 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Facial Action Unit Recognition Framework by Large Language Models
Sep 13, 2024



Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
MVLLaVA: An Intelligent Agent for Unified and Flexible Novel View Synthesis
Sep 11, 2024This paper introduces MVLLaVA, an intelligent agent designed for novel view synthesis tasks. MVLLaVA integrates multiple multi-view diffusion models with a large multimodal model, LLaVA, enabling it to handle a wide range of tasks efficiently. MVLLaVA represents a versatile and unified platform that adapts to diverse input types, including a single image, a descriptive caption, or a specific change in viewing azimuth, guided by language instructions for viewpoint generation. We carefully craft task-specific instruction templates, which are subsequently used to fine-tune LLaVA. As a result, MVLLaVA acquires the capability to generate novel view images based on user instructions, demonstrating its flexibility across diverse tasks. Experiments are conducted to validate the effectiveness of MVLLaVA, demonstrating its robust performance and versatility in tackling diverse novel view synthesis challenges.
ExpLLM: Towards Chain of Thought for Facial Expression Recognition
Sep 04, 2024



Facial expression recognition (FER) is a critical task in multimedia with significant implications across various domains. However, analyzing the causes of facial expressions is essential for accurately recognizing them. Current approaches, such as those based on facial action units (AUs), typically provide AU names and intensities but lack insight into the interactions and relationships between AUs and the overall expression. In this paper, we propose a novel method called ExpLLM, which leverages large language models to generate an accurate chain of thought (CoT) for facial expression recognition. Specifically, we have designed the CoT mechanism from three key perspectives: key observations, overall emotional interpretation, and conclusion. The key observations describe the AU's name, intensity, and associated emotions. The overall emotional interpretation provides an analysis based on multiple AUs and their interactions, identifying the dominant emotions and their relationships. Finally, the conclusion presents the final expression label derived from the preceding analysis. Furthermore, we also introduce the Exp-CoT Engine, designed to construct this expression CoT and generate instruction-description data for training our ExpLLM. Extensive experiments on the RAF-DB and AffectNet datasets demonstrate that ExpLLM outperforms current state-of-the-art FER methods. ExpLLM also surpasses the latest GPT-4o in expression CoT generation, particularly in recognizing micro-expressions where GPT-4o frequently fails.
FoodSAM: Any Food Segmentation
Aug 11, 2023



In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
HIH: Towards More Accurate Face Alignment via Heatmap in Heatmap
Apr 07, 2021
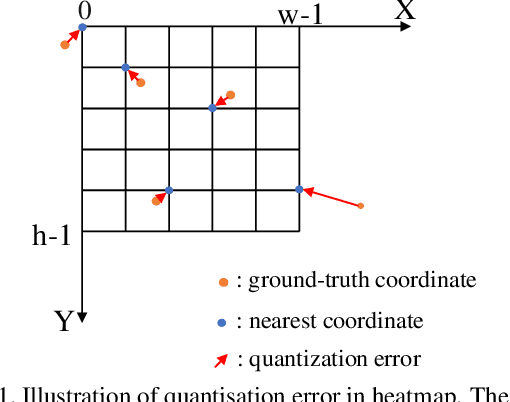

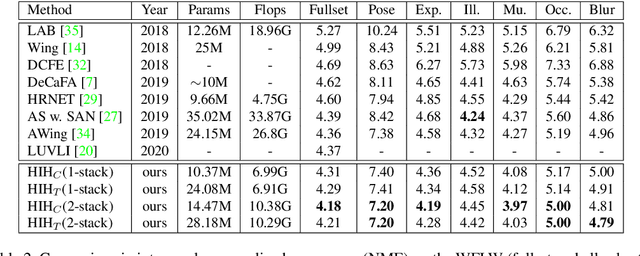
Recently, heatmap regression models have become the mainstream in locating facial landmarks. To keep computation affordable and reduce memory usage, the whole procedure involves downsampling from the raw image to the output heatmap. However, how much impact will the quantization error introduced by downsampling bring? The problem is hardly systematically investigated among previous works. This work fills the blank and we are the first to quantitatively analyze the negative gain. The statistical results show the NME generated by quantization error is even larger than 1/3 of the SOTA item, which is a serious obstacle for making a new breakthrough in face alignment. To compensate the impact of quantization effect, we propose a novel method, called Heatmap In Heatmap(HIH), which leverages two categories of heatmaps as label representation to encode coordinate. And in HIH, the range of one heatmap represents a pixel of the other category of heatmap. Also, we even combine the face alignment with solutions of other fields to make a comparison. Extensive experiments on various benchmarks show the feasibility of HIH and the superior performance than other solutions. Moreover, the mean error reaches to 4.18 on WFLW, which exceeds SOTA a lot. Our source code are made publicly available at supplementary material.