 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
Class-RAG: Content Moderation with Retrieval Augmented Generation
Oct 18, 2024



Robust content moderation classifiers are essential for the safety of Generative AI systems. Content moderation, or safety classification, is notoriously ambiguous: differences between safe and unsafe inputs are often extremely subtle, making it difficult for classifiers (and indeed, even humans) to properly distinguish violating vs. benign samples without further context or explanation. Furthermore, as these technologies are deployed across various applications and audiences, scaling risk discovery and mitigation through continuous model fine-tuning becomes increasingly challenging and costly. To address these challenges, we propose a Classification approach employing Retrieval-Augmented Generation (Class-RAG). Class-RAG extends the capability of its base LLM through access to a retrieval library which can be dynamically updated to enable semantic hotfixing for immediate, flexible risk mitigation. Compared to traditional fine-tuned models, Class-RAG demonstrates flexibility and transparency in decision-making. As evidenced by empirical studies, Class-RAG outperforms on classification and is more robust against adversarial attack. Besides, our findings suggest that Class-RAG performance scales with retrieval library size, indicating that increasing the library size is a viable and low-cost approach to improve content moderation.
RecipeSnap -- a lightweight image-to-recipe model
May 04, 2022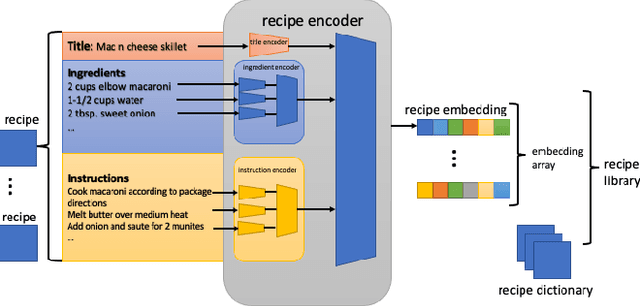
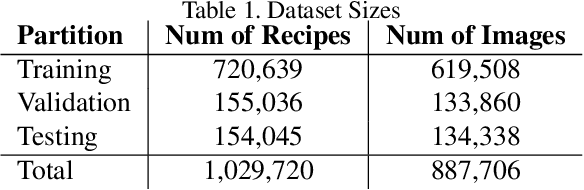
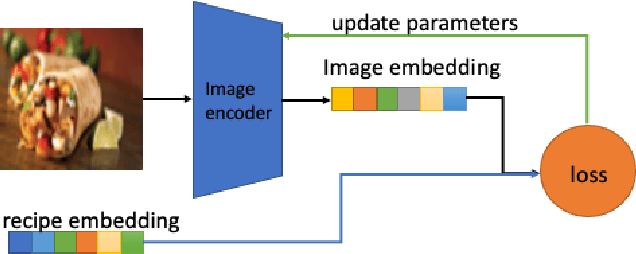
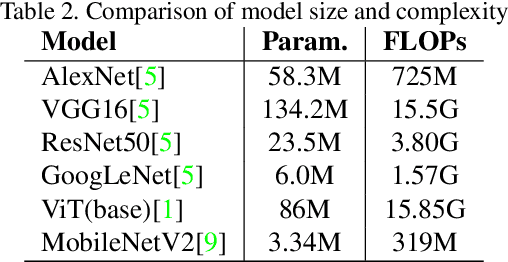
In this paper we want to address the problem of automation for recognition of photographed cooking dishes and generating the corresponding food recipes. Current image-to-recipe models are computation expensive and require powerful GPUs for model training and implementation. High computational cost prevents those existing models from being deployed on portable devices, like smart phones. To solve this issue we introduce a lightweight image-to-recipe prediction model, RecipeSnap, that reduces memory cost and computational cost by more than 90% while still achieving 2.0 MedR, which is in line with the state-of-the-art model. A pre-trained recipe encoder was used to compute recipe embeddings. Recipes from Recipe1M dataset and corresponding recipe embeddings are collected as a recipe library, which are used for image encoder training and image query later. We use MobileNet-V2 as image encoder backbone, which makes our model suitable to portable devices. This model can be further developed into an application for smart phones with a few effort. A comparison of the performance between this lightweight model to other heavy models are presented in this paper. Code, data and models are publicly accessible on github.