 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
SSKG Hub: An Expert-Guided Platform for LLM-Empowered Sustainability Standards Knowledge Graphs
Feb 28, 2026Sustainability disclosure standards (e.g., GRI, SASB, TCFD, IFRS S2) are comprehensive yet lengthy, terminology-dense, and highly cross-referential, hindering structured analysis and downstream use. We present SSKG Hub (Sustainability Standards Knowledge Graph Hub), a research prototype and interactive web platform that transforms standards into auditable knowledge graphs (KGs) through an LLM-centered, expert-guided pipeline. The system integrates automatic standard identification, configurable chunking, standard-specific prompting, robust triple parsing, and provenance-aware Neo4j storage with fine-grained audit metadata. LLM extraction produces a provenance-linked Draft KG, which is reviewed, curated, and formally promoted to a Certified KG through meta-expert adjudication. A role-based governance framework covering read-only guest access, expert review and CRUD operations, meta-expert certification, and administrative oversight ensures traceability and accountability across draft and certified states. Beyond graph exploration and triple-level evidence tracing, SSKG Hub supports cross-KG fusion, KG-driven tasks, and dedicated modules for insights and curated resources. We validate the platform through a comprehensive expert-led KG review case study that demonstrates end-to-end curation and quality assurance. The web application is publicly available at www.sskg-hub.com.
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Dec 18, 2025Vision-Language-Action (VLA) models achieve strong generalization in robotic manipulation but remain largely reactive and 2D-centric, making them unreliable in tasks that require precise 3D reasoning. We propose GeoPredict, a geometry-aware VLA framework that augments a continuous-action policy with predictive kinematic and geometric priors. GeoPredict introduces a trajectory-level module that encodes motion history and predicts multi-step 3D keypoint trajectories of robot arms, and a predictive 3D Gaussian geometry module that forecasts workspace geometry with track-guided refinement along future keypoint trajectories. These predictive modules serve exclusively as training-time supervision through depth-based rendering, while inference requires only lightweight additional query tokens without invoking any 3D decoding. Experiments on RoboCasa Human-50, LIBERO, and real-world manipulation tasks show that GeoPredict consistently outperforms strong VLA baselines, especially in geometry-intensive and spatially demanding scenarios.
Large Foundation Model for Ads Recommendation
Aug 20, 2025


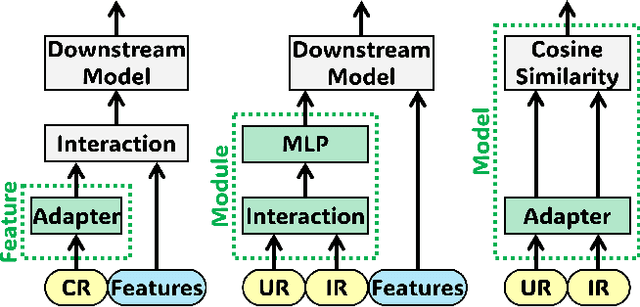
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025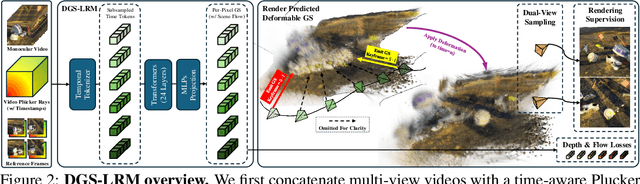
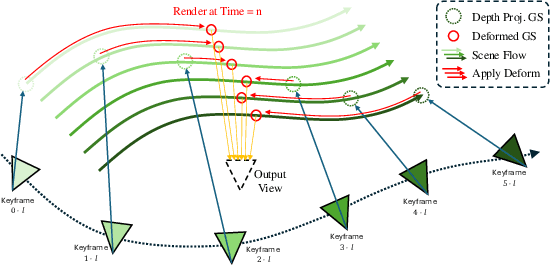
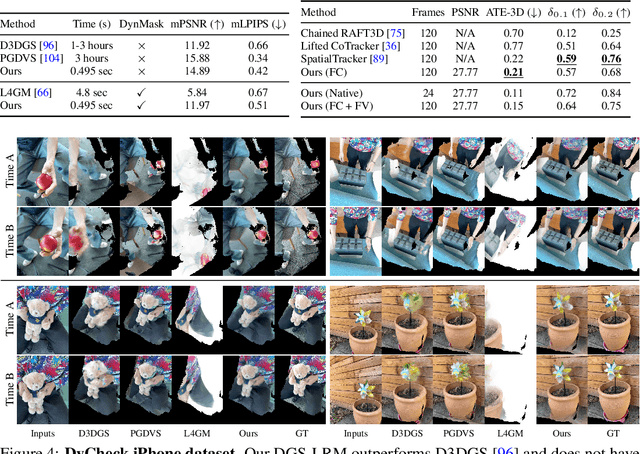

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Geometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
May 25, 2025


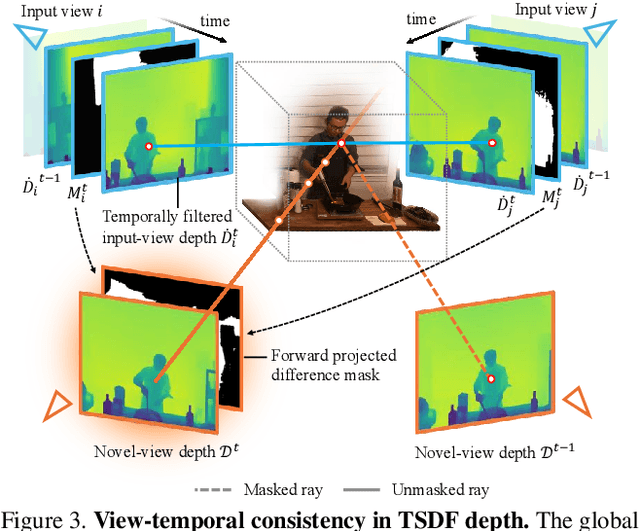
We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
LIRM: Large Inverse Rendering Model for Progressive Reconstruction of Shape, Materials and View-dependent Radiance Fields
Apr 28, 2025We present Large Inverse Rendering Model (LIRM), a transformer architecture that jointly reconstructs high-quality shape, materials, and radiance fields with view-dependent effects in less than a second. Our model builds upon the recent Large Reconstruction Models (LRMs) that achieve state-of-the-art sparse-view reconstruction quality. However, existing LRMs struggle to reconstruct unseen parts accurately and cannot recover glossy appearance or generate relightable 3D contents that can be consumed by standard Graphics engines. To address these limitations, we make three key technical contributions to build a more practical multi-view 3D reconstruction framework. First, we introduce an update model that allows us to progressively add more input views to improve our reconstruction. Second, we propose a hexa-plane neural SDF representation to better recover detailed textures, geometry and material parameters. Third, we develop a novel neural directional-embedding mechanism to handle view-dependent effects. Trained on a large-scale shape and material dataset with a tailored coarse-to-fine training scheme, our model achieves compelling results. It compares favorably to optimization-based dense-view inverse rendering methods in terms of geometry and relighting accuracy, while requiring only a fraction of the inference time.
LEADRE: Multi-Faceted Knowledge Enhanced LLM Empowered Display Advertisement Recommender System
Nov 21, 2024



Display advertising provides significant value to advertisers, publishers, and users. Traditional display advertising systems utilize a multi-stage architecture consisting of retrieval, coarse ranking, and final ranking. However, conventional retrieval methods rely on ID-based learning to rank mechanisms and fail to adequately utilize the content information of ads, which hampers their ability to provide diverse recommendation lists. To address this limitation, we propose leveraging the extensive world knowledge of LLMs. However, three key challenges arise when attempting to maximize the effectiveness of LLMs: "How to capture user interests", "How to bridge the knowledge gap between LLMs and advertising system", and "How to efficiently deploy LLMs". To overcome these challenges, we introduce a novel LLM-based framework called LLM Empowered Display ADvertisement REcommender system (LEADRE). LEADRE consists of three core modules: (1) The Intent-Aware Prompt Engineering introduces multi-faceted knowledge and designs intent-aware <Prompt, Response> pairs that fine-tune LLMs to generate ads tailored to users' personal interests. (2) The Advertising-Specific Knowledge Alignment incorporates auxiliary fine-tuning tasks and Direct Preference Optimization (DPO) to align LLMs with ad semantic and business value. (3) The Efficient System Deployment deploys LEADRE in an online environment by integrating both latency-tolerant and latency-sensitive service. Extensive offline experiments demonstrate the effectiveness of LEADRE and validate the contributions of individual modules. Online A/B test shows that LEADRE leads to a 1.57% and 1.17% GMV lift for serviced users on WeChat Channels and Moments separately. LEADRE has been deployed on both platforms, serving tens of billions of requests each day.
Towards Unifying Feature Interaction Models for Click-Through Rate Prediction
Nov 19, 2024



Modeling feature interactions plays a crucial role in accurately predicting click-through rates (CTR) in advertising systems. To capture the intricate patterns of interaction, many existing models employ matrix-factorization techniques to represent features as lower-dimensional embedding vectors, enabling the modeling of interactions as products between these embeddings. In this paper, we propose a general framework called IPA to systematically unify these models. Our framework comprises three key components: the Interaction Function, which facilitates feature interaction; the Layer Pooling, which constructs higher-level interaction layers; and the Layer Aggregator, which combines the outputs of all layers to serve as input for the subsequent classifier. We demonstrate that most existing models can be categorized within our framework by making specific choices for these three components. Through extensive experiments and a dimensional collapse analysis, we evaluate the performance of these choices. Furthermore, by leveraging the most powerful components within our framework, we introduce a novel model that achieves competitive results compared to state-of-the-art CTR models. PFL gets significant GMV lift during online A/B test in Tencent's advertising platform and has been deployed as the production model in several primary scenarios.
Rethinking Domain Adaptation and Generalization in the Era of CLIP
Jul 21, 2024



In recent studies on domain adaptation, significant emphasis has been placed on the advancement of learning shared knowledge from a source domain to a target domain. Recently, the large vision-language pre-trained model, i.e., CLIP has shown strong ability on zero-shot recognition, and parameter efficient tuning can further improve its performance on specific tasks. This work demonstrates that a simple domain prior boosts CLIP's zero-shot recognition in a specific domain. Besides, CLIP's adaptation relies less on source domain data due to its diverse pre-training dataset. Furthermore, we create a benchmark for zero-shot adaptation and pseudo-labeling based self-training with CLIP. Last but not least, we propose to improve the task generalization ability of CLIP from multiple unlabeled domains, which is a more practical and unique scenario. We believe our findings motivate a rethinking of domain adaptation benchmarks and the associated role of related algorithms in the era of CLIP.