 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGenCoder: Merging Seq2Seq and Seq2Tree Paradigms for Unified Code Generation
Feb 18, 2025


Deep learning-based code generation has completely transformed the way developers write programs today. Existing approaches to code generation have focused either on the Sequence-to-Sequence paradigm, which generates target code as a sequence of tokens, or the Sequence-to-Tree paradigm, which outputs code as a sequence of actions. While these two paradigms are intuitively complementary, their combination has not been previously explored. By comparing the code generated under these two paradigms, we find that integrating them holds significant potential. In this paper, we propose UniGenCoder for code-related generation tasks, which consists of a shared encoder, a shared decoder with a minimal set of additional parameters to unify two paradigms, and a selector that dynamically chooses optimal paradigm for each instance. Also, during the model training, we first perform the multi-task learning and distillation strategies to facilitate knowledge transfer between two paradigms, and then leverage contrastive learning to train the selector. Experimental results on the text-to-code and code-to-code generation tasks demonstrate the effectiveness of our proposed model. We release our code at https://github.com/DeepLearnXMU/UniGenCoder.
Semantic GUI Scene Learning and Video Alignment for Detecting Duplicate Video-based Bug Reports
Jul 11, 2024Video-based bug reports are increasingly being used to document bugs for programs centered around a graphical user interface (GUI). However, developing automated techniques to manage video-based reports is challenging as it requires identifying and understanding often nuanced visual patterns that capture key information about a reported bug. In this paper, we aim to overcome these challenges by advancing the bug report management task of duplicate detection for video-based reports. To this end, we introduce a new approach, called JANUS, that adapts the scene-learning capabilities of vision transformers to capture subtle visual and textual patterns that manifest on app UI screens - which is key to differentiating between similar screens for accurate duplicate report detection. JANUS also makes use of a video alignment technique capable of adaptive weighting of video frames to account for typical bug manifestation patterns. In a comprehensive evaluation on a benchmark containing 7,290 duplicate detection tasks derived from 270 video-based bug reports from 90 Android app bugs, the best configuration of our approach achieves an overall mRR/mAP of 89.8%/84.7%, and for the large majority of duplicate detection tasks, outperforms prior work by around 9% to a statistically significant degree. Finally, we qualitatively illustrate how the scene-learning capabilities provided by Janus benefits its performance.
FEAFA+: An Extended Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Nov 04, 2021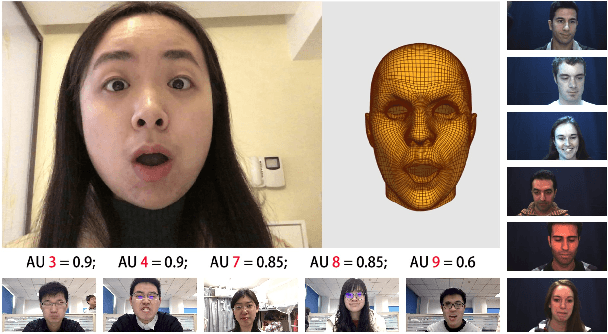
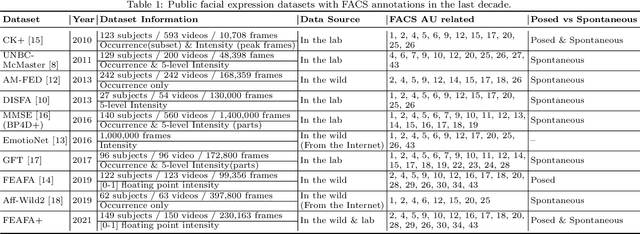
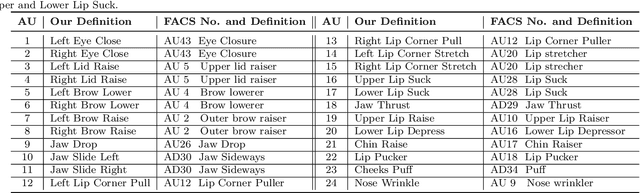
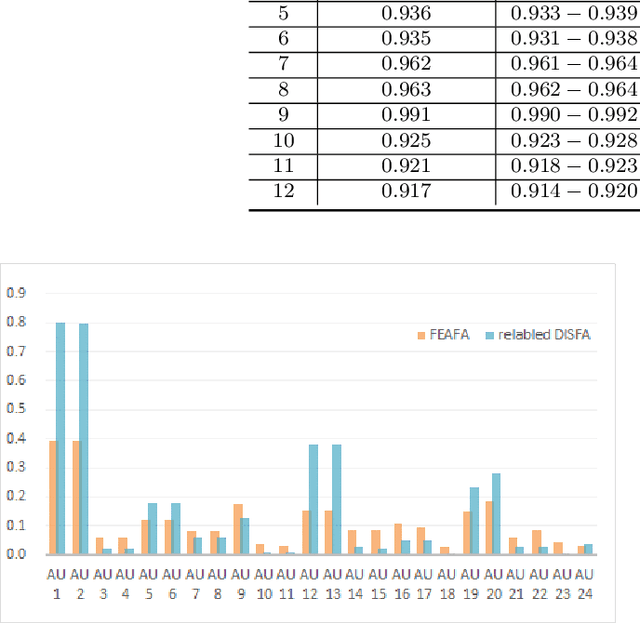
Nearly all existing Facial Action Coding System-based datasets that include facial action unit (AU) intensity information annotate the intensity values hierarchically using A--E levels. However, facial expressions change continuously and shift smoothly from one state to another. Therefore, it is more effective to regress the intensity value of local facial AUs to represent whole facial expression changes, particularly in the fields of expression transfer and facial animation. We introduce an extension of FEAFA in combination with the relabeled DISFA database, which is available at https://www.iiplab.net/feafa+/ now. Extended FEAFA (FEAFA+) includes 150 video sequences from FEAFA and DISFA, with a total of 230,184 frames being manually annotated on floating-point intensity value of 24 redefined AUs using the Expression Quantitative Tool. We also list crude numerical results for posed and spontaneous subsets and provide a baseline comparison for the AU intensity regression task.
FEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Apr 02, 2019
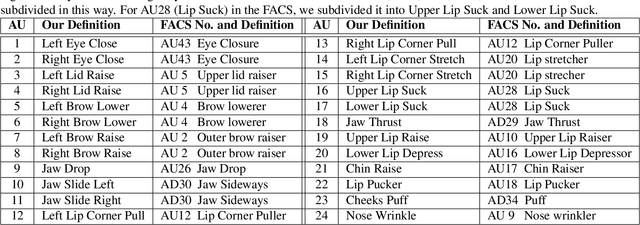
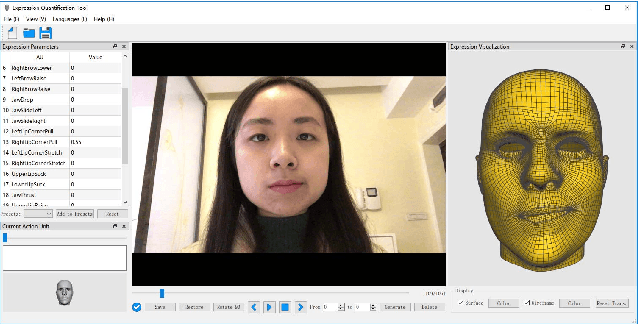
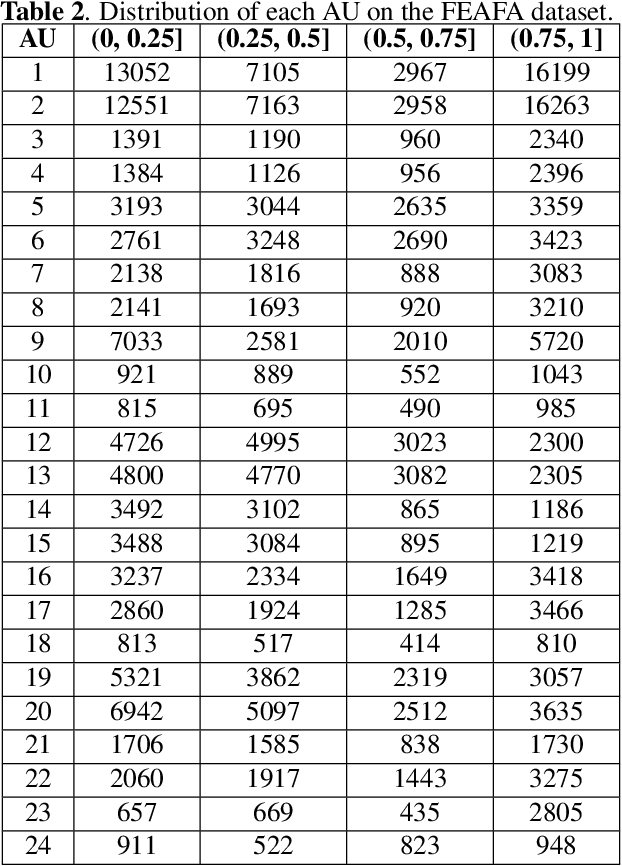
Facial expression analysis based on machine learning requires large number of well-annotated data to reflect different changes in facial motion. Publicly available datasets truly help to accelerate research in this area by providing a benchmark resource, but all of these datasets, to the best of our knowledge, are limited to rough annotations for action units, including only their absence, presence, or a five-level intensity according to the Facial Action Coding System. To meet the need for videos labeled in great detail, we present a well-annotated dataset named FEAFA for Facial Expression Analysis and 3D Facial Animation. One hundred and twenty-two participants, including children, young adults and elderly people, were recorded in real-world conditions. In addition, 99,356 frames were manually labeled using Expression Quantitative Tool developed by us to quantify 9 symmetrical FACS action units, 10 asymmetrical (unilateral) FACS action units, 2 symmetrical FACS action descriptors and 2 asymmetrical FACS action descriptors, and each action unit or action descriptor is well-annotated with a floating point number between 0 and 1. To provide a baseline for use in future research, a benchmark for the regression of action unit values based on Convolutional Neural Networks are presented. We also demonstrate the potential of our FEAFA dataset for 3D facial animation. Almost all state-of-the-art algorithms for facial animation are achieved based on 3D face reconstruction. We hence propose a novel method that drives virtual characters only based on action unit value regression of the 2D video frames of source actors.