 26.7% more constraints and detect 2.5 times as many bugs as state-of-the-art techniques. DLLens has successfully found 56 bugs in recent TensorFlow and PyTorch libraries. Among them, 41 are previously unknown, 39 of which have been confirmed by developers after reporting, and 19 of those confirmed bugs have been fixed by developers.
AE-NeRF: Audio Enhanced Neural Radiance Field for Few Shot Talking Head Synthesis
Dec 18, 2023

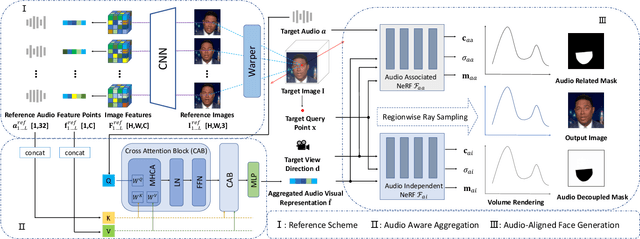

Audio-driven talking head synthesis is a promising topic with wide applications in digital human, film making and virtual reality. Recent NeRF-based approaches have shown superiority in quality and fidelity compared to previous studies. However, when it comes to few-shot talking head generation, a practical scenario where only few seconds of talking video is available for one identity, two limitations emerge: 1) they either have no base model, which serves as a facial prior for fast convergence, or ignore the importance of audio when building the prior; 2) most of them overlook the degree of correlation between different face regions and audio, e.g., mouth is audio related, while ear is audio independent. In this paper, we present Audio Enhanced Neural Radiance Field (AE-NeRF) to tackle the above issues, which can generate realistic portraits of a new speaker with fewshot dataset. Specifically, we introduce an Audio Aware Aggregation module into the feature fusion stage of the reference scheme, where the weight is determined by the similarity of audio between reference and target image. Then, an Audio-Aligned Face Generation strategy is proposed to model the audio related and audio independent regions respectively, with a dual-NeRF framework. Extensive experiments have shown AE-NeRF surpasses the state-of-the-art on image fidelity, audio-lip synchronization, and generalization ability, even in limited training set or training iterations.
RiDDLE: Reversible and Diversified De-identification with Latent Encryptor
Mar 18, 2023
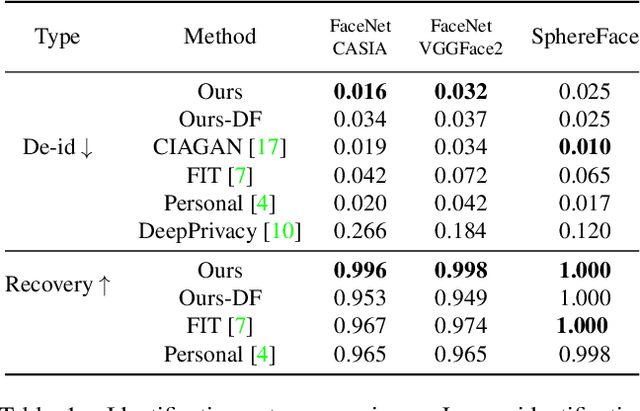
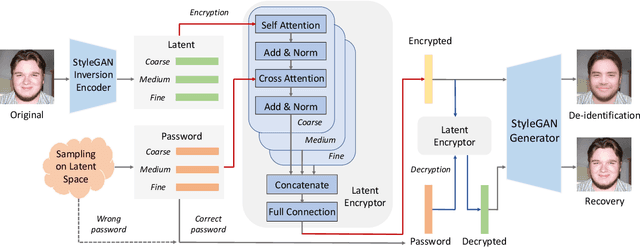
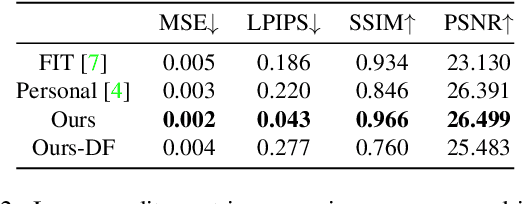
This work presents RiDDLE, short for Reversible and Diversified De-identification with Latent Encryptor, to protect the identity information of people from being misused. Built upon a pre-learned StyleGAN2 generator, RiDDLE manages to encrypt and decrypt the facial identity within the latent space. The design of RiDDLE has three appealing properties. First, the encryption process is cipher-guided and hence allows diverse anonymization using different passwords. Second, the true identity can only be decrypted with the correct password, otherwise the system will produce another de-identified face to maintain the privacy. Third, both encryption and decryption share an efficient implementation, benefiting from a carefully tailored lightweight encryptor. Comparisons with existing alternatives confirm that our approach accomplishes the de-identification task with better quality, higher diversity, and stronger reversibility. We further demonstrate the effectiveness of RiDDLE in anonymizing videos. Code and models will be made publicly available.
Face Anonymization by Manipulating Decoupled Identity Representation
May 24, 2021

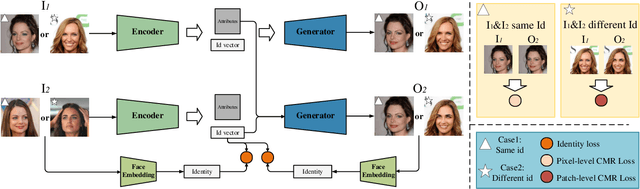

Privacy protection on human biological information has drawn increasing attention in recent years, among which face anonymization plays an importance role. We propose a novel approach which protects identity information of facial images from leakage with slightest modification. Specifically, we disentangle identity representation from other facial attributes leveraging the power of generative adversarial networks trained on a conditional multi-scale reconstruction (CMR) loss and an identity loss. We evaulate the disentangle ability of our model, and propose an effective method for identity anonymization, namely Anonymous Identity Generation (AIG), to reach the goal of face anonymization meanwhile maintaining similarity to the original image as much as possible. Quantitative and qualitative results demonstrate our method's superiority compared with the SOTAs on both visual quality and anonymization success rate.
Exploring Adversarial Fake Images on Face Manifold
Jan 09, 2021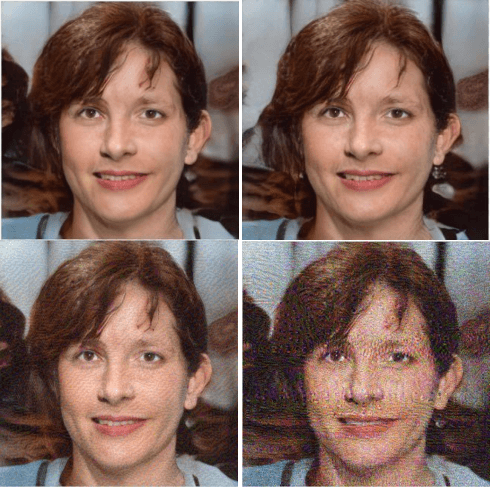
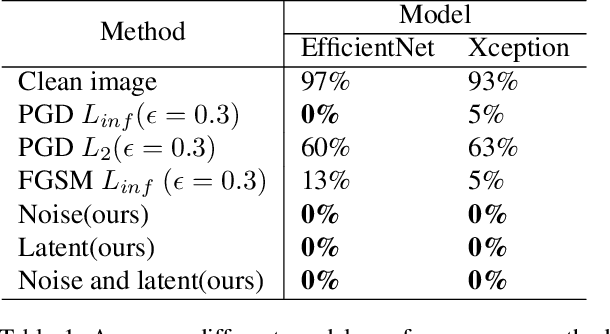
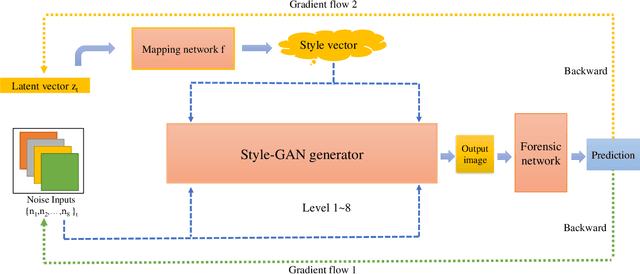
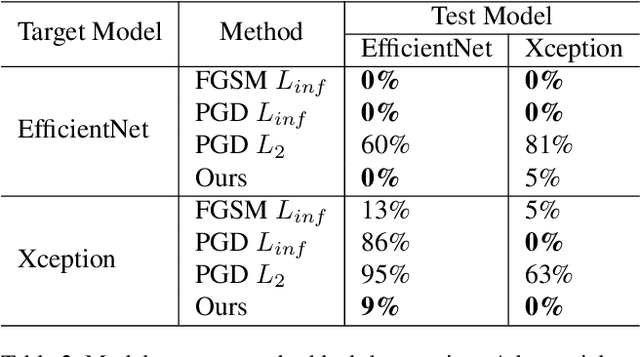
Images synthesized by powerful generative adversarial network (GAN) based methods have drawn moral and privacy concerns. Although image forensic models have reached great performance in detecting fake images from real ones, these models can be easily fooled with a simple adversarial attack. But, the noise adding adversarial samples are also arousing suspicion. In this paper, instead of adding adversarial noise, we optimally search adversarial points on face manifold to generate anti-forensic fake face images. We iteratively do a gradient-descent with each small step in the latent space of a generative model, e.g. Style-GAN, to find an adversarial latent vector, which is similar to norm-based adversarial attack but in latent space. Then, the generated fake images driven by the adversarial latent vectors with the help of GANs can defeat main-stream forensic models. For examples, they make the accuracy of deepfake detection models based on Xception or EfficientNet drop from over 90% to nearly 0%, meanwhile maintaining high visual quality. In addition, we find manipulating style vector $z$ or noise vectors $n$ at different levels have impacts on attack success rate. The generated adversarial images mainly have facial texture or face attributes changing.