 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavLLM: Towards Robust and Adaptive Speech Large Language Model
Mar 31, 2024The recent advancements in large language models (LLMs) have revolutionized the field of natural language processing, progressively broadening their scope to multimodal perception and generation. However, effectively integrating listening capabilities into LLMs poses significant challenges, particularly with respect to generalizing across varied contexts and executing complex auditory tasks. In this work, we introduce WavLLM, a robust and adaptive speech large language model with dual encoders, and a prompt-aware LoRA weight adapter, optimized by a two-stage curriculum learning approach. Leveraging dual encoders, we decouple different types of speech information, utilizing a Whisper encoder to process the semantic content of speech, and a WavLM encoder to capture the unique characteristics of the speaker's identity. Within the curriculum learning framework, WavLLM first builds its foundational capabilities by optimizing on mixed elementary single tasks, followed by advanced multi-task training on more complex tasks such as combinations of the elementary tasks. To enhance the flexibility and adherence to different tasks and instructions, a prompt-aware LoRA weight adapter is introduced in the second advanced multi-task training stage. We validate the proposed model on universal speech benchmarks including tasks such as ASR, ST, SV, ER, and also apply it to specialized datasets like Gaokao English listening comprehension set for SQA, and speech Chain-of-Thought (CoT) evaluation set. Experiments demonstrate that the proposed model achieves state-of-the-art performance across a range of speech tasks on the same model size, exhibiting robust generalization capabilities in executing complex tasks using CoT approach. Furthermore, our model successfully completes Gaokao tasks without specialized training. The codes, models, audio, and Gaokao evaluation set can be accessed at \url{aka.ms/wavllm}.
On decoder-only architecture for speech-to-text and large language model integration
Jul 14, 2023Large language models (LLMs) have achieved remarkable success in the field of natural language processing, enabling better human-computer interaction using natural language. However, the seamless integration of speech signals into LLMs has not been explored well. The "decoder-only" architecture has also not been well studied for speech processing tasks. In this research, we introduce Speech-LLaMA, a novel approach that effectively incorporates acoustic information into text-based large language models. Our method leverages Connectionist Temporal Classification and a simple audio encoder to map the compressed acoustic features to the continuous semantic space of the LLM. In addition, we further probe the decoder-only architecture for speech-to-text tasks by training a smaller scale randomly initialized speech-LLaMA model from speech-text paired data alone. We conduct experiments on multilingual speech-to-text translation tasks and demonstrate a significant improvement over strong baselines, highlighting the potential advantages of decoder-only models for speech-to-text conversion.
Code-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023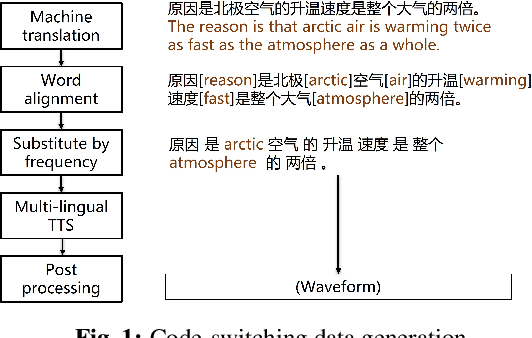
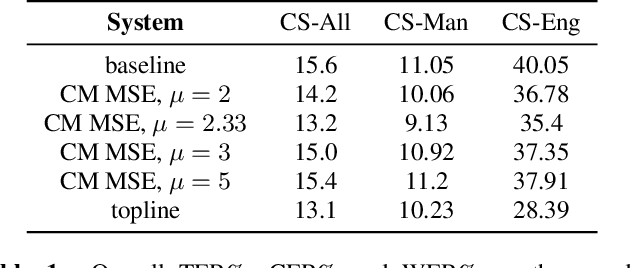
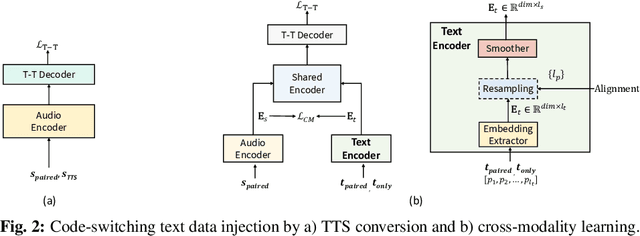

Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.
FoundationTTS: Text-to-Speech for ASR Customization with Generative Language Model
Mar 08, 2023Neural text-to-speech (TTS) generally consists of cascaded architecture with separately optimized acoustic model and vocoder, or end-to-end architecture with continuous mel-spectrograms or self-extracted speech frames as the intermediate representations to bridge acoustic model and vocoder, which suffers from two limitations: 1) the continuous acoustic frames are hard to predict with phoneme only, and acoustic information like duration or pitch is also needed to solve the one-to-many problem, which is not easy to scale on large scale and noise datasets; 2) to achieve diverse speech output based on continuous speech features, complex VAE or flow-based models are usually required. In this paper, we propose FoundationTTS, a new speech synthesis system with a neural audio codec for discrete speech token extraction and waveform reconstruction and a large language model for discrete token generation from linguistic (phoneme) tokens. Specifically, 1) we propose a hierarchical codec network based on vector-quantized auto-encoders with adversarial training (VQ-GAN), which first extracts continuous frame-level speech representations with fine-grained codec, and extracts a discrete token from each continuous speech frame with coarse-grained codec; 2) we jointly optimize speech token, linguistic tokens, speaker token together with a large language model and predict the discrete speech tokens autoregressively. Experiments show that FoundationTTS achieves a MOS gain of +0.14 compared to the baseline system. In ASR customization tasks, our method achieves 7.09\% and 10.35\% WERR respectively over two strong customized ASR baselines.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023



We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.
Building a great multi-lingual teacher with sparsely-gated mixture of experts for speech recognition
Jan 04, 2022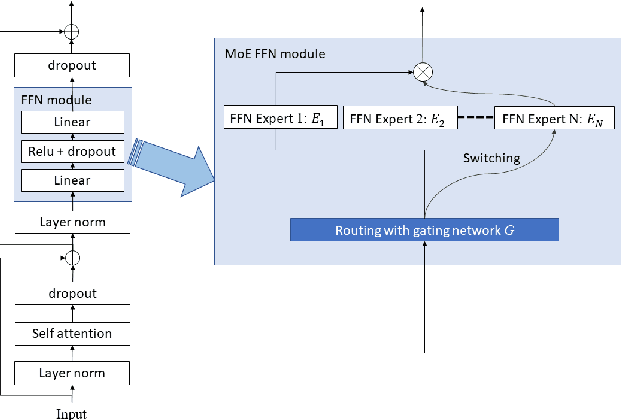
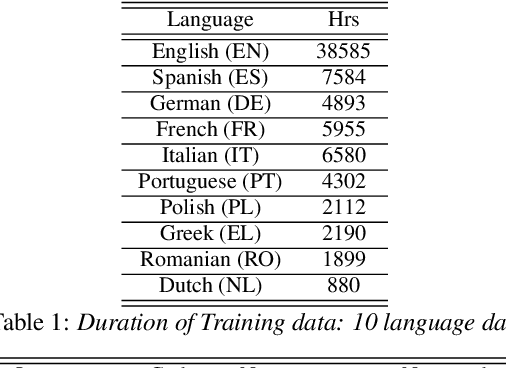
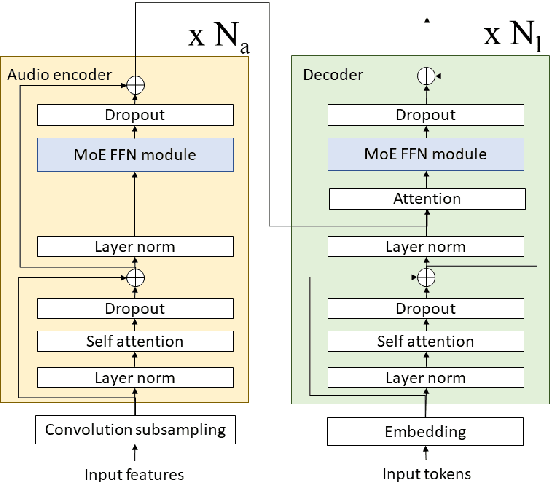
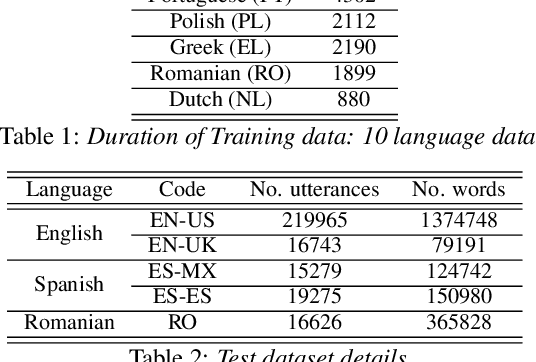
The sparsely-gated Mixture of Experts (MoE) can magnify a network capacity with a little computational complexity. In this work, we investigate how multi-lingual Automatic Speech Recognition (ASR) networks can be scaled up with a simple routing algorithm in order to achieve better accuracy. More specifically, we apply the sparsely-gated MoE technique to two types of networks: Sequence-to-Sequence Transformer (S2S-T) and Transformer Transducer (T-T). We demonstrate through a set of ASR experiments on multiple language data that the MoE networks can reduce the relative word error rates by 16.3% and 4.6% with the S2S-T and T-T, respectively. Moreover, we thoroughly investigate the effect of the MoE on the T-T architecture in various conditions: streaming mode, non-streaming mode, the use of language ID and the label decoder with the MoE.
FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition
Oct 18, 2021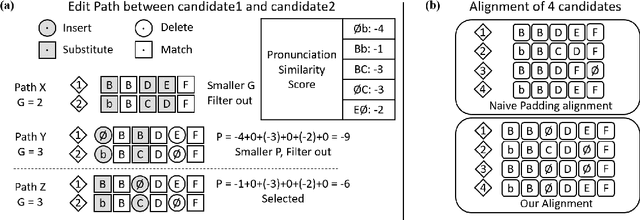
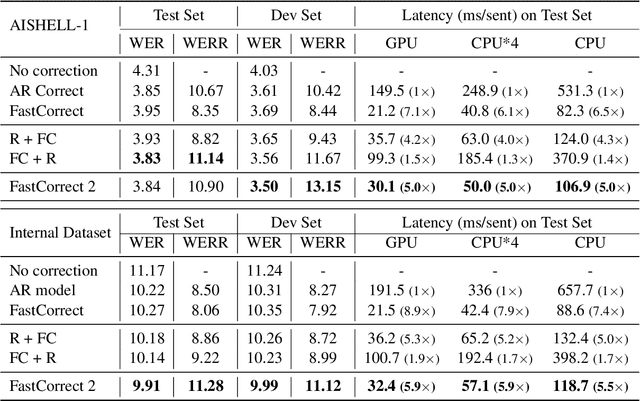
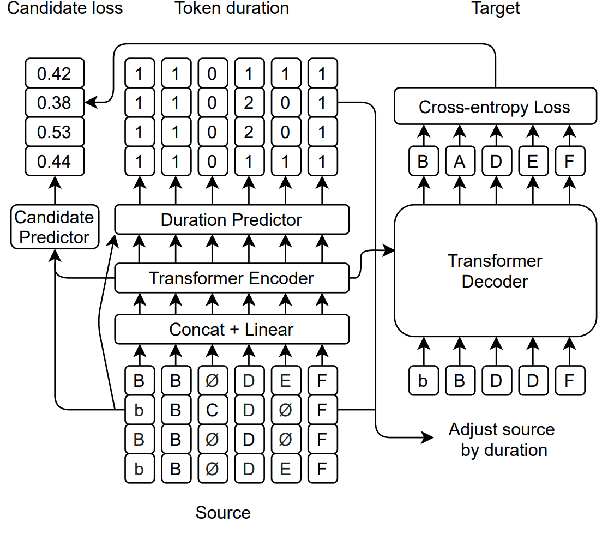
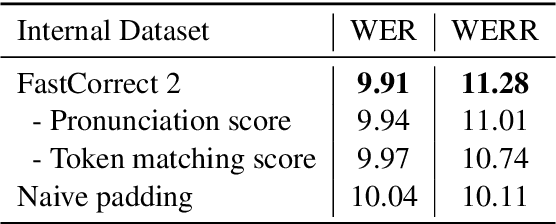
Error correction is widely used in automatic speech recognition (ASR) to post-process the generated sentence, and can further reduce the word error rate (WER). Although multiple candidates are generated by an ASR system through beam search, current error correction approaches can only correct one sentence at a time, failing to leverage the voting effect from multiple candidates to better detect and correct error tokens. In this work, we propose FastCorrect 2, an error correction model that takes multiple ASR candidates as input for better correction accuracy. FastCorrect 2 adopts non-autoregressive generation for fast inference, which consists of an encoder that processes multiple source sentences and a decoder that generates the target sentence in parallel from the adjusted source sentence, where the adjustment is based on the predicted duration of each source token. However, there are some issues when handling multiple source sentences. First, it is non-trivial to leverage the voting effect from multiple source sentences since they usually vary in length. Thus, we propose a novel alignment algorithm to maximize the degree of token alignment among multiple sentences in terms of token and pronunciation similarity. Second, the decoder can only take one adjusted source sentence as input, while there are multiple source sentences. Thus, we develop a candidate predictor to detect the most suitable candidate for the decoder. Experiments on our inhouse dataset and AISHELL-1 show that FastCorrect 2 can further reduce the WER over the previous correction model with single candidate by 3.2% and 2.6%, demonstrating the effectiveness of leveraging multiple candidates in ASR error correction. FastCorrect 2 achieves better performance than the cascaded re-scoring and correction pipeline and can serve as a unified post-processing module for ASR.
FastCorrect: Fast Error Correction with Edit Alignment for Automatic Speech Recognition
Jun 03, 2021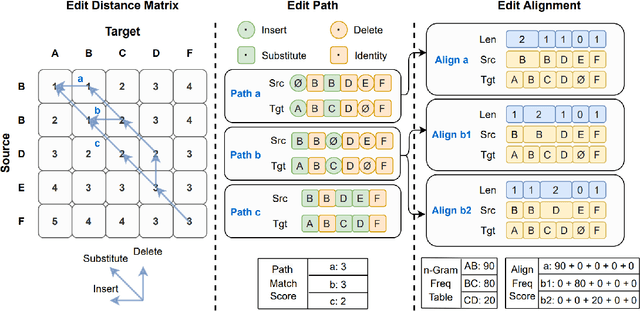
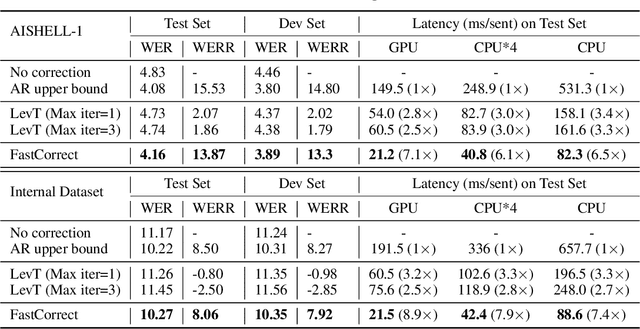
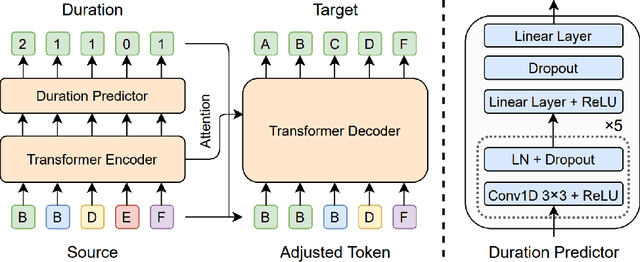
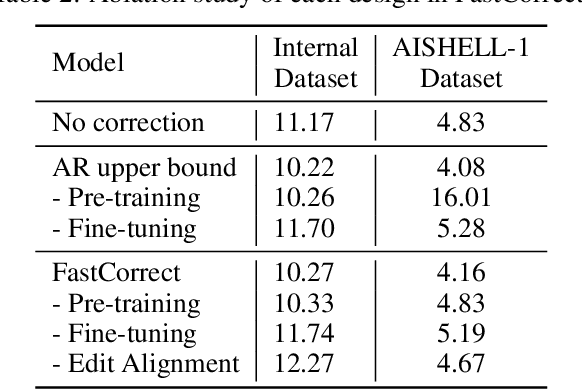
Error correction techniques have been used to refine the output sentences from automatic speech recognition (ASR) models and achieve a lower word error rate (WER) than original ASR outputs. Previous works usually use a sequence-to-sequence model to correct an ASR output sentence autoregressively, which causes large latency and cannot be deployed in online ASR services. A straightforward solution to reduce latency, inspired by non-autoregressive (NAR) neural machine translation, is to use an NAR sequence generation model for ASR error correction, which, however, comes at the cost of significantly increased ASR error rate. In this paper, observing distinctive error patterns and correction operations (i.e., insertion, deletion, and substitution) in ASR, we propose FastCorrect, a novel NAR error correction model based on edit alignment. In training, FastCorrect aligns each source token from an ASR output sentence to the target tokens from the corresponding ground-truth sentence based on the edit distance between the source and target sentences, and extracts the number of target tokens corresponding to each source token during edition/correction, which is then used to train a length predictor and to adjust the source tokens to match the length of the target sentence for parallel generation. In inference, the token number predicted by the length predictor is used to adjust the source tokens for target sequence generation. Experiments on the public AISHELL-1 dataset and an internal industrial-scale ASR dataset show the effectiveness of FastCorrect for ASR error correction: 1) it speeds up the inference by 6-9 times and maintains the accuracy (8-14% WER reduction) compared with the autoregressive correction model; and 2) it outperforms the popular NAR models adopted in neural machine translation and text edition by a large margin.