 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-THEBench: Do Reasoning MLLMs Think Reasonably?
Jan 30, 2026Recent advances in multimodal large language models (MLLMs) mark a shift from non-thinking models to post-trained reasoning models capable of solving complex problems through thinking. However, whether such thinking mitigates hallucinations in multimodal perception and reasoning remains unclear. Self-reflective reasoning enhances robustness but introduces additional hallucinations, and subtle perceptual errors still result in incorrect or coincidentally correct answers. Existing benchmarks primarily focus on models before the emergence of reasoning MLLMs, neglecting the internal thinking process and failing to measure the hallucinations that occur during thinking. To address these challenges, we introduce MM-THEBench, a comprehensive benchmark for assessing hallucinations of intermediate CoTs in reasoning MLLMs. MM-THEBench features a fine-grained taxonomy grounded in cognitive dimensions, diverse data with verified reasoning annotations, and a multi-level automated evaluation framework. Extensive experiments on mainstream reasoning MLLMs reveal insights into how thinking affects hallucination and reasoning capability in various multimodal tasks.
MemoryRewardBench: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 24, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce MemoryRewardBench, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. MemoryRewardBench covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
$\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 17, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce $\texttt{MemoryRewardBench}$, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. $\texttt{MemoryRewardBench}$ covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
LANCET: Neural Intervention via Structural Entropy for Mitigating Faithfulness Hallucinations in LLMs
Jan 04, 2026Large Language Models have revolutionized information processing, yet their reliability is severely compromised by faithfulness hallucinations. While current approaches attempt to mitigate this issue through node-level adjustments or coarse suppression, they often overlook the distributed nature of neural information, leading to imprecise interventions. Recognizing that hallucinations propagate through specific forward transmission pathways like an infection, we aim to surgically block this flow using precise structural analysis. To leverage this, we propose Lancet, a novel framework that achieves precise neural intervention by leveraging structural entropy and hallucination difference ratios. Lancet first locates hallucination-prone neurons via gradient-driven contrastive analysis, then maps their propagation pathways by minimizing structural entropy, and finally implements a hierarchical intervention strategy that preserves general model capabilities. Comprehensive evaluations across hallucination benchmark datasets demonstrate that Lancet significantly outperforms state-of-the-art methods, validating the effectiveness of our surgical approach to neural intervention.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
SFNet: Fusion of Spatial and Frequency-Domain Features for Remote Sensing Image Forgery Detection
Jun 25, 2025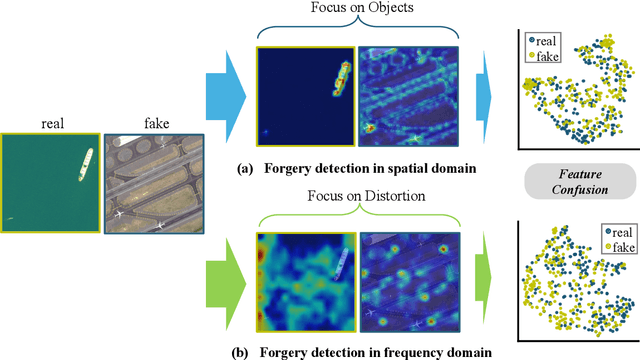
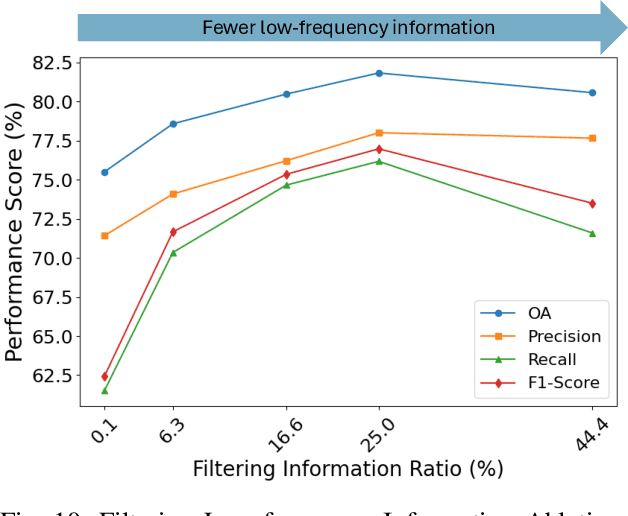
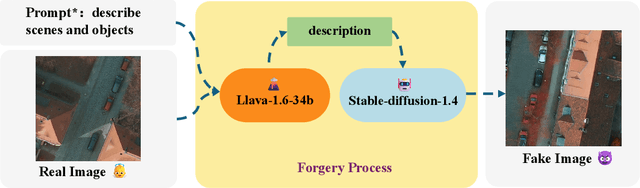
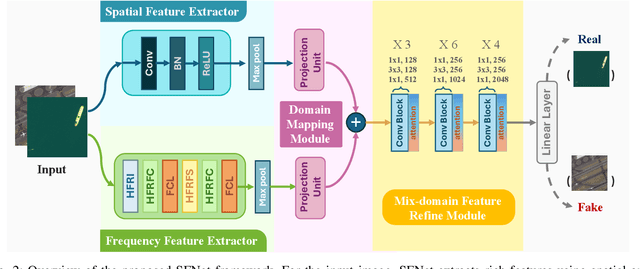
The rapid advancement of generative artificial intelligence is producing fake remote sensing imagery (RSI) that is increasingly difficult to detect, potentially leading to erroneous intelligence, fake news, and even conspiracy theories. Existing forgery detection methods typically rely on single visual features to capture predefined artifacts, such as spatial-domain cues to detect forged objects like roads or buildings in RSI, or frequency-domain features to identify artifacts from up-sampling operations in adversarial generative networks (GANs). However, the nature of artifacts can significantly differ depending on geographic terrain, land cover types, or specific features within the RSI. Moreover, these complex artifacts evolve as generative models become more sophisticated. In short, over-reliance on a single visual cue makes existing forgery detectors struggle to generalize across diverse remote sensing data. This paper proposed a novel forgery detection framework called SFNet, designed to identify fake images in diverse remote sensing data by leveraging spatial and frequency domain features. Specifically, to obtain rich and comprehensive visual information, SFNet employs two independent feature extractors to capture spatial and frequency domain features from input RSIs. To fully utilize the complementary domain features, the domain feature mapping module and the hybrid domain feature refinement module(CBAM attention) of SFNet are designed to successively align and fuse the multi-domain features while suppressing redundant information. Experiments on three datasets show that SFNet achieves an accuracy improvement of 4%-15.18% over the state-of-the-art RS forgery detection methods and exhibits robust generalization capabilities. The code is available at https://github.com/GeoX-Lab/RSTI/tree/main/SFNet.
TextVidBench: A Benchmark for Long Video Scene Text Understanding
Jun 05, 2025Despite recent progress on the short-video Text-Visual Question Answering (ViteVQA) task - largely driven by benchmarks such as M4-ViteVQA - existing datasets still suffer from limited video duration and narrow evaluation scopes, making it difficult to adequately assess the growing capabilities of powerful multimodal large language models (MLLMs). To address these limitations, we introduce TextVidBench, the first benchmark specifically designed for long-video text question answering (>3 minutes). TextVidBench makes three key contributions: 1) Cross-domain long-video coverage: Spanning 9 categories (e.g., news, sports, gaming), with an average video length of 2306 seconds, enabling more realistic evaluation of long-video understanding. 2) A three-stage evaluation framework: "Text Needle-in-Haystack -> Temporal Grounding -> Text Dynamics Captioning". 3) High-quality fine-grained annotations: Containing over 5,000 question-answer pairs with detailed semantic labeling. Furthermore, we propose an efficient paradigm for improving large models through: (i) introducing the IT-Rope mechanism and temporal prompt engineering to enhance temporal perception, (ii) adopting non-uniform positional encoding to better handle long video sequences, and (iii) applying lightweight fine-tuning on video-text data. Extensive experiments on multiple public datasets as well as TextVidBench demonstrate that our new benchmark presents significant challenges to existing models, while our proposed method offers valuable insights into improving long-video scene text understanding capabilities.
Hard Negative Contrastive Learning for Fine-Grained Geometric Understanding in Large Multimodal Models
May 26, 2025Benefiting from contrastively trained visual encoders on large-scale natural scene images, Large Multimodal Models (LMMs) have achieved remarkable performance across various visual perception tasks. However, the inherent limitations of contrastive learning upon summarized descriptions fundamentally restrict the capabilities of models in meticulous reasoning, particularly in crucial scenarios of geometric problem-solving. To enhance geometric understanding, we propose a novel hard negative contrastive learning framework for the vision encoder, which combines image-based contrastive learning using generation-based hard negatives created by perturbing diagram generation code, and text-based contrastive learning using rule-based negatives derived from modified geometric descriptions and retrieval-based negatives selected based on caption similarity. We train CLIP using our strong negative learning method, namely MMCLIP (Multimodal Math CLIP), and subsequently train an LMM for geometric problem-solving. Experiments show that our trained model, MMGeoLM, significantly outperforms other open-source models on three geometric reasoning benchmarks. Even with a size of 7B, it can rival powerful closed-source models like GPT-4o. We further study the impact of different negative sample construction methods and the number of negative samples on the geometric reasoning performance of LMM, yielding fruitful conclusions. The code and dataset are available at https://github.com/THU-KEG/MMGeoLM.
Lightweight Transformer via Unrolling of Mixed Graph Algorithms for Traffic Forecast
May 19, 2025
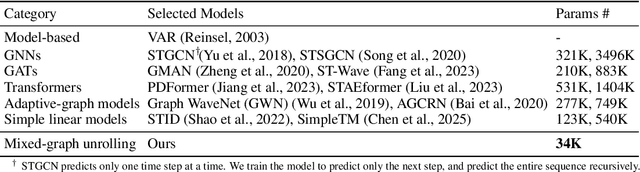

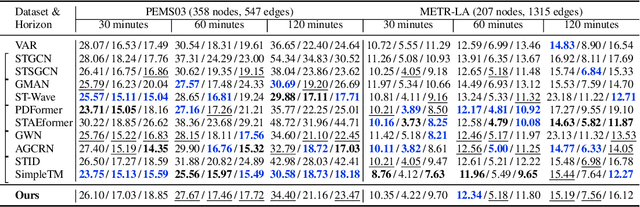
To forecast traffic with both spatial and temporal dimensions, we unroll a mixed-graph-based optimization algorithm into a lightweight and interpretable transformer-like neural net. Specifically, we construct two graphs: an undirected graph $\mathcal{G}^u$ capturing spatial correlations across geography, and a directed graph $\mathcal{G}^d$ capturing sequential relationships over time. We formulate a prediction problem for the future samples of signal $\mathbf{x}$, assuming it is "smooth" with respect to both $\mathcal{G}^u$ and $\mathcal{G}^d$, where we design new $\ell_2$ and $\ell_1$-norm variational terms to quantify and promote signal smoothness (low-frequency reconstruction) on a directed graph. We construct an iterative algorithm based on alternating direction method of multipliers (ADMM), and unroll it into a feed-forward network for data-driven parameter learning. We insert graph learning modules for $\mathcal{G}^u$ and $\mathcal{G}^d$, which are akin to the self-attention mechanism in classical transformers. Experiments show that our unrolled networks achieve competitive traffic forecast performance as state-of-the-art prediction schemes, while reducing parameter counts drastically. Our code is available in https://github.com/SingularityUndefined/Unrolling-GSP-STForecast.
An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes
Apr 21, 2025



Large Multimodal Models (LMMs) uniformly perceive video frames, creating computational inefficiency for videos with inherently varying temporal information density. This paper present \textbf{Quicksviewer}, an LMM with new perceiving paradigm that partitions a video of nonuniform density into varying cubes using Gumbel Softmax, followed by a unified resampling for each cube to achieve efficient video understanding. This simple and intuitive approach dynamically compress video online based on its temporal density, significantly reducing spatiotemporal redundancy (overall 45$\times$ compression rate), while enabling efficient training with large receptive field. We train the model from a language backbone through three progressive stages, each incorporating lengthy videos on average of 420s/1fps thanks to the perceiving efficiency. With only 0.8M total video-text samples for training, our model outperforms the direct baseline employing a fixed partitioning strategy by a maximum of 8.72 in accuracy, demonstrating the effectiveness in performance. On Video-MME, Quicksviewer achieves SOTA under modest sequence lengths using just up to 5\% of tokens per frame required by baselines. With this paradigm, scaling up the number of input frames reveals a clear power law of the model capabilities. It is also empirically verified that the segments generated by the cubing network can help for analyzing continuous events in videos.