 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallax to Align Them All: An OmniParallax Attention Mechanism for Distributed Multi-View Image Compression
Mar 04, 2026Multi-view image compression (MIC) aims to achieve high compression efficiency by exploiting inter-image correlations, playing a crucial role in 3D applications. As a subfield of MIC, distributed multi-view image compression (DMIC) offers performance comparable to MIC while eliminating the need for inter-view information at the encoder side. However, existing methods in DMIC typically treat all images equally, overlooking the varying degrees of correlation between different views during decoding, which leads to suboptimal coding performance. To address this limitation, we propose a novel $\textbf{OmniParallax Attention Mechanism}$ (OPAM), which is a general mechanism for explicitly modeling correlations and aligned features between arbitrary pairs of information sources. Building upon OPAM, we propose a Parallax Multi Information Fusion Module (PMIFM) to adaptively integrate information from different sources. PMIFM is incorporated into both the joint decoder and the entropy model to construct our end-to-end DMIC framework, $\textbf{ParaHydra}$. Extensive experiments demonstrate that $\textbf{ParaHydra}$ is $\textbf{the first DMIC method}$ to significantly surpass state-of-the-art MIC codecs, while maintaining low computational overhead. Performance gains become more pronounced as the number of input views increases. Compared with LDMIC, $\textbf{ParaHydra}$ achieves bitrate savings of $\textbf{19.72%}$ on WildTrack(3) and up to $\textbf{24.18%}$ on WildTrack(6), while significantly improving coding efficiency (as much as $\textbf{65}\times$ in decoding and $\textbf{34}\times$ in encoding).
AUHead: Realistic Emotional Talking Head Generation via Action Units Control
Feb 10, 2026Realistic talking-head video generation is critical for virtual avatars, film production, and interactive systems. Current methods struggle with nuanced emotional expressions due to the lack of fine-grained emotion control. To address this issue, we introduce a novel two-stage method (AUHead) to disentangle fine-grained emotion control, i.e. , Action Units (AUs), from audio and achieve controllable generation. In the first stage, we explore the AU generation abilities of large audio-language models (ALMs), by spatial-temporal AU tokenization and an "emotion-then-AU" chain-of-thought mechanism. It aims to disentangle AUs from raw speech, effectively capturing subtle emotional cues. In the second stage, we propose an AU-driven controllable diffusion model that synthesizes realistic talking-head videos conditioned on AU sequences. Specifically, we first map the AU sequences into the structured 2D facial representation to enhance spatial fidelity, and then model the AU-vision interaction within cross-attention modules. To achieve flexible AU-quality trade-off control, we introduce an AU disentanglement guidance strategy during inference, further refining the emotional expressiveness and identity consistency of the generated videos. Results on benchmark datasets demonstrate that our approach achieves competitive performance in emotional realism, accurate lip synchronization, and visual coherence, significantly surpassing existing techniques. Our implementation is available at https://github.com/laura990501/AUHead_ICLR
Generative AI for Analysts
Dec 12, 2025We study how generative artificial intelligence (AI) transforms the work of financial analysts. Using the 2023 launch of FactSet's AI platform as a natural experiment, we find that adoption produces markedly richer and more comprehensive reports -- featuring 40% more distinct information sources, 34% broader topical coverage, and 25% greater use of advanced analytical methods -- while also improving timeliness. However, forecast errors rise by 59% as AI-assisted reports convey a more balanced mix of positive and negative information that is harder to synthesize, particularly for analysts facing heavier cognitive demands. Placebo tests using other data vendors confirm that these effects are unique to FactSet's AI integration. Overall, our findings reveal both the productivity gains and cognitive limits of generative AI in financial information production.
PHRASED: Phrase Dictionary Biasing for Speech Translation
Jun 10, 2025Phrases are essential to understand the core concepts in conversations. However, due to their rare occurrence in training data, correct translation of phrases is challenging in speech translation tasks. In this paper, we propose a phrase dictionary biasing method to leverage pairs of phrases mapping from the source language to the target language. We apply the phrase dictionary biasing method to two types of widely adopted models, a transducer-based streaming speech translation model and a multimodal large language model. Experimental results show that the phrase dictionary biasing method outperforms phrase list biasing by 21% relatively for the streaming speech translation model. In addition, phrase dictionary biasing enables multimodal large language models to use external phrase information, achieving 85% relative improvement in phrase recall.
Streaming Speaker Change Detection and Gender Classification for Transducer-Based Multi-Talker Speech Translation
Feb 04, 2025



Streaming multi-talker speech translation is a task that involves not only generating accurate and fluent translations with low latency but also recognizing when a speaker change occurs and what the speaker's gender is. Speaker change information can be used to create audio prompts for a zero-shot text-to-speech system, and gender can help to select speaker profiles in a conventional text-to-speech model. We propose to tackle streaming speaker change detection and gender classification by incorporating speaker embeddings into a transducer-based streaming end-to-end speech translation model. Our experiments demonstrate that the proposed methods can achieve high accuracy for both speaker change detection and gender classification.
MambaDETR: Query-based Temporal Modeling using State Space Model for Multi-View 3D Object Detection
Nov 20, 2024



Utilizing temporal information to improve the performance of 3D detection has made great progress recently in the field of autonomous driving. Traditional transformer-based temporal fusion methods suffer from quadratic computational cost and information decay as the length of the frame sequence increases. In this paper, we propose a novel method called MambaDETR, whose main idea is to implement temporal fusion in the efficient state space. Moreover, we design a Motion Elimination module to remove the relatively static objects for temporal fusion. On the standard nuScenes benchmark, our proposed MambaDETR achieves remarkable result in the 3D object detection task, exhibiting state-of-the-art performance among existing temporal fusion methods.
Isochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.
Failing Forward: Improving Generative Error Correction for ASR with Synthetic Data and Retrieval Augmentation
Oct 17, 2024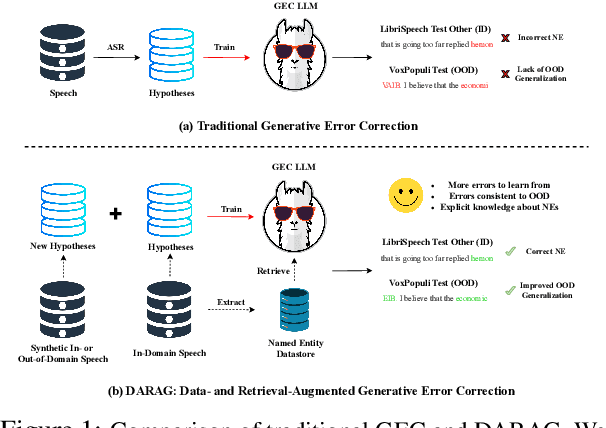
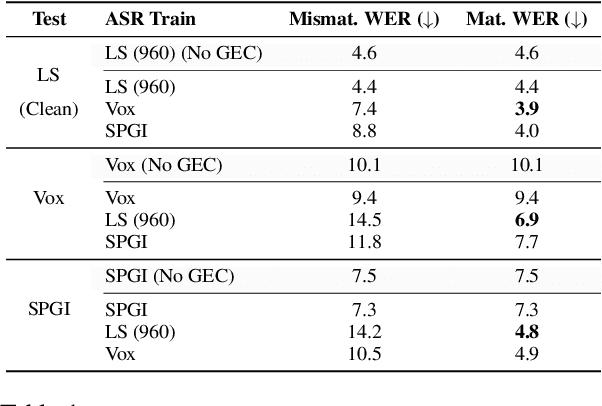
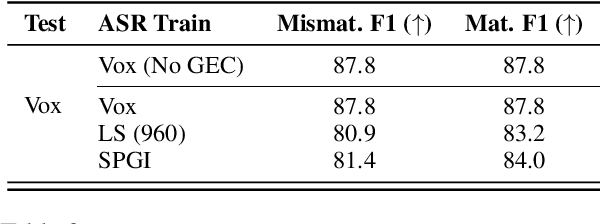
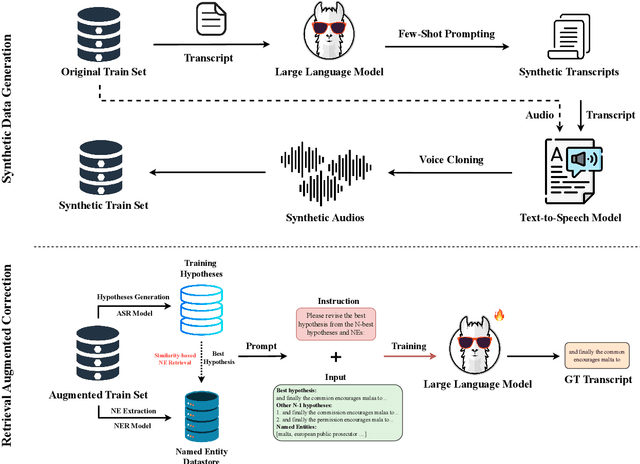
Generative Error Correction (GEC) has emerged as a powerful post-processing method to enhance the performance of Automatic Speech Recognition (ASR) systems. However, we show that GEC models struggle to generalize beyond the specific types of errors encountered during training, limiting their ability to correct new, unseen errors at test time, particularly in out-of-domain (OOD) scenarios. This phenomenon amplifies with named entities (NEs), where, in addition to insufficient contextual information or knowledge about the NEs, novel NEs keep emerging. To address these issues, we propose DARAG (Data- and Retrieval-Augmented Generative Error Correction), a novel approach designed to improve GEC for ASR in in-domain (ID) and OOD scenarios. We augment the GEC training dataset with synthetic data generated by prompting LLMs and text-to-speech models, thereby simulating additional errors from which the model can learn. For OOD scenarios, we simulate test-time errors from new domains similarly and in an unsupervised fashion. Additionally, to better handle named entities, we introduce retrieval-augmented correction by augmenting the input with entities retrieved from a database. Our approach is simple, scalable, and both domain- and language-agnostic. We experiment on multiple datasets and settings, showing that DARAG outperforms all our baselines, achieving 8\% -- 30\% relative WER improvements in ID and 10\% -- 33\% improvements in OOD settings.
Towards Unified Facial Action Unit Recognition Framework by Large Language Models
Sep 13, 2024



Facial Action Units (AUs) are of great significance in the realm of affective computing. In this paper, we propose AU-LLaVA, the first unified AU recognition framework based on the Large Language Model (LLM). AU-LLaVA consists of a visual encoder, a linear projector layer, and a pre-trained LLM. We meticulously craft the text descriptions and fine-tune the model on various AU datasets, allowing it to generate different formats of AU recognition results for the same input image. On the BP4D and DISFA datasets, AU-LLaVA delivers the most accurate recognition results for nearly half of the AUs. Our model achieves improvements of F1-score up to 11.4% in specific AU recognition compared to previous benchmark results. On the FEAFA dataset, our method achieves significant improvements over all 24 AUs compared to previous benchmark results. AU-LLaVA demonstrates exceptional performance and versatility in AU recognition.
MVLLaVA: An Intelligent Agent for Unified and Flexible Novel View Synthesis
Sep 11, 2024



This paper introduces MVLLaVA, an intelligent agent designed for novel view synthesis tasks. MVLLaVA integrates multiple multi-view diffusion models with a large multimodal model, LLaVA, enabling it to handle a wide range of tasks efficiently. MVLLaVA represents a versatile and unified platform that adapts to diverse input types, including a single image, a descriptive caption, or a specific change in viewing azimuth, guided by language instructions for viewpoint generation. We carefully craft task-specific instruction templates, which are subsequently used to fine-tune LLaVA. As a result, MVLLaVA acquires the capability to generate novel view images based on user instructions, demonstrating its flexibility across diverse tasks. Experiments are conducted to validate the effectiveness of MVLLaVA, demonstrating its robust performance and versatility in tackling diverse novel view synthesis challenges.