 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Speech Naturalness Predictor
Mar 02, 2026Evaluation of conversational naturalness is essential for developing human-like speech agents. However, existing speech naturalness predictors are often designed to assess utterances from a single speaker, failing to capture conversation-level naturalness qualities. In this paper, we present a framework for an automatic naturalness predictor for two-speaker, multi-turn conversations. We first show that existing naturalness estimators have low, or sometimes even negative, correlations with conversational naturalness, based on conversational recordings annotated with human ratings. We then propose a dual-channel naturalness estimator, in which we investigate multiple pre-trained encoders with data augmentation. Our proposed model achieves substantially higher correlation with human judgments compared to existing naturalness predictors for both in-domain and out-of-domain conditions.
GSRM: Generative Speech Reward Model for Speech RLHF
Feb 14, 2026Recent advances in speech language models, such as GPT-4o Voice Mode and Gemini Live, have demonstrated promising speech generation capabilities. Nevertheless, the aesthetic naturalness of the synthesized audio still lags behind that of human speech. Enhancing generation quality requires a reliable evaluator of speech naturalness. However, existing naturalness evaluators typically regress raw audio to scalar scores, offering limited interpretability of the evaluation and moreover fail to generalize to speech across different taxonomies. Inspired by recent advances in generative reward modeling, we propose the Generative Speech Reward Model (GSRM), a reasoning-centric reward model tailored for speech. The GSRM is trained to decompose speech naturalness evaluation into an interpretable acoustic feature extraction stage followed by feature-grounded chain-of-thought reasoning, enabling explainable judgments. To achieve this, we curated a large-scale human feedback dataset comprising 31k expert ratings and an out-of-domain benchmark of real-world user-assistant speech interactions. Experiments show that GSRM substantially outperforms existing speech naturalness predictors, achieving model-human correlation of naturalness score prediction that approaches human inter-rater consistency. We further show how GSRM can improve the naturalness of speech LLM generations by serving as an effective verifier for online RLHF.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Transcribing and Translating, Fast and Slow: Joint Speech Translation and Recognition
Dec 19, 2024We propose the joint speech translation and recognition (JSTAR) model that leverages the fast-slow cascaded encoder architecture for simultaneous end-to-end automatic speech recognition (ASR) and speech translation (ST). The model is transducer-based and uses a multi-objective training strategy that optimizes both ASR and ST objectives simultaneously. This allows JSTAR to produce high-quality streaming ASR and ST results. We apply JSTAR in a bilingual conversational speech setting with smart-glasses, where the model is also trained to distinguish speech from different directions corresponding to the wearer and a conversational partner. Different model pre-training strategies are studied to further improve results, including training of a transducer-based streaming machine translation (MT) model for the first time and applying it for parameter initialization of JSTAR. We demonstrate superior performances of JSTAR compared to a strong cascaded ST model in both BLEU scores and latency.
Textless Streaming Speech-to-Speech Translation using Semantic Speech Tokens
Oct 04, 2024



Cascaded speech-to-speech translation systems often suffer from the error accumulation problem and high latency, which is a result of cascaded modules whose inference delays accumulate. In this paper, we propose a transducer-based speech translation model that outputs discrete speech tokens in a low-latency streaming fashion. This approach eliminates the need for generating text output first, followed by machine translation (MT) and text-to-speech (TTS) systems. The produced speech tokens can be directly used to generate a speech signal with low latency by utilizing an acoustic language model (LM) to obtain acoustic tokens and an audio codec model to retrieve the waveform. Experimental results show that the proposed method outperforms other existing approaches and achieves state-of-the-art results for streaming translation in terms of BLEU, average latency, and BLASER 2.0 scores for multiple language pairs using the CVSS-C dataset as a benchmark.
Frozen Large Language Models Can Perceive Paralinguistic Aspects of Speech
Oct 02, 2024



As speech becomes an increasingly common modality for interacting with large language models (LLMs), it is becoming desirable to develop systems where LLMs can take into account users' emotions or speaking styles when providing their responses. In this work, we study the potential of an LLM to understand these aspects of speech without fine-tuning its weights. To do this, we utilize an end-to-end system with a speech encoder; the encoder is trained to produce token embeddings such that the LLM's response to an expressive speech prompt is aligned with its response to a semantically matching text prompt where the speaker's emotion has also been specified. We find that this training framework allows the encoder to generate tokens that capture both semantic and paralinguistic information in speech and effectively convey it to the LLM, even when the LLM remains completely frozen. We also explore training on additional emotion and style-related response alignment tasks, finding that they further increase the amount of paralinguistic information explicitly captured in the speech tokens. Experiments demonstrate that our system is able to produce higher quality and more empathetic responses to expressive speech prompts compared to several baselines.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Speech ReaLLM -- Real-time Streaming Speech Recognition with Multimodal LLMs by Teaching the Flow of Time
Jun 13, 2024We introduce Speech ReaLLM, a new ASR architecture that marries "decoder-only" ASR with the RNN-T to make multimodal LLM architectures capable of real-time streaming. This is the first "decoder-only" ASR architecture designed to handle continuous audio without explicit end-pointing. Speech ReaLLM is a special case of the more general ReaLLM ("real-time LLM") approach, also introduced here for the first time. The idea is inspired by RNN-T: Instead of generating a response only at the end of a user prompt, generate after every input token received in real time (it is often empty). On Librispeech "test", an 80M Speech ReaLLM achieves WERs of 3.0% and 7.4% in real time (without an external LM or auxiliary loss). This is only slightly above a 3x larger Attention-Encoder-Decoder baseline. We also show that this way, an LLM architecture can learn to represent and reproduce the flow of time; and that a pre-trained 7B LLM can be fine-tuned to do reasonably well on this task.
COSMIC: Data Efficient Instruction-tuning For Speech In-Context Learning
Nov 03, 2023



We present a data and cost efficient way of incorporating the speech modality into a large language model (LLM). The resulting multi-modal LLM is a COntextual Speech Model with Instruction-following/in-context-learning Capabilities - COSMIC. Speech comprehension test question-answer (SQA) pairs are generated using GPT-3.5 based on the speech transcriptions as a part of the supervision for the instruction tuning. With fewer than 20M trainable parameters and as little as 450 hours of English speech data for SQA generation, COSMIC exhibits emergent instruction-following and in-context learning capabilities in speech-to-text tasks. The model is able to follow the given text instructions to generate text response even on the unseen EN$\to$X speech-to-text translation (S2TT) task with zero-shot setting. We evaluate the model's in-context learning via various tasks such as EN$\to$X S2TT and few-shot domain adaptation. And instruction-following capabilities are evaluated through a contextual biasing benchmark. Our results demonstrate the efficacy of the proposed low cost recipe for building a speech LLM and that with the new instruction-tuning data.
Leveraging Timestamp Information for Serialized Joint Streaming Recognition and Translation
Oct 23, 2023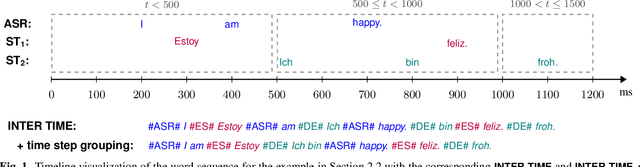
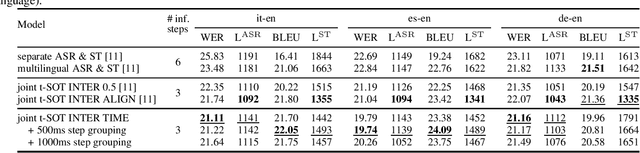
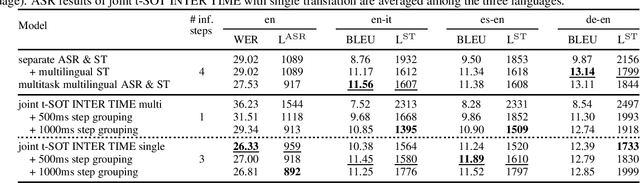
The growing need for instant spoken language transcription and translation is driven by increased global communication and cross-lingual interactions. This has made offering translations in multiple languages essential for user applications. Traditional approaches to automatic speech recognition (ASR) and speech translation (ST) have often relied on separate systems, leading to inefficiencies in computational resources, and increased synchronization complexity in real time. In this paper, we propose a streaming Transformer-Transducer (T-T) model able to jointly produce many-to-one and one-to-many transcription and translation using a single decoder. We introduce a novel method for joint token-level serialized output training based on timestamp information to effectively produce ASR and ST outputs in the streaming setting. Experiments on {it,es,de}->en prove the effectiveness of our approach, enabling the generation of one-to-many joint outputs with a single decoder for the first time.