 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Symbols, Big Risks: Exploring Emoticon Semantic Confusion in Large Language Models
Jan 12, 2026Emoticons are widely used in digital communication to convey affective intent, yet their safety implications for Large Language Models (LLMs) remain largely unexplored. In this paper, we identify emoticon semantic confusion, a vulnerability where LLMs misinterpret ASCII-based emoticons to perform unintended and even destructive actions. To systematically study this phenomenon, we develop an automated data generation pipeline and construct a dataset containing 3,757 code-oriented test cases spanning 21 meta-scenarios, four programming languages, and varying contextual complexities. Our study on six LLMs reveals that emoticon semantic confusion is pervasive, with an average confusion ratio exceeding 38%. More critically, over 90% of confused responses yield 'silent failures', which are syntactically valid outputs but deviate from user intent, potentially leading to destructive security consequences. Furthermore, we observe that this vulnerability readily transfers to popular agent frameworks, while existing prompt-based mitigations remain largely ineffective. We call on the community to recognize this emerging vulnerability and develop effective mitigation methods to uphold the safety and reliability of the LLM system.
The Foundation Cracks: A Comprehensive Study on Bugs and Testing Practices in LLM Libraries
Jun 14, 2025Large Language Model (LLM) libraries have emerged as the foundational infrastructure powering today's AI revolution, serving as the backbone for LLM deployment, inference optimization, fine-tuning, and production serving across diverse applications. Despite their critical role in the LLM ecosystem, these libraries face frequent quality issues and bugs that threaten the reliability of AI systems built upon them. To address this knowledge gap, we present the first comprehensive empirical investigation into bug characteristics and testing practices in modern LLM libraries. We examine 313 bug-fixing commits extracted across two widely-adopted LLM libraries: HuggingFace Transformers and vLLM.Through rigorous manual analysis, we establish comprehensive taxonomies categorizing bug symptoms into 5 types and root causes into 14 distinct categories.Our primary discovery shows that API misuse has emerged as the predominant root cause (32.17%-48.19%), representing a notable transition from algorithm-focused defects in conventional deep learning frameworks toward interface-oriented problems. Additionally, we examine 7,748 test functions to identify 7 distinct test oracle categories employed in current testing approaches, with predefined expected outputs (such as specific tensors and text strings) being the most common strategy. Our assessment of existing testing effectiveness demonstrates that the majority of bugs escape detection due to inadequate test cases (41.73%), lack of test drivers (32.37%), and weak test oracles (25.90%). Drawing from these findings, we offer some recommendations for enhancing LLM library quality assurance.
VIDSTAMP: A Temporally-Aware Watermark for Ownership and Integrity in Video Diffusion Models
May 02, 2025The rapid rise of video diffusion models has enabled the generation of highly realistic and temporally coherent videos, raising critical concerns about content authenticity, provenance, and misuse. Existing watermarking approaches, whether passive, post-hoc, or adapted from image-based techniques, often struggle to withstand video-specific manipulations such as frame insertion, dropping, or reordering, and typically degrade visual quality. In this work, we introduce VIDSTAMP, a watermarking framework that embeds per-frame or per-segment messages directly into the latent space of temporally-aware video diffusion models. By fine-tuning the model's decoder through a two-stage pipeline, first on static image datasets to promote spatial message separation, and then on synthesized video sequences to restore temporal consistency, VIDSTAMP learns to embed high-capacity, flexible watermarks with minimal perceptual impact. Leveraging architectural components such as 3D convolutions and temporal attention, our method imposes no additional inference cost and offers better perceptual quality than prior methods, while maintaining comparable robustness against common distortions and tampering. VIDSTAMP embeds 768 bits per video (48 bits per frame) with a bit accuracy of 95.0%, achieves a log P-value of -166.65 (lower is better), and maintains a video quality score of 0.836, comparable to unwatermarked outputs (0.838) and surpassing prior methods in capacity-quality tradeoffs. Code: Code: \url{https://github.com/SPIN-UMass/VidStamp}
Exposing Product Bias in LLM Investment Recommendation
Mar 11, 2025Large language models (LLMs), as a new generation of recommendation engines, possess powerful summarization and data analysis capabilities, surpassing traditional recommendation systems in both scope and performance. One promising application is investment recommendation. In this paper, we reveal a novel product bias in LLM investment recommendation, where LLMs exhibit systematic preferences for specific products. Such preferences can subtly influence user investment decisions, potentially leading to inflated valuations of products and financial bubbles, posing risks to both individual investors and market stability. To comprehensively study the product bias, we develop an automated pipeline to create a dataset of 567,000 samples across five asset classes (stocks, mutual funds, cryptocurrencies, savings, and portfolios). With this dataset, we present the bf first study on product bias in LLM investment recommendations. Our findings reveal that LLMs exhibit clear product preferences, such as certain stocks (e.g., `AAPL' from Apple and `MSFT' from Microsoft). Notably, this bias persists even after applying debiasing techniques. We urge AI researchers to take heed of the product bias in LLM investment recommendations and its implications, ensuring fairness and security in the digital space and market.
Holistic Audit Dataset Generation for LLM Unlearning via Knowledge Graph Traversal and Redundancy Removal
Feb 26, 2025In recent years, Large Language Models (LLMs) have faced increasing demands to selectively remove sensitive information, protect privacy, and comply with copyright regulations through unlearning, by Machine Unlearning. While evaluating unlearning effectiveness is crucial, existing benchmarks are limited in scale and comprehensiveness, typically containing only a few hundred test cases. We identify two critical challenges in generating holistic audit datasets: ensuring audit adequacy and handling knowledge redundancy between forget and retain dataset. To address these challenges, we propose HANKER, an automated framework for holistic audit dataset generation leveraging knowledge graphs to achieve fine-grained coverage and eliminate redundant knowledge. Applying HANKER to the popular MUSE benchmark, we successfully generated over 69,000 and 111,000 audit cases for the News and Books datasets respectively, identifying thousands of knowledge memorization instances that the previous benchmark failed to detect. Our empirical analysis uncovers how knowledge redundancy significantly skews unlearning effectiveness metrics, with redundant instances artificially inflating the observed memorization measurements ROUGE from 19.7% to 26.1% and Entailment Scores from 32.4% to 35.2%, highlighting the necessity of systematic deduplication for accurate assessment.
Unveiling Provider Bias in Large Language Models for Code Generation
Jan 14, 2025Large Language Models (LLMs) have emerged as the new recommendation engines, outperforming traditional methods in both capability and scope, particularly in code generation applications. Our research reveals a novel provider bias in LLMs, namely without explicit input prompts, these models show systematic preferences for services from specific providers in their recommendations (e.g., favoring Google Cloud over Microsoft Azure). This bias holds significant implications for market dynamics and societal equilibrium, potentially promoting digital monopolies. It may also deceive users and violate their expectations, leading to various consequences. This paper presents the first comprehensive empirical study of provider bias in LLM code generation. We develop a systematic methodology encompassing an automated pipeline for dataset generation, incorporating 6 distinct coding task categories and 30 real-world application scenarios. Our analysis encompasses over 600,000 LLM-generated responses across seven state-of-the-art models, utilizing approximately 500 million tokens (equivalent to \$5,000+ in computational costs). The study evaluates both the generated code snippets and their embedded service provider selections to quantify provider bias. Additionally, we conduct a comparative analysis of seven debiasing prompting techniques to assess their efficacy in mitigating these biases. Our findings demonstrate that LLMs exhibit significant provider preferences, predominantly favoring services from Google and Amazon, and can autonomously modify input code to incorporate their preferred providers without users' requests. Notably, we observe discrepancies between providers recommended in conversational contexts versus those implemented in generated code. The complete dataset and analysis results are available in our repository.
MLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
Token-Budget-Aware LLM Reasoning
Dec 24, 2024



Reasoning is critical for large language models (LLMs) to excel in a wide range of tasks. While methods like Chain-of-Thought (CoT) reasoning enhance LLM performance by decomposing problems into intermediate steps, they also incur significant overhead in token usage, leading to increased costs. We find that the reasoning process of current LLMs is unnecessarily lengthy and it can be compressed by including a reasonable token budget in the prompt, but the choice of token budget plays a crucial role in the actual compression effectiveness. We then propose a token-budget-aware LLM reasoning framework, which dynamically estimates token budgets for different problems based on reasoning complexity and uses the estimated token budgets to guide the reasoning process. Experiments show that our method effectively reduces token costs in CoT reasoning with only a slight performance reduction, offering a practical solution to balance efficiency and accuracy in LLM reasoning. Code: https://github.com/GeniusHTX/TALE.
Continuous Concepts Removal in Text-to-image Diffusion Models
Nov 30, 2024
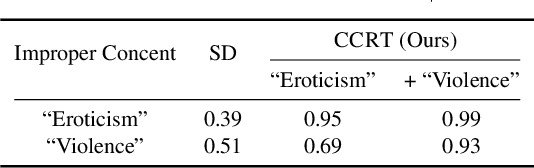

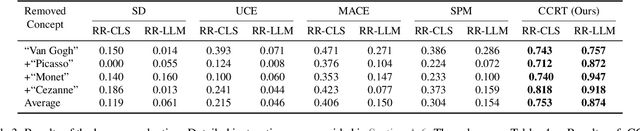
Text-to-image diffusion models have shown an impressive ability to generate high-quality images from input textual descriptions. However, concerns have been raised about the potential for these models to create content that infringes on copyrights or depicts disturbing subject matter. Removing specific concepts from these models is a promising potential solution to this problem. However, existing methods for concept removal do not work well in practical but challenging scenarios where concepts need to be continuously removed. Specifically, these methods lead to poor alignment between the text prompts and the generated image after the continuous removal process. To address this issue, we propose a novel approach called CCRT that includes a designed knowledge distillation paradigm. It constrains the text-image alignment behavior during the continuous concept removal process by using a set of text prompts generated through our genetic algorithm, which employs a designed fuzzing strategy. We conduct extensive experiments involving the removal of various concepts. The results evaluated through both algorithmic metrics and human studies demonstrate that our CCRT can effectively remove the targeted concepts in a continuous manner while maintaining the high generation quality (e.g., text-image alignment) of the model.
Bias Similarity Across Large Language Models
Oct 15, 2024Bias in machine learning models has been a chronic problem, especially as these models influence decision-making in human society. In generative AI, such as Large Language Models, the impact of bias is even more profound compared to the classification models. LLMs produce realistic and human-like content that users may unconsciously trust, which could perpetuate harmful stereotypes to the uncontrolled public. It becomes particularly concerning when utilized in journalism or education. While prior studies have explored and quantified bias in individual AI models, no work has yet compared bias similarity across different LLMs. To fill this gap, we take a comprehensive look at ten open- and closed-source LLMs from four model families, assessing the extent of biases through output distribution. Using two datasets-one containing 4k questions and another with one million questions for each of the four bias dimensions -- we measure functional similarity to understand how biases manifest across models. Our findings reveal that 1) fine-tuning does not significantly alter output distributions, which would limit its ability to mitigate bias, 2) LLMs within the same family tree do not produce similar output distributions, implying that addressing bias in one model could have limited implications for others in the same family, and 3) there is a possible risk of training data information leakage, raising concerns about privacy and data security. Our analysis provides insight into LLM behavior and highlights potential risks in real-world deployment.