 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
May 25, 2025


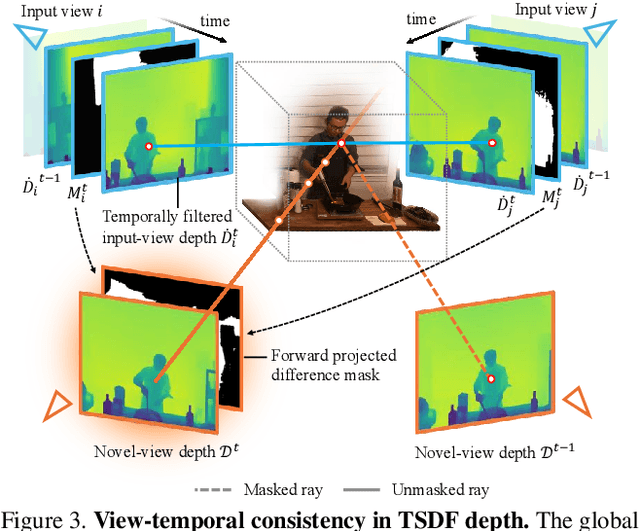
We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
HoloChrome: Polychromatic Illumination for Speckle Reduction in Holographic Near-Eye Displays
Oct 31, 2024Holographic displays hold the promise of providing authentic depth cues, resulting in enhanced immersive visual experiences for near-eye applications. However, current holographic displays are hindered by speckle noise, which limits accurate reproduction of color and texture in displayed images. We present HoloChrome, a polychromatic holographic display framework designed to mitigate these limitations. HoloChrome utilizes an ultrafast, wavelength-adjustable laser and a dual-Spatial Light Modulator (SLM) architecture, enabling the multiplexing of a large set of discrete wavelengths across the visible spectrum. By leveraging spatial separation in our dual-SLM setup, we independently manipulate speckle patterns across multiple wavelengths. This novel approach effectively reduces speckle noise through incoherent averaging achieved by wavelength multiplexing. Our method is complementary to existing speckle reduction techniques, offering a new pathway to address this challenge. Furthermore, the use of polychromatic illumination broadens the achievable color gamut compared to traditional three-color primary holographic displays. Our simulations and tabletop experiments validate that HoloChrome significantly reduces speckle noise and expands the color gamut. These advancements enhance the performance of holographic near-eye displays, moving us closer to practical, immersive next-generation visual experiences.
ReplaceAnything3D:Text-Guided 3D Scene Editing with Compositional Neural Radiance Fields
Jan 31, 2024We introduce ReplaceAnything3D model (RAM3D), a novel text-guided 3D scene editing method that enables the replacement of specific objects within a scene. Given multi-view images of a scene, a text prompt describing the object to replace, and a text prompt describing the new object, our Erase-and-Replace approach can effectively swap objects in the scene with newly generated content while maintaining 3D consistency across multiple viewpoints. We demonstrate the versatility of ReplaceAnything3D by applying it to various realistic 3D scenes, showcasing results of modified foreground objects that are well-integrated with the rest of the scene without affecting its overall integrity.
GauFRe: Gaussian Deformation Fields for Real-time Dynamic Novel View Synthesis
Dec 18, 2023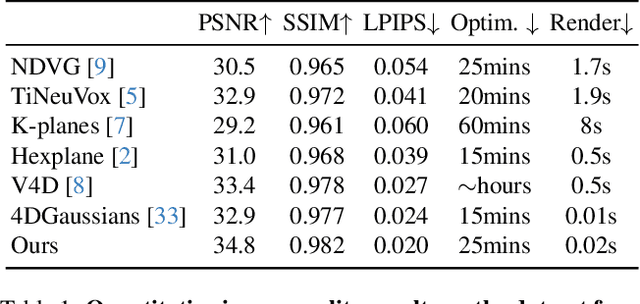
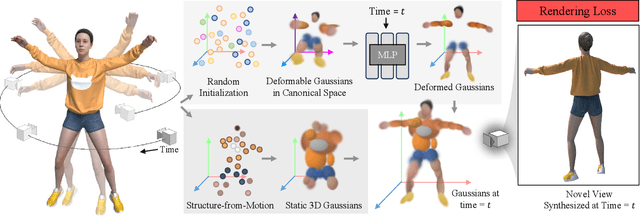
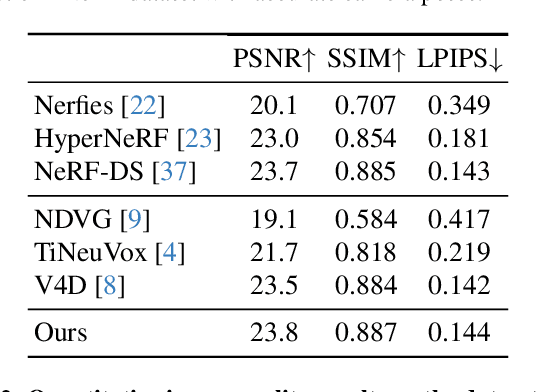
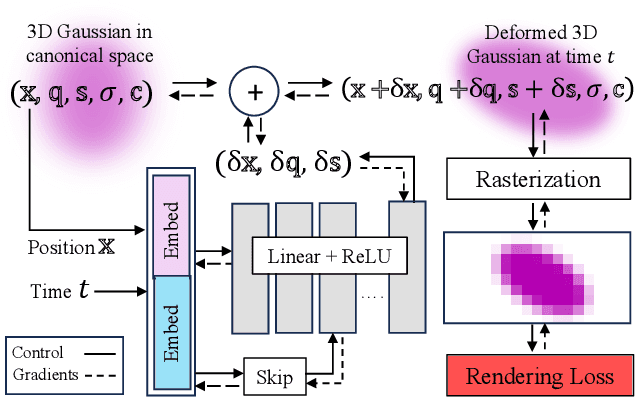
We propose a method for dynamic scene reconstruction using deformable 3D Gaussians that is tailored for monocular video. Building upon the efficiency of Gaussian splatting, our approach extends the representation to accommodate dynamic elements via a deformable set of Gaussians residing in a canonical space, and a time-dependent deformation field defined by a multi-layer perceptron (MLP). Moreover, under the assumption that most natural scenes have large regions that remain static, we allow the MLP to focus its representational power by additionally including a static Gaussian point cloud. The concatenated dynamic and static point clouds form the input for the Gaussian Splatting rasterizer, enabling real-time rendering. The differentiable pipeline is optimized end-to-end with a self-supervised rendering loss. Our method achieves results that are comparable to state-of-the-art dynamic neural radiance field methods while allowing much faster optimization and rendering. Project website: https://lynl7130.github.io/gaufre/index.html
Tiled Multiplane Images for Practical 3D Photography
Sep 25, 2023



The task of synthesizing novel views from a single image has useful applications in virtual reality and mobile computing, and a number of approaches to the problem have been proposed in recent years. A Multiplane Image (MPI) estimates the scene as a stack of RGBA layers, and can model complex appearance effects, anti-alias depth errors and synthesize soft edges better than methods that use textured meshes or layered depth images. And unlike neural radiance fields, an MPI can be efficiently rendered on graphics hardware. However, MPIs are highly redundant and require a large number of depth layers to achieve plausible results. Based on the observation that the depth complexity in local image regions is lower than that over the entire image, we split an MPI into many small, tiled regions, each with only a few depth planes. We call this representation a Tiled Multiplane Image (TMPI). We propose a method for generating a TMPI with adaptive depth planes for single-view 3D photography in the wild. Our synthesized results are comparable to state-of-the-art single-view MPI methods while having lower computational overhead.
Multisource Holography
Sep 19, 2023
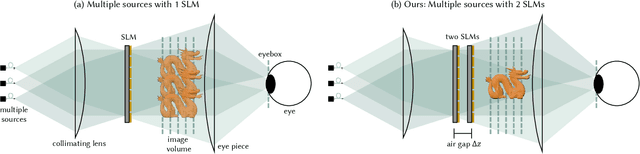
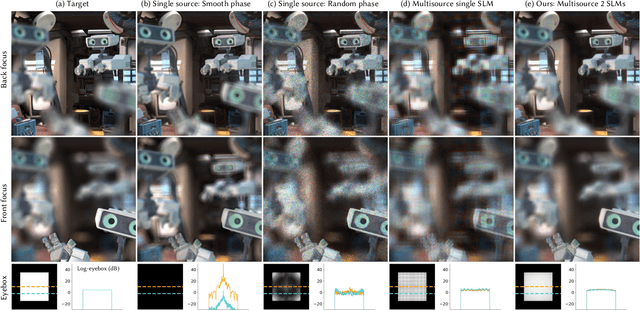
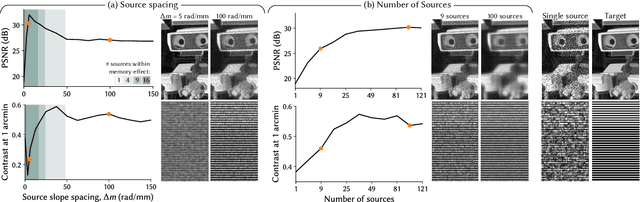
Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Stochastic Light Field Holography
Jul 12, 2023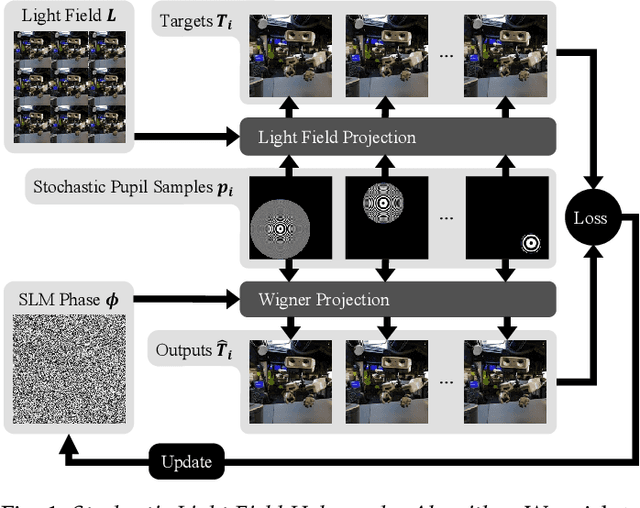


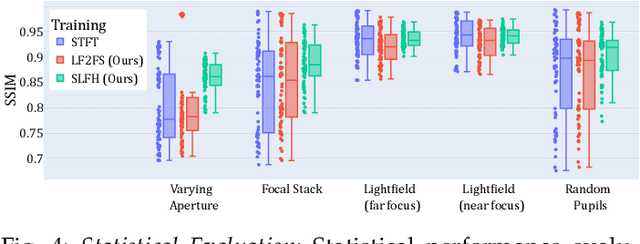
The Visual Turing Test is the ultimate goal to evaluate the realism of holographic displays. Previous studies have focused on addressing challenges such as limited \'etendue and image quality over a large focal volume, but they have not investigated the effect of pupil sampling on the viewing experience in full 3D holograms. In this work, we tackle this problem with a novel hologram generation algorithm motivated by matching the projection operators of incoherent Light Field and coherent Wigner Function light transport. To this end, we supervise hologram computation using synthesized photographs, which are rendered on-the-fly using Light Field refocusing from stochastically sampled pupil states during optimization. The proposed method produces holograms with correct parallax and focus cues, which are important for passing the Visual Turing Test. We validate that our approach compares favorably to state-of-the-art CGH algorithms that use Light Field and Focal Stack supervision. Our experiments demonstrate that our algorithm significantly improves the realism of the viewing experience for a variety of different pupil states.
Temporally Consistent Online Depth Estimation Using Point-Based Fusion
May 01, 2023Depth estimation is an important step in many computer vision problems such as 3D reconstruction, novel view synthesis, and computational photography. Most existing work focuses on depth estimation from single frames. When applied to videos, the result lacks temporal consistency, showing flickering and swimming artifacts. In this paper we aim to estimate temporally consistent depth maps of video streams in an online setting. This is a difficult problem as future frames are not available and the method must choose between enforcing consistency and correcting errors from previous estimations. The presence of dynamic objects further complicates the problem. We propose to address these challenges by using a global point cloud that is dynamically updated each frame, along with a learned fusion approach in image space. Our approach encourages consistency while simultaneously allowing updates to handle errors and dynamic objects. Qualitative and quantitative results show that our method achieves state-of-the-art quality for consistent video depth estimation.
* Supplementary video at https://research.facebook.com/publications/temporally-consistent-online-depth-estimation-using-point-based-fusion/
NeuralPassthrough: Learned Real-Time View Synthesis for VR
Jul 05, 2022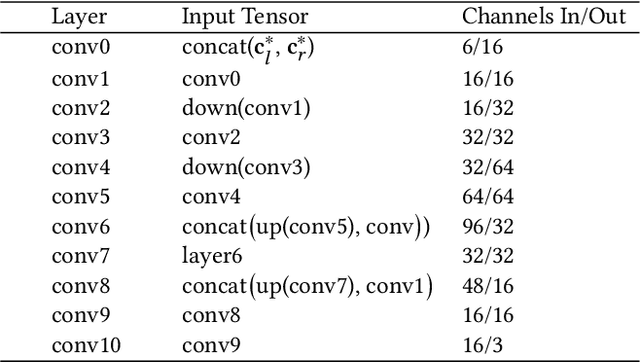

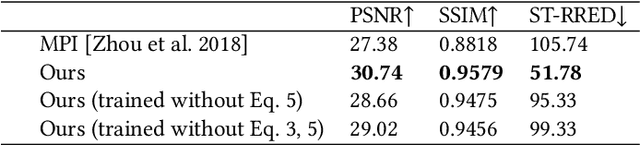
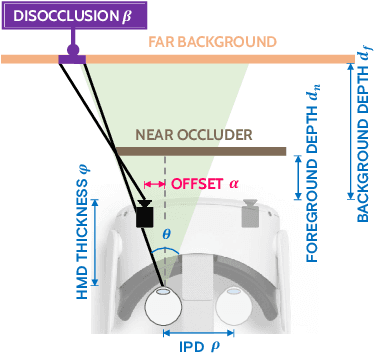
Virtual reality (VR) headsets provide an immersive, stereoscopic visual experience, but at the cost of blocking users from directly observing their physical environment. Passthrough techniques are intended to address this limitation by leveraging outward-facing cameras to reconstruct the images that would otherwise be seen by the user without the headset. This is inherently a real-time view synthesis challenge, since passthrough cameras cannot be physically co-located with the eyes. Existing passthrough techniques suffer from distracting reconstruction artifacts, largely due to the lack of accurate depth information (especially for near-field and disoccluded objects), and also exhibit limited image quality (e.g., being low resolution and monochromatic). In this paper, we propose the first learned passthrough method and assess its performance using a custom VR headset that contains a stereo pair of RGB cameras. Through both simulations and experiments, we demonstrate that our learned passthrough method delivers superior image quality compared to state-of-the-art methods, while meeting strict VR requirements for real-time, perspective-correct stereoscopic view synthesis over a wide field of view for desktop-connected headsets.
Neural Étendue Expander for Ultra-Wide-Angle High-Fidelity Holographic Display
Sep 16, 2021
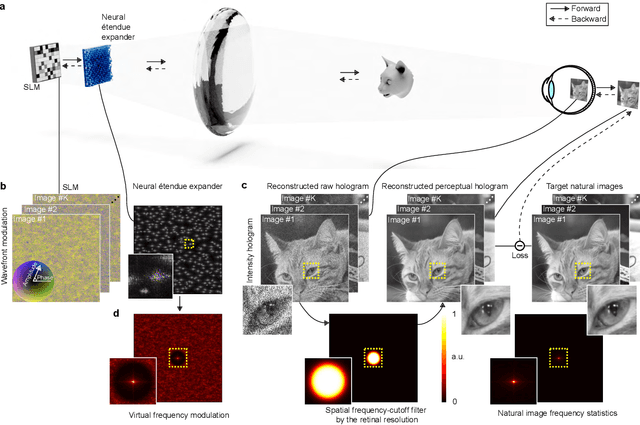


Holographic displays can generate light fields by dynamically modulating the wavefront of a coherent beam of light using a spatial light modulator, promising rich virtual and augmented reality applications. However, the limited spatial resolution of existing dynamic spatial light modulators imposes a tight bound on the diffraction angle. As a result, today's holographic displays possess low \'{e}tendue, which is the product of the display area and the maximum solid angle of diffracted light. The low \'{e}tendue forces a sacrifice of either the field of view (FOV) or the display size. In this work, we lift this limitation by presenting neural \'{e}tendue expanders. This new breed of optical elements, which is learned from a natural image dataset, enables higher diffraction angles for ultra-wide FOV while maintaining both a compact form factor and the fidelity of displayed contents to human viewers. With neural \'{e}tendue expanders, we achieve 64$\times$ \'{e}tendue expansion of natural images with reconstruction quality (measured in PSNR) over 29dB on simulated retinal-resolution images. As a result, the proposed approach with expansion factor 64$\times$ enables high-fidelity ultra-wide-angle holographic projection of natural images using an 8K-pixel SLM, resulting in a 18.5 mm eyebox size and 2.18 steradians FOV, covering 85\% of the human stereo FOV.