 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Bugs in Data Visualization Libraries
Jun 18, 2025Data visualization (DataViz) libraries play a crucial role in presentation, data analysis, and application development, underscoring the importance of their accuracy in transforming data into visual representations. Incorrect visualizations can adversely impact user experience, distort information conveyance, and influence user perception and decision-making processes. Visual bugs in these libraries can be particularly insidious as they may not cause obvious errors like crashes, but instead mislead users of the underlying data graphically, resulting in wrong decision making. Consequently, a good understanding of the unique characteristics of bugs in DataViz libraries is essential for researchers and developers to detect and fix bugs in DataViz libraries. This study presents the first comprehensive analysis of bugs in DataViz libraries, examining 564 bugs collected from five widely-used libraries. Our study systematically analyzes their symptoms and root causes, and provides a detailed taxonomy. We found that incorrect/inaccurate plots are pervasive in DataViz libraries and incorrect graphic computation is the major root cause, which necessitates further automated testing methods for DataViz libraries. Moreover, we identified eight key steps to trigger such bugs and two test oracles specific to DataViz libraries, which may inspire future research in designing effective automated testing techniques. Furthermore, with the recent advancements in Vision Language Models (VLMs), we explored the feasibility of applying these models to detect incorrect/inaccurate plots. The results show that the effectiveness of VLMs in bug detection varies from 29% to 57%, depending on the prompts, and adding more information in prompts does not necessarily increase the effectiveness. More findings can be found in our manuscript.
EDAssistant: Supporting Exploratory Data Analysis in Computational Notebooks with In-Situ Code Search and Recommendation
Dec 15, 2021
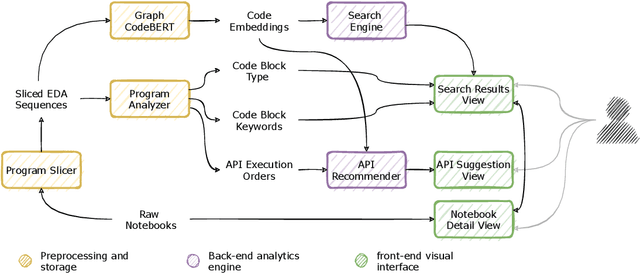
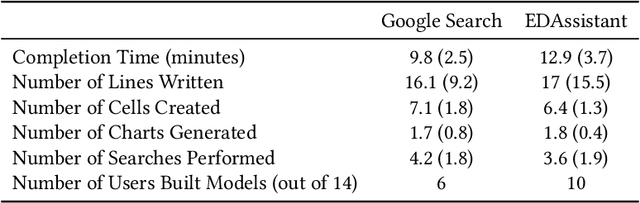
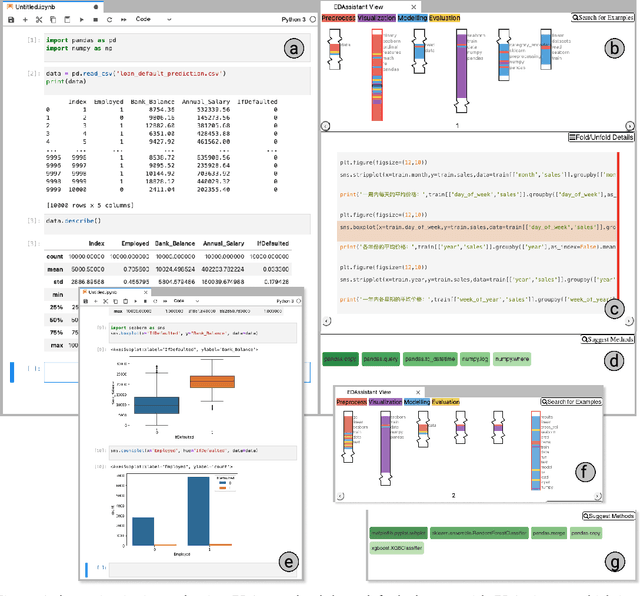
Using computational notebooks (e.g., Jupyter Notebook), data scientists rationalize their exploratory data analysis (EDA) based on their prior experience and external knowledge such as online examples. For novices or data scientists who lack specific knowledge about the dataset or problem to investigate, effectively obtaining and understanding the external information is critical to carry out EDA. This paper presents EDAssistant, a JupyterLab extension that supports EDA with in-situ search of example notebooks and recommendation of useful APIs, powered by novel interactive visualization of search results. The code search and recommendation are enabled by state-of-the-art machine learning models, trained on a large corpus of EDA notebooks collected online. A user study is conducted to investigate both EDAssistant and data scientists' current practice (i.e., using external search engines). The results demonstrate the effectiveness and usefulness of EDAssistant, and participants appreciated its smooth and in-context support of EDA. We also report several design implications regarding code recommendation tools.
Fast Test Input Generation for Finding Deviated Behaviors in Compressed Deep Neural Network
Dec 06, 2021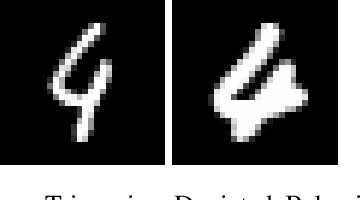
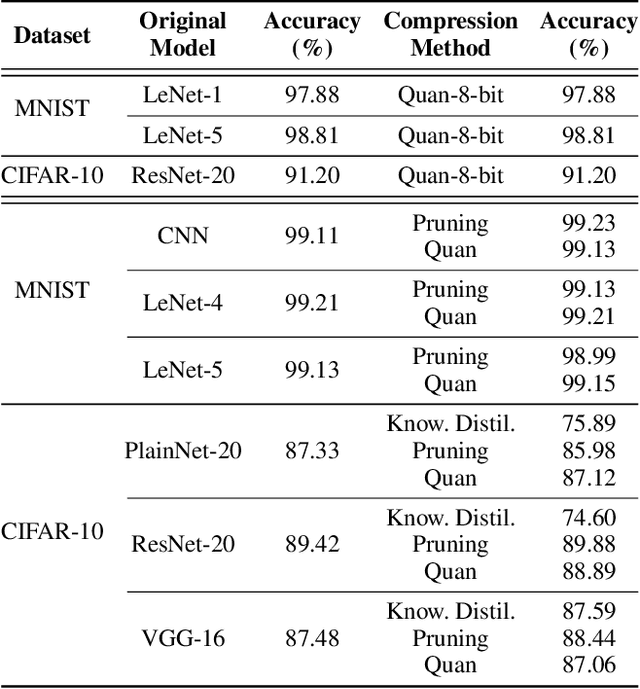
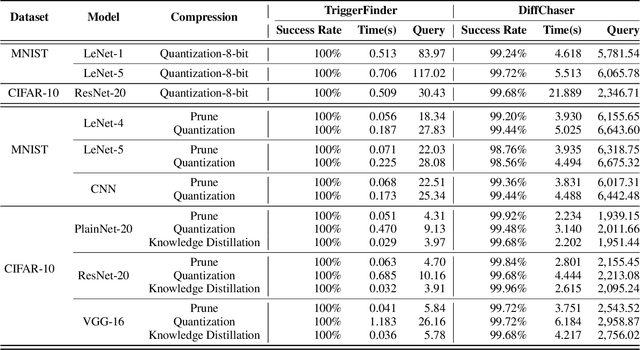
Model compression can significantly reduce sizes of deep neural network (DNN) models so that large, sophisticated models after compression can be deployed on resource-limited mobile and IoT devices. However, model compression often introduces deviated behaviors into a compressed model: the original and compressed models output different prediction results for the same input. Hence, it is critical to warn developers and help them comprehensively evaluate possible consequences of such behaviors before deployment. To this end, we propose TriggerFinder, a novel, effective and efficient testing approach to automatically identifying inputs to trigger deviated behaviors in compressed models. Given an input i as a seed, TriggerFinder iteratively applies a series of mutation operations to change i until the resulting input triggers a deviated behavior. However, compressed models usually hide their architecture and gradient information; without such internal information as guidance, it becomes difficult to effectively and efficiently trigger deviated behaviors. To tackle this challenge, we propose a novel fitness function to determine the mutated input that is closer to the inputs that can trigger the deviated predictions. Furthermore, TriggerFinder models this search problem as a Markov Chain process and leverages the Metropolis-Hasting algorithm to guide the selection of mutation operators. We evaluated TriggerFinder on 18 compressed models with two datasets. The experiment results demonstrate that TriggerFinder can successfully find triggering inputs for all seed inputs while the baseline fails in certain cases. As for efficiency, TriggerFinder is 5.2x-115.8x as fast as the baselines. Furthermore, the queries required by TriggerFinder to find one triggering input is only 51.8x-535.6x as small as the baseline.