 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-guided Online 3D Video Synthesis with Multi-View Temporal Consistency
May 25, 2025


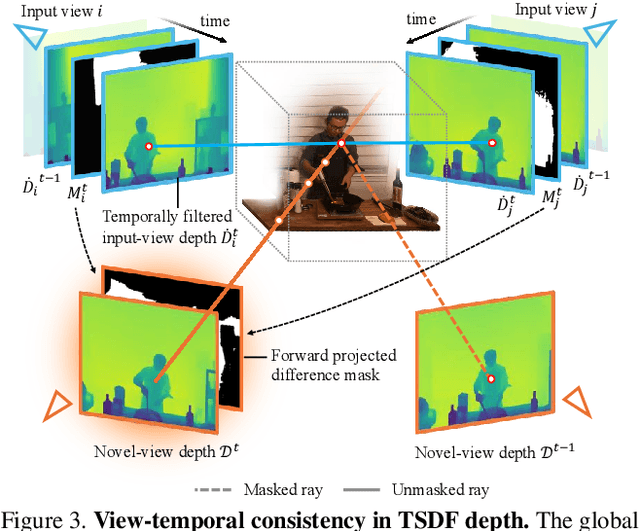
We introduce a novel geometry-guided online video view synthesis method with enhanced view and temporal consistency. Traditional approaches achieve high-quality synthesis from dense multi-view camera setups but require significant computational resources. In contrast, selective-input methods reduce this cost but often compromise quality, leading to multi-view and temporal inconsistencies such as flickering artifacts. Our method addresses this challenge to deliver efficient, high-quality novel-view synthesis with view and temporal consistency. The key innovation of our approach lies in using global geometry to guide an image-based rendering pipeline. To accomplish this, we progressively refine depth maps using color difference masks across time. These depth maps are then accumulated through truncated signed distance fields in the synthesized view's image space. This depth representation is view and temporally consistent, and is used to guide a pre-trained blending network that fuses multiple forward-rendered input-view images. Thus, the network is encouraged to output geometrically consistent synthesis results across multiple views and time. Our approach achieves consistent, high-quality video synthesis, while running efficiently in an online manner.
Benchmarking Burst Super-Resolution for Polarization Images: Noise Dataset and Analysis
Mar 24, 2025



Snapshot polarization imaging calculates polarization states from linearly polarized subimages. To achieve this, a polarization camera employs a double Bayer-patterned sensor to capture both color and polarization. It demonstrates low light efficiency and low spatial resolution, resulting in increased noise and compromised polarization measurements. Although burst super-resolution effectively reduces noise and enhances spatial resolution, applying it to polarization imaging poses challenges due to the lack of tailored datasets and reliable ground truth noise statistics. To address these issues, we introduce PolarNS and PolarBurstSR, two innovative datasets developed specifically for polarization imaging. PolarNS provides characterization of polarization noise statistics, facilitating thorough analysis, while PolarBurstSR functions as a benchmark for burst super-resolution in polarization images. These datasets, collected under various real-world conditions, enable comprehensive evaluation. Additionally, we present a model for analyzing polarization noise to quantify noise propagation, tested on a large dataset captured in a darkroom environment. As part of our application, we compare the latest burst super-resolution models, highlighting the advantages of training tailored to polarization compared to RGB-based methods. This work establishes a benchmark for polarization burst super-resolution and offers critical insights into noise propagation, thereby enhancing polarization image reconstruction.
Polarimetric BSSRDF Acquisition of Dynamic Faces
Dec 29, 2024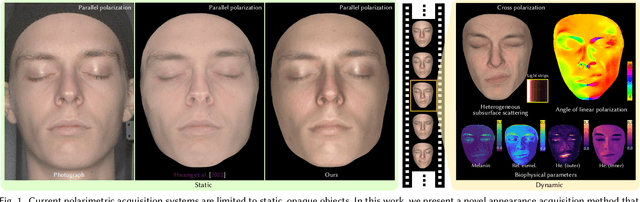
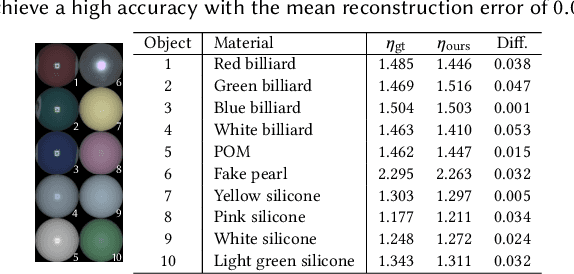
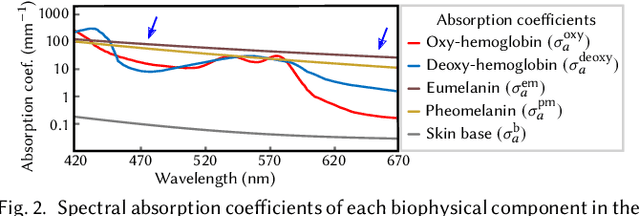

Acquisition and modeling of polarized light reflection and scattering help reveal the shape, structure, and physical characteristics of an object, which is increasingly important in computer graphics. However, current polarimetric acquisition systems are limited to static and opaque objects. Human faces, on the other hand, present a particularly difficult challenge, given their complex structure and reflectance properties, the strong presence of spatially-varying subsurface scattering, and their dynamic nature. We present a new polarimetric acquisition method for dynamic human faces, which focuses on capturing spatially varying appearance and precise geometry, across a wide spectrum of skin tones and facial expressions. It includes both single and heterogeneous subsurface scattering, index of refraction, and specular roughness and intensity, among other parameters, while revealing biophysically-based components such as inner- and outer-layer hemoglobin, eumelanin and pheomelanin. Our method leverages such components' unique multispectral absorption profiles to quantify their concentrations, which in turn inform our model about the complex interactions occurring within the skin layers. To our knowledge, our work is the first to simultaneously acquire polarimetric and spectral reflectance information alongside biophysically-based skin parameters and geometry of dynamic human faces. Moreover, our polarimetric skin model integrates seamlessly into various rendering pipelines.
DeepFormableTag: End-to-end Generation and Recognition of Deformable Fiducial Markers
Jun 16, 2022
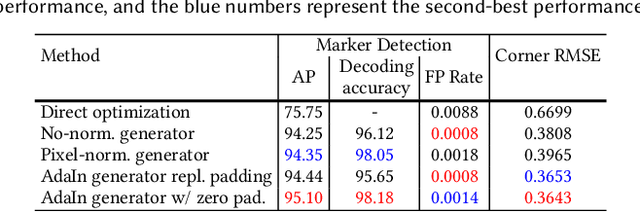
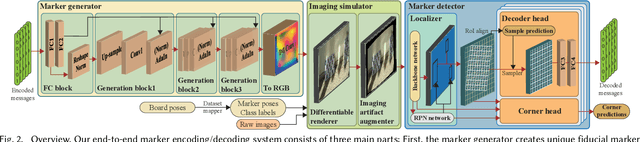

Fiducial markers have been broadly used to identify objects or embed messages that can be detected by a camera. Primarily, existing detection methods assume that markers are printed on ideally planar surfaces. Markers often fail to be recognized due to various imaging artifacts of optical/perspective distortion and motion blur. To overcome these limitations, we propose a novel deformable fiducial marker system that consists of three main parts: First, a fiducial marker generator creates a set of free-form color patterns to encode significantly large-scale information in unique visual codes. Second, a differentiable image simulator creates a training dataset of photorealistic scene images with the deformed markers, being rendered during optimization in a differentiable manner. The rendered images include realistic shading with specular reflection, optical distortion, defocus and motion blur, color alteration, imaging noise, and shape deformation of markers. Lastly, a trained marker detector seeks the regions of interest and recognizes multiple marker patterns simultaneously via inverse deformation transformation. The deformable marker creator and detector networks are jointly optimized via the differentiable photorealistic renderer in an end-to-end manner, allowing us to robustly recognize a wide range of deformable markers with high accuracy. Our deformable marker system is capable of decoding 36-bit messages successfully at ~29 fps with severe shape deformation. Results validate that our system significantly outperforms the traditional and data-driven marker methods. Our learning-based marker system opens up new interesting applications of fiducial markers, including cost-effective motion capture of the human body, active 3D scanning using our fiducial markers' array as structured light patterns, and robust augmented reality rendering of virtual objects on dynamic surfaces.