 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEAFA: A Well-Annotated Dataset for Facial Expression Analysis and 3D Facial Animation
Paper and Code
Apr 02, 2019
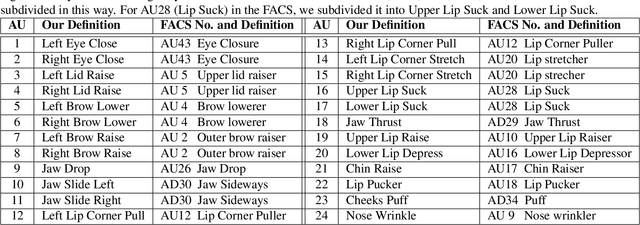
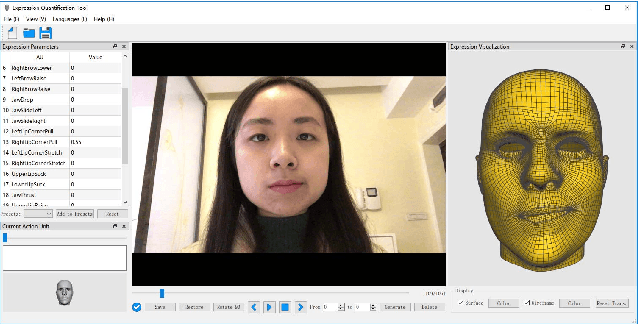
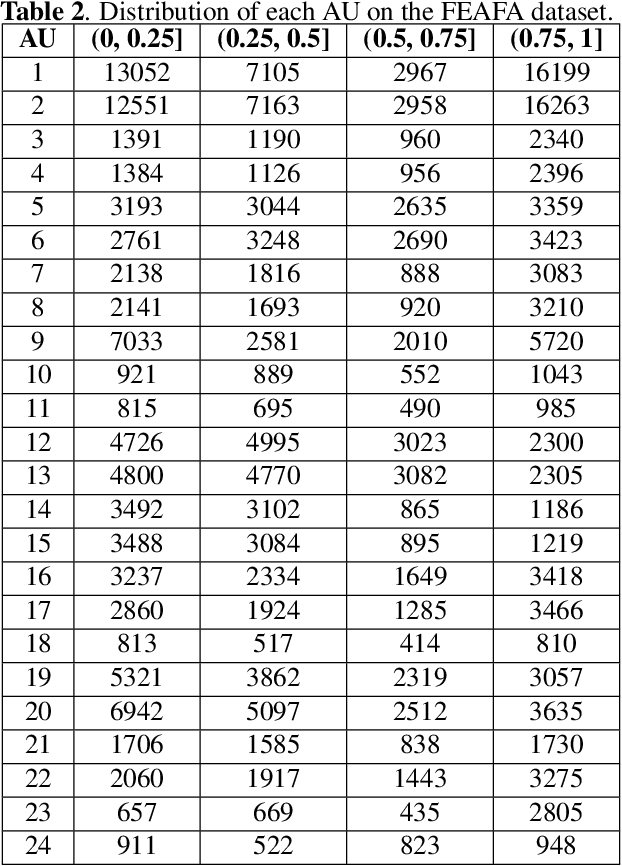
Facial expression analysis based on machine learning requires large number of well-annotated data to reflect different changes in facial motion. Publicly available datasets truly help to accelerate research in this area by providing a benchmark resource, but all of these datasets, to the best of our knowledge, are limited to rough annotations for action units, including only their absence, presence, or a five-level intensity according to the Facial Action Coding System. To meet the need for videos labeled in great detail, we present a well-annotated dataset named FEAFA for Facial Expression Analysis and 3D Facial Animation. One hundred and twenty-two participants, including children, young adults and elderly people, were recorded in real-world conditions. In addition, 99,356 frames were manually labeled using Expression Quantitative Tool developed by us to quantify 9 symmetrical FACS action units, 10 asymmetrical (unilateral) FACS action units, 2 symmetrical FACS action descriptors and 2 asymmetrical FACS action descriptors, and each action unit or action descriptor is well-annotated with a floating point number between 0 and 1. To provide a baseline for use in future research, a benchmark for the regression of action unit values based on Convolutional Neural Networks are presented. We also demonstrate the potential of our FEAFA dataset for 3D facial animation. Almost all state-of-the-art algorithms for facial animation are achieved based on 3D face reconstruction. We hence propose a novel method that drives virtual characters only based on action unit value regression of the 2D video frames of source actors.