 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
Disentangled Representation with Cross Experts Covariance Loss for Multi-Domain Recommendation
May 21, 2024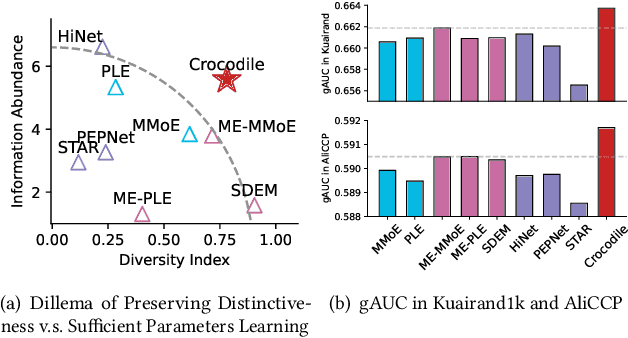

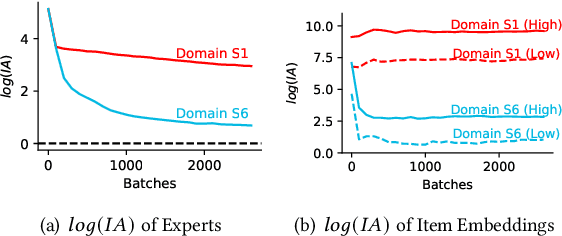
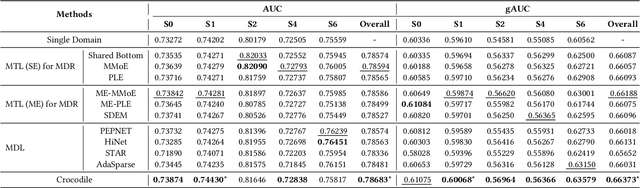
Multi-domain learning (MDL) has emerged as a prominent research area aimed at enhancing the quality of personalized services. The key challenge in MDL lies in striking a balance between learning commonalities across domains while preserving the distinct characteristics of each domain. However, this gives rise to a challenging dilemma. On one hand, a model needs to leverage domain-specific modules, such as experts or embeddings, to preserve the uniqueness of each domain. On the other hand, due to the long-tailed distributions observed in real-world domains, some tail domains may lack sufficient samples to fully learn their corresponding modules. Unfortunately, existing approaches have not adequately addressed this dilemma. To address this issue, we propose a novel model called Crocodile, which stands for Cross-experts Covariance Loss for Disentangled Learning. Crocodile adopts a multi-embedding paradigm to facilitate model learning and employs a Covariance Loss on these embeddings to disentangle them. This disentanglement enables the model to capture diverse user interests across domains effectively. Additionally, we introduce a novel gating mechanism to further enhance the capabilities of Crocodile. Through empirical analysis, we demonstrate that our proposed method successfully resolves these two challenges and outperforms all state-of-the-art methods on publicly available datasets. We firmly believe that the analytical perspectives and design concept of disentanglement presented in our work can pave the way for future research in the field of MDL.
Ad Recommendation in a Collapsed and Entangled World
Feb 22, 2024



In this paper, we present an industry ad recommendation system, paying attention to the challenges and practices of learning appropriate representations. Our study begins by showcasing our approaches to preserving priors when encoding features of diverse types into embedding representations. Specifically, we address sequence features, numeric features, pre-trained embedding features, as well as sparse ID features. Moreover, we delve into two pivotal challenges associated with feature representation: the dimensional collapse of embeddings and the interest entanglement across various tasks or scenarios. Subsequently, we propose several practical approaches to effectively tackle these two challenges. We then explore several training techniques to facilitate model optimization, reduce bias, and enhance exploration. Furthermore, we introduce three analysis tools that enable us to comprehensively study feature correlation, dimensional collapse, and interest entanglement. This work builds upon the continuous efforts of Tencent's ads recommendation team in the last decade. It not only summarizes general design principles but also presents a series of off-the-shelf solutions and analysis tools. The reported performance is based on our online advertising platform, which handles hundreds of billions of requests daily, serving millions of ads to billions of users.
Code-Switching Text Generation and Injection in Mandarin-English ASR
Mar 20, 2023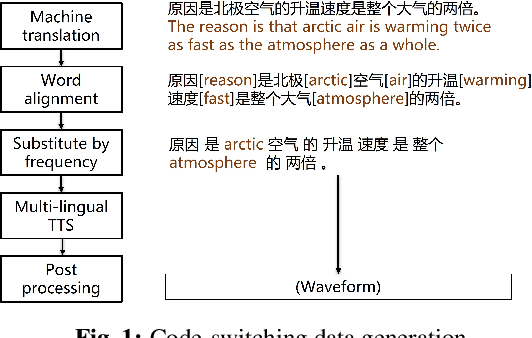
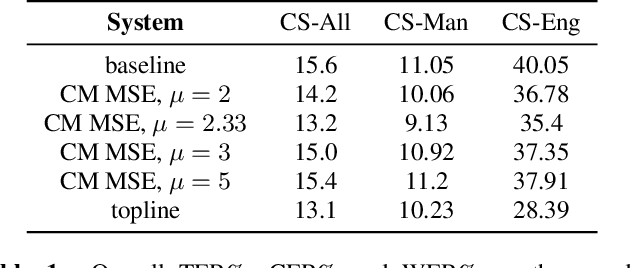
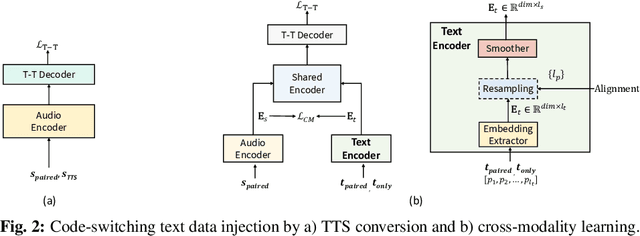

Code-switching speech refers to a means of expression by mixing two or more languages within a single utterance. Automatic Speech Recognition (ASR) with End-to-End (E2E) modeling for such speech can be a challenging task due to the lack of data. In this study, we investigate text generation and injection for improving the performance of an industry commonly-used streaming model, Transformer-Transducer (T-T), in Mandarin-English code-switching speech recognition. We first propose a strategy to generate code-switching text data and then investigate injecting generated text into T-T model explicitly by Text-To-Speech (TTS) conversion or implicitly by tying speech and text latent spaces. Experimental results on the T-T model trained with a dataset containing 1,800 hours of real Mandarin-English code-switched speech show that our approaches to inject generated code-switching text significantly boost the performance of T-T models, i.e., 16% relative Token-based Error Rate (TER) reduction averaged on three evaluation sets, and the approach of tying speech and text latent spaces is superior to that of TTS conversion on the evaluation set which contains more homogeneous data with the training set.
AdaTask: A Task-aware Adaptive Learning Rate Approach to Multi-task Learning
Nov 28, 2022



Multi-task learning (MTL) models have demonstrated impressive results in computer vision, natural language processing, and recommender systems. Even though many approaches have been proposed, how well these approaches balance different tasks on each parameter still remains unclear. In this paper, we propose to measure the task dominance degree of a parameter by the total updates of each task on this parameter. Specifically, we compute the total updates by the exponentially decaying Average of the squared Updates (AU) on a parameter from the corresponding task.Based on this novel metric, we observe that many parameters in existing MTL methods, especially those in the higher shared layers, are still dominated by one or several tasks. The dominance of AU is mainly due to the dominance of accumulative gradients from one or several tasks. Motivated by this, we propose a Task-wise Adaptive learning rate approach, AdaTask in short, to separate the \emph{accumulative gradients} and hence the learning rate of each task for each parameter in adaptive learning rate approaches (e.g., AdaGrad, RMSProp, and Adam). Comprehensive experiments on computer vision and recommender system MTL datasets demonstrate that AdaTask significantly improves the performance of dominated tasks, resulting SOTA average task-wise performance. Analysis on both synthetic and real-world datasets shows AdaTask balance parameters in every shared layer well.
On Provably Robust Meta-Bayesian Optimization
Jun 16, 2022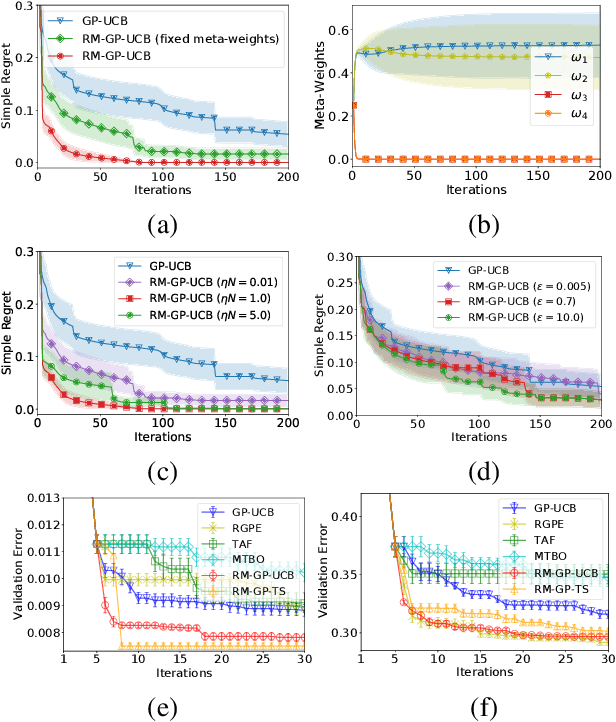
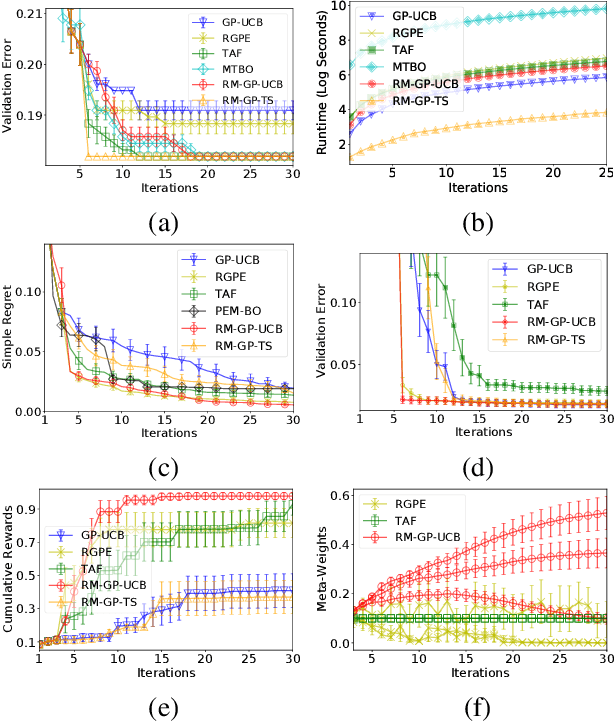
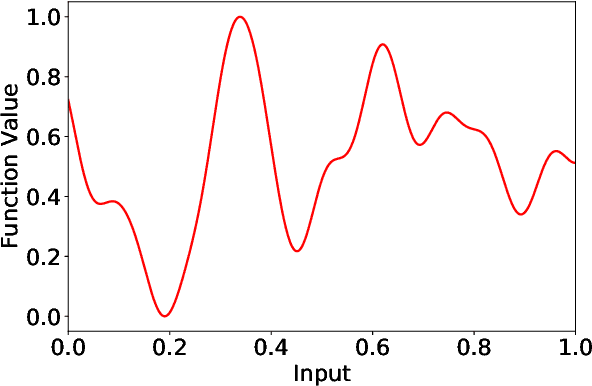
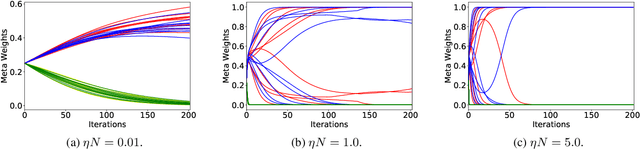
Bayesian optimization (BO) has become popular for sequential optimization of black-box functions. When BO is used to optimize a target function, we often have access to previous evaluations of potentially related functions. This begs the question as to whether we can leverage these previous experiences to accelerate the current BO task through meta-learning (meta-BO), while ensuring robustness against potentially harmful dissimilar tasks that could sabotage the convergence of BO. This paper introduces two scalable and provably robust meta-BO algorithms: robust meta-Gaussian process-upper confidence bound (RM-GP-UCB) and RM-GP-Thompson sampling (RM-GP-TS). We prove that both algorithms are asymptotically no-regret even when some or all previous tasks are dissimilar to the current task, and show that RM-GP-UCB enjoys a better theoretical robustness than RM-GP-TS. We also exploit the theoretical guarantees to optimize the weights assigned to individual previous tasks through regret minimization via online learning, which diminishes the impact of dissimilar tasks and hence further enhances the robustness. Empirical evaluations show that (a) RM-GP-UCB performs effectively and consistently across various applications, and (b) RM-GP-TS, despite being less robust than RM-GP-UCB both in theory and in practice, performs competitively in some scenarios with less dissimilar tasks and is more computationally efficient.
Convolutional Normalizing Flows for Deep Gaussian Processes
Apr 23, 2021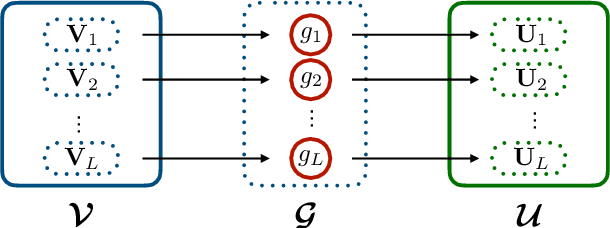
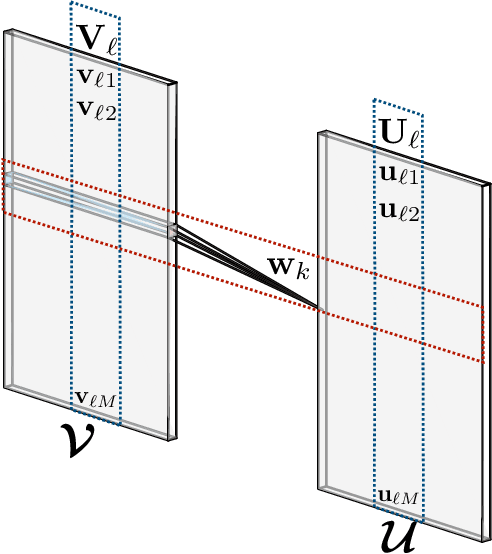
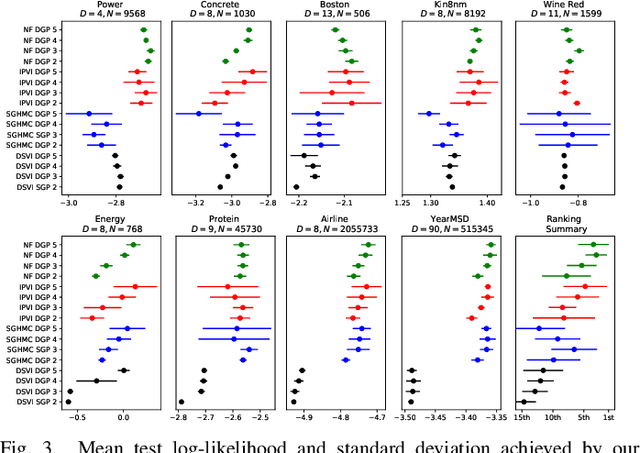
Deep Gaussian processes (DGPs), a hierarchical composition of GP models, have successfully boosted the expressive power of their single-layer counterpart. However, it is impossible to perform exact inference in DGPs, which has motivated the recent development of variational inference-based methods. Unfortunately, either these methods yield a biased posterior belief or it is difficult to evaluate their convergence. This paper introduces a new approach for specifying flexible, arbitrarily complex, and scalable approximate posterior distributions. The posterior distribution is constructed through a normalizing flow (NF) which transforms a simple initial probability into a more complex one through a sequence of invertible transformations. Moreover, a novel convolutional normalizing flow (CNF) is developed to improve the time efficiency and capture dependency between layers. Empirical evaluation shows that CNF DGP outperforms the state-of-the-art approximation methods for DGPs.
Implicit Posterior Variational Inference for Deep Gaussian Processes
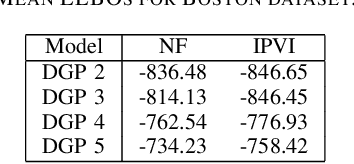
Oct 26, 2019
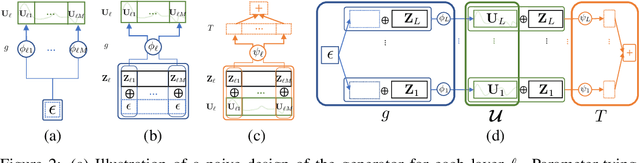
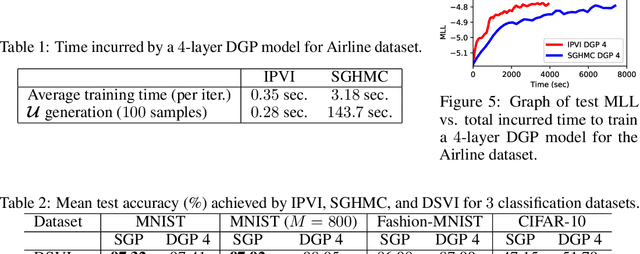
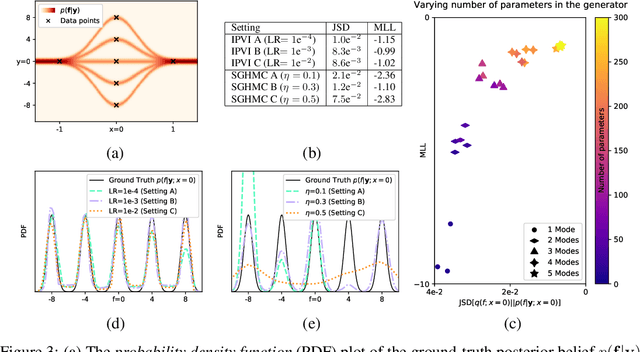
A multi-layer deep Gaussian process (DGP) model is a hierarchical composition of GP models with a greater expressive power. Exact DGP inference is intractable, which has motivated the recent development of deterministic and stochastic approximation methods. Unfortunately, the deterministic approximation methods yield a biased posterior belief while the stochastic one is computationally costly. This paper presents an implicit posterior variational inference (IPVI) framework for DGPs that can ideally recover an unbiased posterior belief and still preserve time efficiency. Inspired by generative adversarial networks, our IPVI framework achieves this by casting the DGP inference problem as a two-player game in which a Nash equilibrium, interestingly, coincides with an unbiased posterior belief. This consequently inspires us to devise a best-response dynamics algorithm to search for a Nash equilibrium (i.e., an unbiased posterior belief). Empirical evaluation shows that IPVI outperforms the state-of-the-art approximation methods for DGPs.
Stochastic Variational Inference for Fully Bayesian Sparse Gaussian Process Regression Models
Nov 01, 2017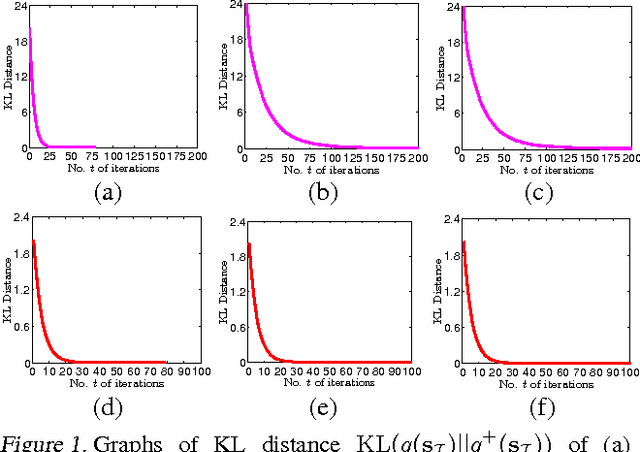

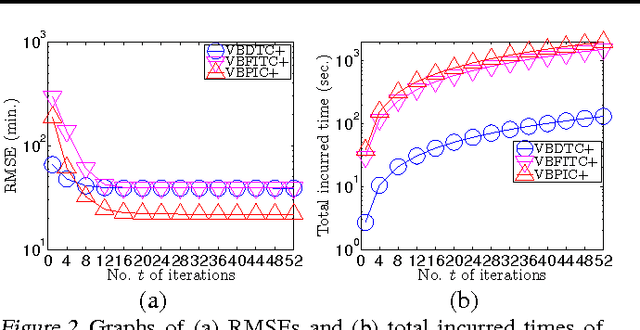
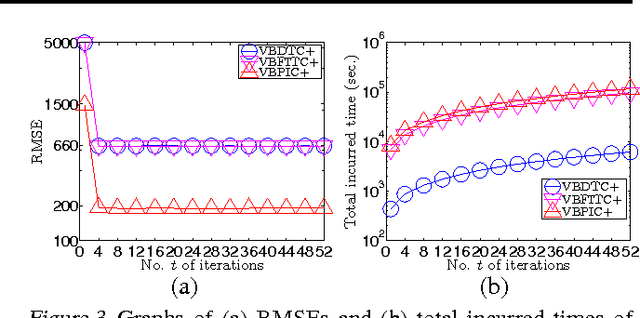
This paper presents a novel variational inference framework for deriving a family of Bayesian sparse Gaussian process regression (SGPR) models whose approximations are variationally optimal with respect to the full-rank GPR model enriched with various corresponding correlation structures of the observation noises. Our variational Bayesian SGPR (VBSGPR) models jointly treat both the distributions of the inducing variables and hyperparameters as variational parameters, which enables the decomposability of the variational lower bound that in turn can be exploited for stochastic optimization. Such a stochastic optimization involves iteratively following the stochastic gradient of the variational lower bound to improve its estimates of the optimal variational distributions of the inducing variables and hyperparameters (and hence the predictive distribution) of our VBSGPR models and is guaranteed to achieve asymptotic convergence to them. We show that the stochastic gradient is an unbiased estimator of the exact gradient and can be computed in constant time per iteration, hence achieving scalability to big data. We empirically evaluate the performance of our proposed framework on two real-world, massive datasets.