 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUHead: Realistic Emotional Talking Head Generation via Action Units Control
Feb 10, 2026Realistic talking-head video generation is critical for virtual avatars, film production, and interactive systems. Current methods struggle with nuanced emotional expressions due to the lack of fine-grained emotion control. To address this issue, we introduce a novel two-stage method (AUHead) to disentangle fine-grained emotion control, i.e. , Action Units (AUs), from audio and achieve controllable generation. In the first stage, we explore the AU generation abilities of large audio-language models (ALMs), by spatial-temporal AU tokenization and an "emotion-then-AU" chain-of-thought mechanism. It aims to disentangle AUs from raw speech, effectively capturing subtle emotional cues. In the second stage, we propose an AU-driven controllable diffusion model that synthesizes realistic talking-head videos conditioned on AU sequences. Specifically, we first map the AU sequences into the structured 2D facial representation to enhance spatial fidelity, and then model the AU-vision interaction within cross-attention modules. To achieve flexible AU-quality trade-off control, we introduce an AU disentanglement guidance strategy during inference, further refining the emotional expressiveness and identity consistency of the generated videos. Results on benchmark datasets demonstrate that our approach achieves competitive performance in emotional realism, accurate lip synchronization, and visual coherence, significantly surpassing existing techniques. Our implementation is available at https://github.com/laura990501/AUHead_ICLR
Lingua-SafetyBench: A Benchmark for Safety Evaluation of Multilingual Vision-Language Models
Jan 30, 2026Robust safety of vision-language large models (VLLMs) under joint multilingual and multimodal inputs remains underexplored. Existing benchmarks are typically multilingual but text-only, or multimodal but monolingual. Recent multilingual multimodal red-teaming efforts render harmful prompts into images, yet rely heavily on typography-style visuals and lack semantically grounded image-text pairs, limiting coverage of realistic cross-modal interactions. We introduce Lingua-SafetyBench, a benchmark of 100,440 harmful image-text pairs across 10 languages, explicitly partitioned into image-dominant and text-dominant subsets to disentangle risk sources. Evaluating 11 open-source VLLMs reveals a consistent asymmetry: image-dominant risks yield higher ASR in high-resource languages, while text-dominant risks are more severe in non-high-resource languages. A controlled study on the Qwen series shows that scaling and version upgrades reduce Attack Success Rate (ASR) overall but disproportionately benefit HRLs, widening the gap between HRLs and Non-HRLs under text-dominant risks. This underscores the necessity of language- and modality-aware safety alignment beyond mere scaling.To facilitate reproducibility and future research, we will publicly release our benchmark, model checkpoints, and source code.The code and dataset will be available at https://github.com/zsxr15/Lingua-SafetyBench.Warning: this paper contains examples with unsafe content.
DAMamba: Vision State Space Model with Dynamic Adaptive Scan
Feb 18, 2025



State space models (SSMs) have recently garnered significant attention in computer vision. However, due to the unique characteristics of image data, adapting SSMs from natural language processing to computer vision has not outperformed the state-of-the-art convolutional neural networks (CNNs) and Vision Transformers (ViTs). Existing vision SSMs primarily leverage manually designed scans to flatten image patches into sequences locally or globally. This approach disrupts the original semantic spatial adjacency of the image and lacks flexibility, making it difficult to capture complex image structures. To address this limitation, we propose Dynamic Adaptive Scan (DAS), a data-driven method that adaptively allocates scanning orders and regions. This enables more flexible modeling capabilities while maintaining linear computational complexity and global modeling capacity. Based on DAS, we further propose the vision backbone DAMamba, which significantly outperforms current state-of-the-art vision Mamba models in vision tasks such as image classification, object detection, instance segmentation, and semantic segmentation. Notably, it surpasses some of the latest state-of-the-art CNNs and ViTs. Code will be available at https://github.com/ltzovo/DAMamba.
Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Sep 13, 2024



Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
FoodSAM: Any Food Segmentation
Aug 11, 2023



In this paper, we explore the zero-shot capability of the Segment Anything Model (SAM) for food image segmentation. To address the lack of class-specific information in SAM-generated masks, we propose a novel framework, called FoodSAM. This innovative approach integrates the coarse semantic mask with SAM-generated masks to enhance semantic segmentation quality. Besides, we recognize that the ingredients in food can be supposed as independent individuals, which motivated us to perform instance segmentation on food images. Furthermore, FoodSAM extends its zero-shot capability to encompass panoptic segmentation by incorporating an object detector, which renders FoodSAM to effectively capture non-food object information. Drawing inspiration from the recent success of promptable segmentation, we also extend FoodSAM to promptable segmentation, supporting various prompt variants. Consequently, FoodSAM emerges as an all-encompassing solution capable of segmenting food items at multiple levels of granularity. Remarkably, this pioneering framework stands as the first-ever work to achieve instance, panoptic, and promptable segmentation on food images. Extensive experiments demonstrate the feasibility and impressing performance of FoodSAM, validating SAM's potential as a prominent and influential tool within the domain of food image segmentation. We release our code at https://github.com/jamesjg/FoodSAM.
K-Space-Aware Cross-Modality Score for Synthesized Neuroimage Quality Assessment
Jul 10, 2023



The problem of how to assess cross-modality medical image synthesis has been largely unexplored. The most used measures like PSNR and SSIM focus on analyzing the structural features but neglect the crucial lesion location and fundamental k-space speciality of medical images. To overcome this problem, we propose a new metric K-CROSS to spur progress on this challenging problem. Specifically, K-CROSS uses a pre-trained multi-modality segmentation network to predict the lesion location, together with a tumor encoder for representing features, such as texture details and brightness intensities. To further reflect the frequency-specific information from the magnetic resonance imaging principles, both k-space features and vision features are obtained and employed in our comprehensive encoders with a frequency reconstruction penalty. The structure-shared encoders are designed and constrained with a similarity loss to capture the intrinsic common structural information for both modalities. As a consequence, the features learned from lesion regions, k-space, and anatomical structures are all captured, which serve as our quality evaluators. We evaluate the performance by constructing a large-scale cross-modality neuroimaging perceptual similarity (NIRPS) dataset with 6,000 radiologist judgments. Extensive experiments demonstrate that the proposed method outperforms other metrics, especially in comparison with the radiologists on NIRPS.
IM-IAD: Industrial Image Anomaly Detection Benchmark in Manufacturing
Jan 31, 2023Image anomaly detection (IAD) is an emerging and vital computer vision task in industrial manufacturing (IM). Recently many advanced algorithms have been published, but their performance deviates greatly. We realize that the lack of actual IM settings most probably hinders the development and usage of these methods in real-world applications. As far as we know, IAD methods are not evaluated systematically. As a result, this makes it difficult for researchers to analyze them because they are designed for different or special cases. To solve this problem, we first propose a uniform IM setting to assess how well these algorithms perform, which includes several aspects, i.e., various levels of supervision (unsupervised vs. semi-supervised), few-shot learning, continual learning, noisy labels, memory usage, and inference speed. Moreover, we skillfully build a comprehensive image anomaly detection benchmark (IM-IAD) that includes 16 algorithms on 7 mainstream datasets with uniform settings. Our extensive experiments (17,017 in total) provide in-depth insights for IAD algorithm redesign or selection under the IM setting. Next, the proposed benchmark IM-IAD gives challenges as well as directions for the future. To foster reproducibility and accessibility, the source code of IM-IAD is uploaded on the website, https://github.com/M-3LAB/IM-IAD.
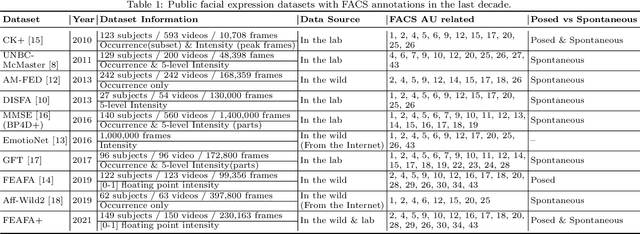
FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Nov 04, 2021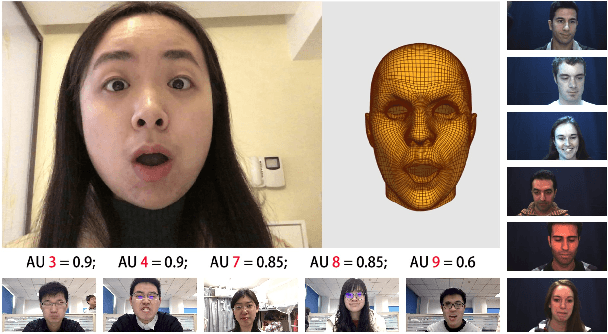
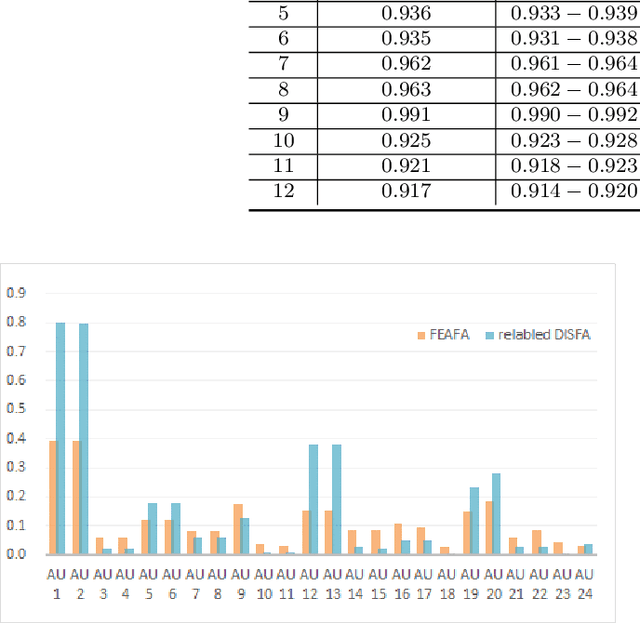
Nearly all existing Facial Action Coding System-based datasets that include facial action unit (AU) intensity information annotate the intensity values hierarchically using A--E levels. However, facial expressions change continuously and shift smoothly from one state to another. Therefore, it is more effective to regress the intensity value of local facial AUs to represent whole facial expression changes, particularly in the fields of expression transfer and facial animation. We introduce an extension of FEAFA in combination with the relabeled DISFA database, which is available at https://www.iiplab.net/feafa+/ now. Extended FEAFA (FEAFA+) includes 150 video sequences from FEAFA and DISFA, with a total of 230,184 frames being manually annotated on floating-point intensity value of 24 redefined AUs using the Expression Quantitative Tool. We also list crude numerical results for posed and spontaneous subsets and provide a baseline comparison for the AU intensity regression task.
FEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Apr 02, 2019
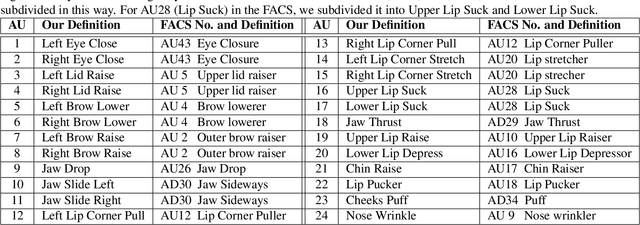
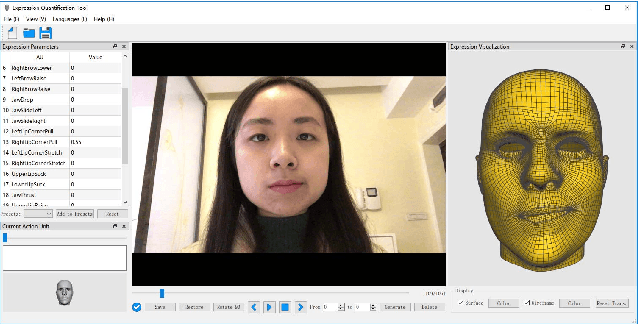
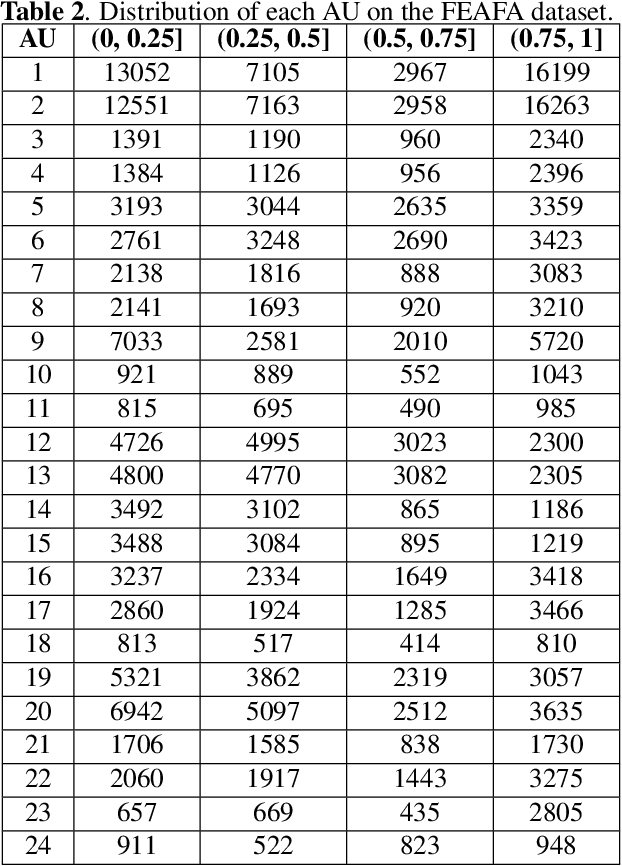
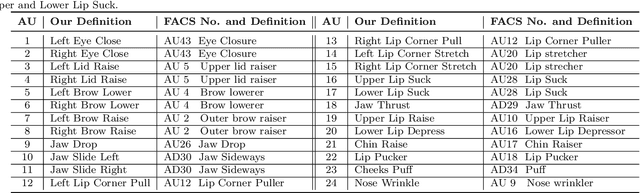
Facial expression analysis based on machine learning requires large number of well-annotated data to reflect different changes in facial motion. Publicly available datasets truly help to accelerate research in this area by providing a benchmark resource, but all of these datasets, to the best of our knowledge, are limited to rough annotations for action units, including only their absence, presence, or a five-level intensity according to the Facial Action Coding System. To meet the need for videos labeled in great detail, we present a well-annotated dataset named FEAFA for Facial Expression Analysis and 3D Facial Animation. One hundred and twenty-two participants, including children, young adults and elderly people, were recorded in real-world conditions. In addition, 99,356 frames were manually labeled using Expression Quantitative Tool developed by us to quantify 9 symmetrical FACS action units, 10 asymmetrical (unilateral) FACS action units, 2 symmetrical FACS action descriptors and 2 asymmetrical FACS action descriptors, and each action unit or action descriptor is well-annotated with a floating point number between 0 and 1. To provide a baseline for use in future research, a benchmark for the regression of action unit values based on Convolutional Neural Networks are presented. We also demonstrate the potential of our FEAFA dataset for 3D facial animation. Almost all state-of-the-art algorithms for facial animation are achieved based on 3D face reconstruction. We hence propose a novel method that drives virtual characters only based on action unit value regression of the 2D video frames of source actors.