 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Bugs in Data Visualization Libraries
Jun 18, 2025Data visualization (DataViz) libraries play a crucial role in presentation, data analysis, and application development, underscoring the importance of their accuracy in transforming data into visual representations. Incorrect visualizations can adversely impact user experience, distort information conveyance, and influence user perception and decision-making processes. Visual bugs in these libraries can be particularly insidious as they may not cause obvious errors like crashes, but instead mislead users of the underlying data graphically, resulting in wrong decision making. Consequently, a good understanding of the unique characteristics of bugs in DataViz libraries is essential for researchers and developers to detect and fix bugs in DataViz libraries. This study presents the first comprehensive analysis of bugs in DataViz libraries, examining 564 bugs collected from five widely-used libraries. Our study systematically analyzes their symptoms and root causes, and provides a detailed taxonomy. We found that incorrect/inaccurate plots are pervasive in DataViz libraries and incorrect graphic computation is the major root cause, which necessitates further automated testing methods for DataViz libraries. Moreover, we identified eight key steps to trigger such bugs and two test oracles specific to DataViz libraries, which may inspire future research in designing effective automated testing techniques. Furthermore, with the recent advancements in Vision Language Models (VLMs), we explored the feasibility of applying these models to detect incorrect/inaccurate plots. The results show that the effectiveness of VLMs in bug detection varies from 29% to 57%, depending on the prompts, and adding more information in prompts does not necessarily increase the effectiveness. More findings can be found in our manuscript.
DLLens: Testing Deep Learning Libraries via LLM-aided Synthesis
Jun 12, 2024



Testing is a major approach to ensuring the quality of deep learning (DL) libraries. Existing testing techniques commonly adopt differential testing to relieve the need for test oracle construction. However, these techniques are limited in finding implementations that offer the same functionality and generating diverse test inputs for differential testing. This paper introduces DLLens, a novel differential testing technique for DL library testing. Our insight is that APIs in different DL libraries are commonly designed to accomplish various computations for the same set of published DL algorithms. Although the mapping of these APIs is not often one-to-one, we observe that their computations can be mutually simulated after proper composition and adaptation. The use of these simulation counterparts facilitates differential testing for the detection of functional DL library bugs. Leveraging the insight, we propose DLLens as a novel mechanism that utilizes a large language model (LLM) to synthesize valid counterparts of DL library APIs. To generate diverse test inputs, DLLens incorporates a static analysis method aided by LLM to extract path constraints from all execution paths in each API and its counterpart's implementations. These path constraints are then used to guide the generation of diverse test inputs. We evaluate DLLens on two popular DL libraries, TensorFlow and PyTorch. Our evaluation shows that DLLens can synthesize counterparts for more than twice as many APIs found by state-of-the-art techniques on these libraries. Moreover, DLLens can extract 26.7% more constraints and detect 2.5 times as many bugs as state-of-the-art techniques. DLLens has successfully found 56 bugs in recent TensorFlow and PyTorch libraries. Among them, 41 are previously unknown, 39 of which have been confirmed by developers after reporting, and 19 of those confirmed bugs have been fixed by developers.
MEMO: Coverage-guided Model Generation For Deep Learning Library Testing
Aug 02, 2022
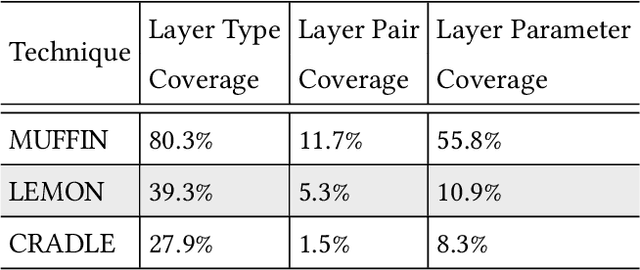
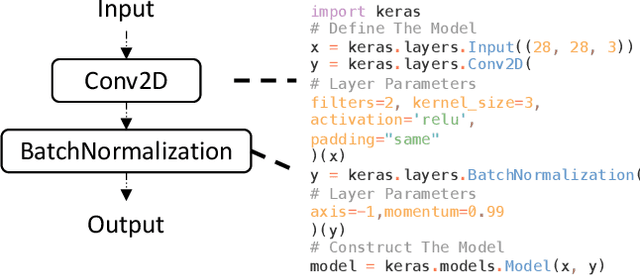
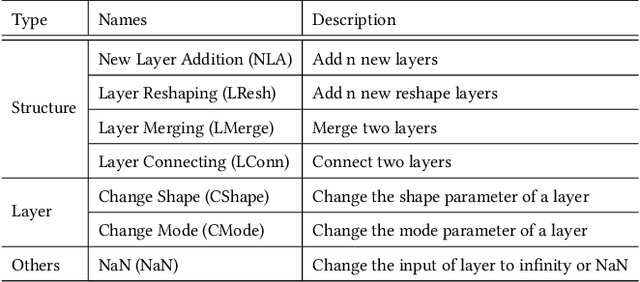
Recent deep learning (DL) applications are mostly built on top of DL libraries. The quality assurance of these libraries is critical to the dependable deployment of DL applications. A few techniques have thereby been proposed to test DL libraries by generating DL models as test inputs. Then these techniques feed those DL models to DL libraries for making inferences, in order to exercise DL libraries modules related to a DL model's execution. However, the test effectiveness of these techniques is constrained by the diversity of generated DL models. Our investigation finds that these techniques can cover at most 11.7% of layer pairs (i.e., call sequence between two layer APIs) and 55.8% of layer parameters (e.g., "padding" in Conv2D). As a result, we find that many bugs arising from specific layer pairs and parameters can be missed by existing techniques. In view of the limitations of existing DL library testing techniques, we propose MEMO to efficiently generate diverse DL models by exploring layer types, layer pairs, and layer parameters. MEMO: (1) designs an initial model reduction technique to boost test efficiency without compromising model diversity; and (2) designs a set of mutation operators for a customized Markov Chain Monte Carlo (MCMC) algorithm to explore new layer types, layer pairs, and layer parameters. We evaluate MEMO on seven popular DL libraries, including four for model execution (TensorFlow, PyTorch and MXNet, and ONNX) and three for model conversions (Keras-MXNet, TF2ONNX, ONNX2PyTorch). The evaluation result shows that MEMO outperforms recent works by covering 10.3% more layer pairs, 15.3% more layer parameters, and 2.3% library branches. Moreover, MEMO detects 29 new bugs in the latest version of DL libraries, with 17 of them confirmed by DL library developers, and 5 of those confirmed bugs have been fixed.
DeepFD: Automated Fault Diagnosis and Localization for Deep Learning Programs
May 04, 2022
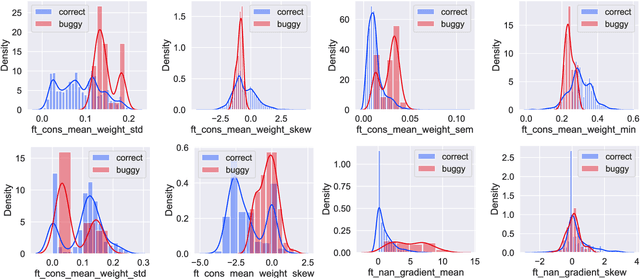

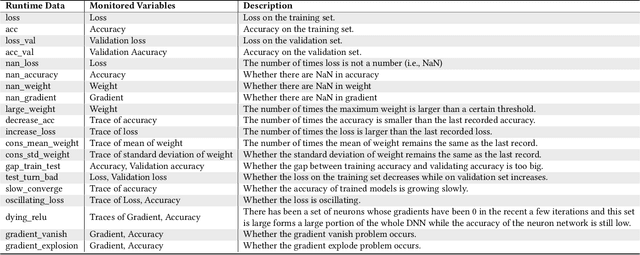
As Deep Learning (DL) systems are widely deployed for mission-critical applications, debugging such systems becomes essential. Most existing works identify and repair suspicious neurons on the trained Deep Neural Network (DNN), which, unfortunately, might be a detour. Specifically, several existing studies have reported that many unsatisfactory behaviors are actually originated from the faults residing in DL programs. Besides, locating faulty neurons is not actionable for developers, while locating the faulty statements in DL programs can provide developers with more useful information for debugging. Though a few recent studies were proposed to pinpoint the faulty statements in DL programs or the training settings (e.g. too large learning rate), they were mainly designed based on predefined rules, leading to many false alarms or false negatives, especially when the faults are beyond their capabilities. In view of these limitations, in this paper, we proposed DeepFD, a learning-based fault diagnosis and localization framework which maps the fault localization task to a learning problem. In particular, it infers the suspicious fault types via monitoring the runtime features extracted during DNN model training and then locates the diagnosed faults in DL programs. It overcomes the limitations by identifying the root causes of faults in DL programs instead of neurons and diagnosing the faults by a learning approach instead of a set of hard-coded rules. The evaluation exhibits the potential of DeepFD. It correctly diagnoses 52% faulty DL programs, compared with around half (27%) achieved by the best state-of-the-art works. Besides, for fault localization, DeepFD also outperforms the existing works, correctly locating 42% faulty programs, which almost doubles the best result (23%) achieved by the existing works.
Fast Test Input Generation for Finding Deviated Behaviors in Compressed Deep Neural Network
Dec 06, 2021
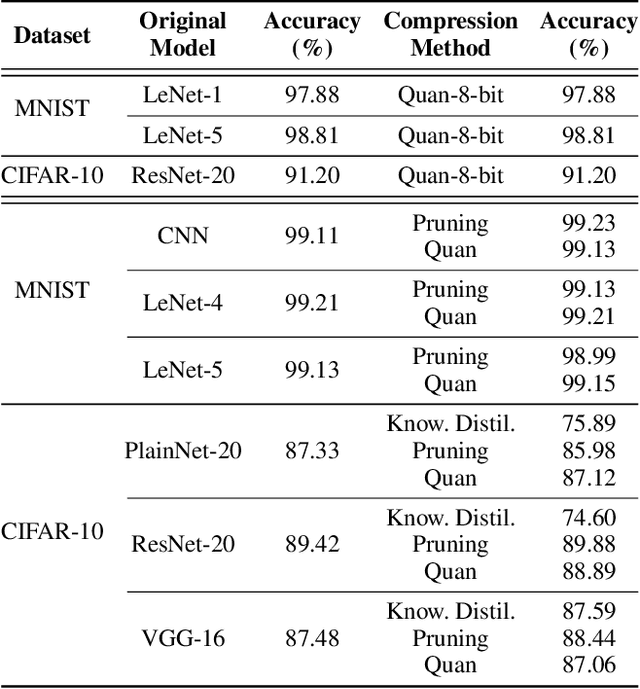
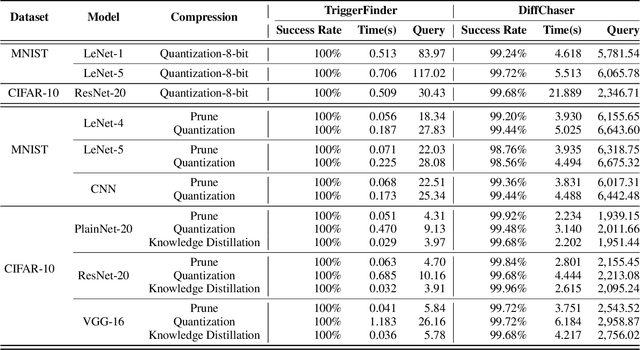
Model compression can significantly reduce sizes of deep neural network (DNN) models so that large, sophisticated models after compression can be deployed on resource-limited mobile and IoT devices. However, model compression often introduces deviated behaviors into a compressed model: the original and compressed models output different prediction results for the same input. Hence, it is critical to warn developers and help them comprehensively evaluate possible consequences of such behaviors before deployment. To this end, we propose TriggerFinder, a novel, effective and efficient testing approach to automatically identifying inputs to trigger deviated behaviors in compressed models. Given an input i as a seed, TriggerFinder iteratively applies a series of mutation operations to change i until the resulting input triggers a deviated behavior. However, compressed models usually hide their architecture and gradient information; without such internal information as guidance, it becomes difficult to effectively and efficiently trigger deviated behaviors. To tackle this challenge, we propose a novel fitness function to determine the mutated input that is closer to the inputs that can trigger the deviated predictions. Furthermore, TriggerFinder models this search problem as a Markov Chain process and leverages the Metropolis-Hasting algorithm to guide the selection of mutation operators. We evaluated TriggerFinder on 18 compressed models with two datasets. The experiment results demonstrate that TriggerFinder can successfully find triggering inputs for all seed inputs while the baseline fails in certain cases. As for efficiency, TriggerFinder is 5.2x-115.8x as fast as the baselines. Furthermore, the queries required by TriggerFinder to find one triggering input is only 51.8x-535.6x as small as the baseline.
Testing Deep Learning Models for Image Analysis Using Object-Relevant Metamorphic Relations
Sep 06, 2019
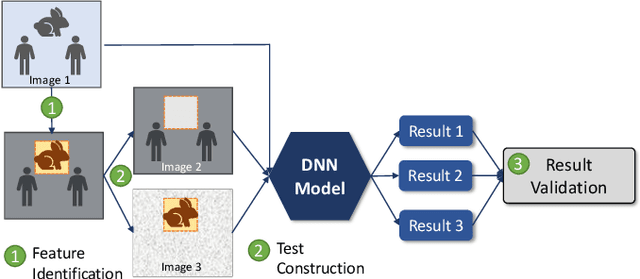
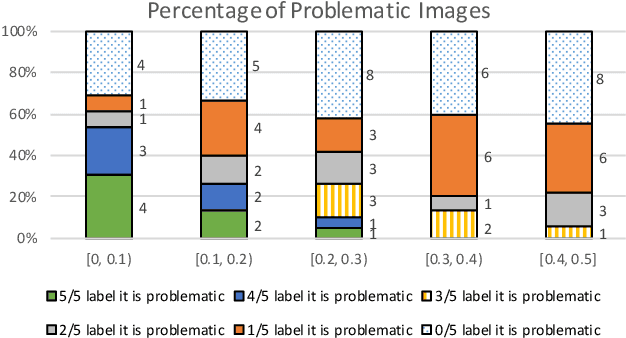
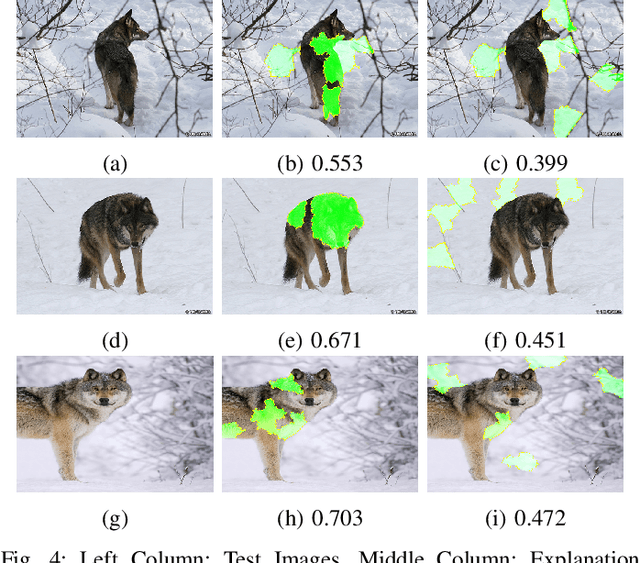
Deep learning models are widely used for image analysis. While they offer high performance in terms of accuracy, people are concerned about if these models inappropriately make inferences using irrelevant features that are not encoded from the target object in a given image. To address the concern, we propose a metamorphic testing approach that assesses if a given inference is made based on irrelevant features. Specifically, we propose two novel metamorphic relations to detect such inappropriate inferences. We applied our approach to 10 image classification models and 10 object detection models, with three large datasets, i.e., ImageNet, COCO, and Pascal VOC. Over 5.3% of the top-5 correct predictions made by the image classification models are subject to inappropriate inferences using irrelevant features. The corresponding rate for the object detection models is over 8.5%. Based on the findings, we further designed a new image generation strategy that can effectively attack existing models. Comparing with a baseline approach, our strategy can double the success rate of attacks.