 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Dark-Matter Clusters via Physics-Guided Diffusion Models
Mar 15, 2026Galaxy clusters are powerful probes of astrophysics and cosmology through gravitational lensing: the clusters' mass, dominated by 85% dark matter, distorts background light. Yet, mass reconstruction lacks the scalability and large-scale benchmarks to process the hundreds of thousands of clusters expected from forthcoming wide-field surveys. We introduce a fully automated method to reconstruct cluster surface mass density from photometry and gravitational lensing observables. Central to our approach is DarkClusters-15k, our new dataset of 15,000 simulated clusters with paired mass and photometry maps, the largest benchmark to date, spanning multiple redshifts and simulation frameworks. We train a plug-and-play diffusion prior on DarkClusters-15k that learns the statistical relationship between mass and light, and draw posterior samples constrained by weak- and strong-lensing observables; this yields principled reconstructions driven by explicit physics, alongside well-calibrated uncertainties. Our approach requires no expert tuning, runs in minutes rather than hours, achieves higher accuracy, and matches expertly-tuned reconstructions of the MACS 1206 cluster. We release our method and DarkClusters-15k to support development and benchmarking for upcoming wide-field cosmological surveys.
A comprehensive study of time-of-flight non-line-of-sight imaging
Mar 10, 2026Time-of-Flight non-line-of-sight (ToF NLOS) imaging techniques provide state-of-the-art reconstructions of scenes hidden around corners by inverting the optical path of indirect photons scattered by visible surfaces and measured by picosecond resolution sensors. The emergence of a wide range of ToF NLOS imaging methods with heterogeneous formulae and hardware implementations obscures the assessment of both their theoretical and experimental aspects. We present a comprehensive study of a representative set of ToF NLOS imaging methods by discussing their similarities and differences under common formulation and hardware. We first outline the problem statement under a common general forward model for ToF NLOS measurements, and the typical assumptions that yield tractable inverse models. We discuss the relationship of the resulting simplified forward and inverse models to a family of Radon transforms, and how migrating these to the frequency domain relates to recent phasor-based virtual line-of-sight imaging models for NLOS imaging that obey the constraints of conventional lens-based imaging systems. We then evaluate performance of the selected methods on hidden scenes captured under the same hardware setup and similar photon counts. Our experiments show that existing methods share similar limitations on spatial resolution, visibility, and sensitivity to noise when operating under equal hardware constraints, with particular differences that stem from method-specific parameters. We expect our methodology to become a reference in future research on ToF NLOS imaging to obtain objective comparisons of existing and new methods.
Fine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
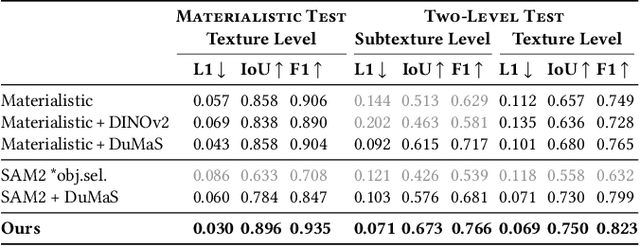

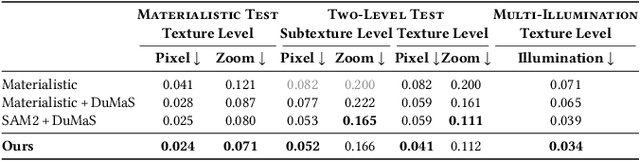
Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
Crossing Borders Without Crossing Boundaries: How Sociolinguistic Awareness Can Optimize User Engagement with Localized Spanish AI Models Across Hispanophone Countries
May 15, 2025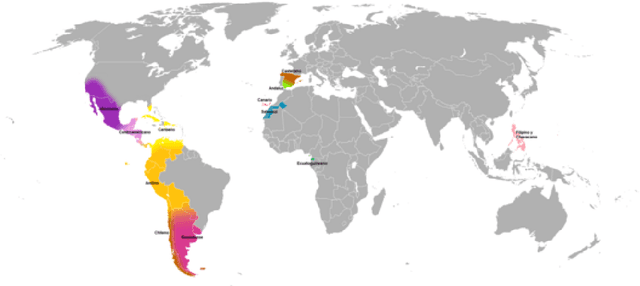
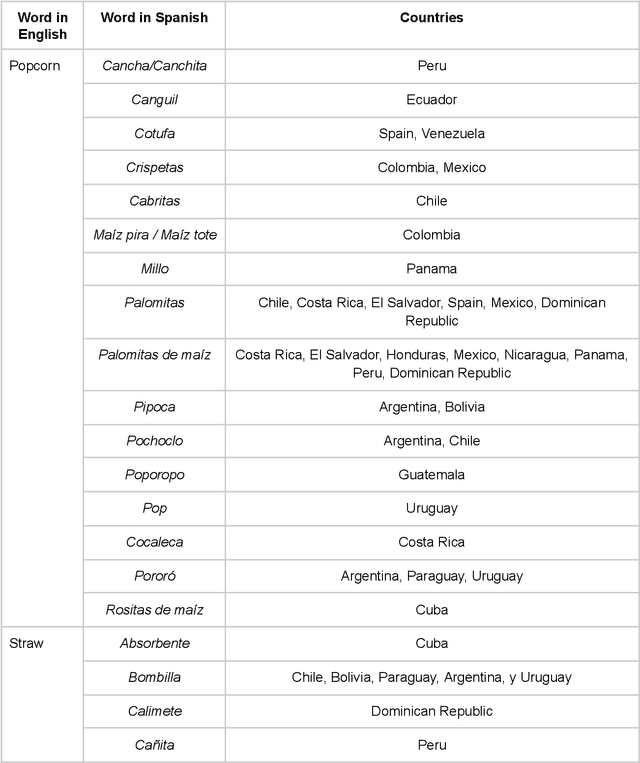
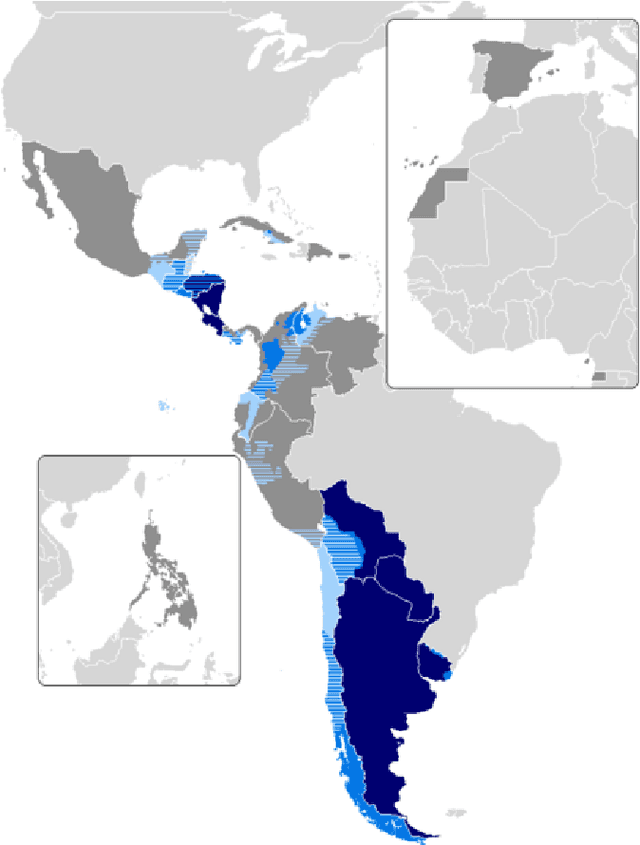
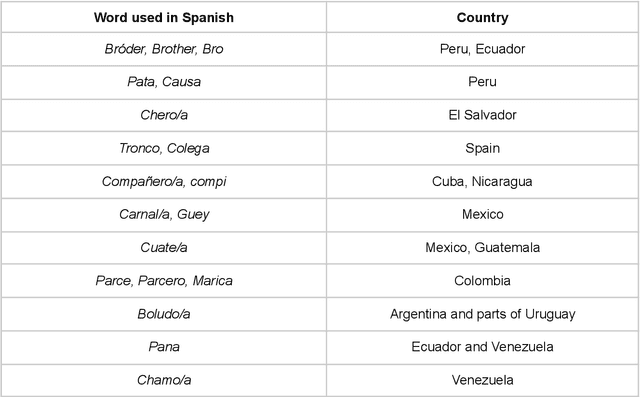
Large language models are, by definition, based on language. In an effort to underscore the critical need for regional localized models, this paper examines primary differences between variants of written Spanish across Latin America and Spain, with an in-depth sociocultural and linguistic contextualization therein. We argue that these differences effectively constitute significant gaps in the quotidian use of Spanish among dialectal groups by creating sociolinguistic dissonances, to the extent that locale-sensitive AI models would play a pivotal role in bridging these divides. In doing so, this approach informs better and more efficient localization strategies that also serve to more adequately meet inclusivity goals, while securing sustainable active daily user growth in a major low-risk investment geographic area. Therefore, implementing at least the proposed five sub variants of Spanish addresses two lines of action: to foment user trust and reliance on AI language models while also demonstrating a level of cultural, historical, and sociolinguistic awareness that reflects positively on any internationalization strategy.
Polarimetric BSSRDF Acquisition of Dynamic Faces
Dec 29, 2024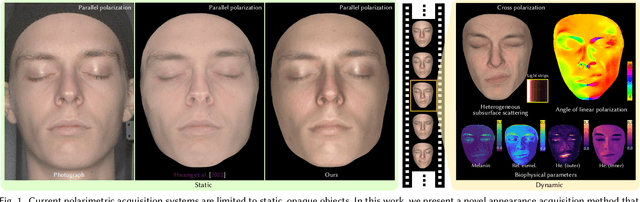
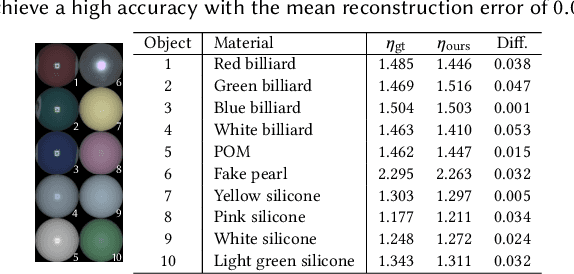
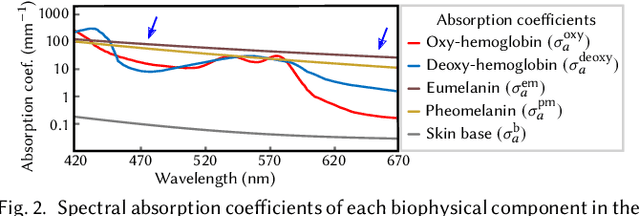

Acquisition and modeling of polarized light reflection and scattering help reveal the shape, structure, and physical characteristics of an object, which is increasingly important in computer graphics. However, current polarimetric acquisition systems are limited to static and opaque objects. Human faces, on the other hand, present a particularly difficult challenge, given their complex structure and reflectance properties, the strong presence of spatially-varying subsurface scattering, and their dynamic nature. We present a new polarimetric acquisition method for dynamic human faces, which focuses on capturing spatially varying appearance and precise geometry, across a wide spectrum of skin tones and facial expressions. It includes both single and heterogeneous subsurface scattering, index of refraction, and specular roughness and intensity, among other parameters, while revealing biophysically-based components such as inner- and outer-layer hemoglobin, eumelanin and pheomelanin. Our method leverages such components' unique multispectral absorption profiles to quantify their concentrations, which in turn inform our model about the complex interactions occurring within the skin layers. To our knowledge, our work is the first to simultaneously acquire polarimetric and spectral reflectance information alongside biophysically-based skin parameters and geometry of dynamic human faces. Moreover, our polarimetric skin model integrates seamlessly into various rendering pipelines.
TexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024
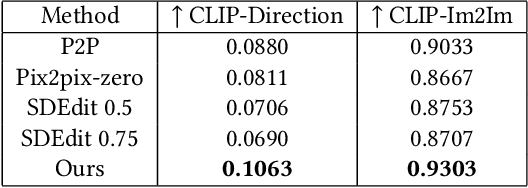


Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Mar 26, 2024Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations ("strong labels") can be effectively augmented with automatically derived "weak labels" in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
Self-Calibrating, Fully Differentiable NLOS Inverse Rendering
Sep 26, 2023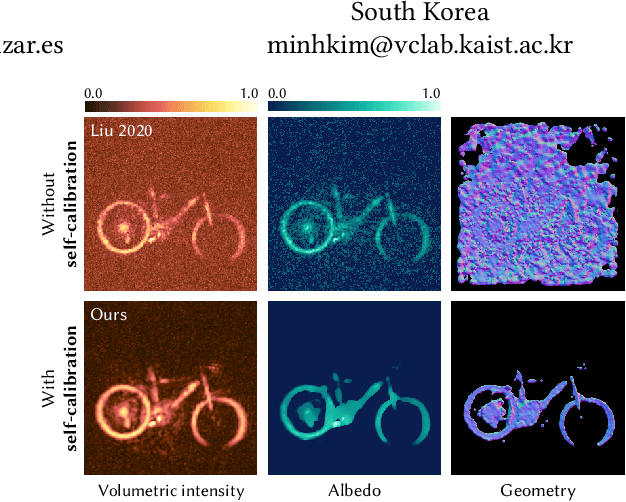


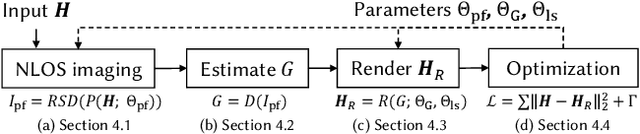
Existing time-resolved non-line-of-sight (NLOS) imaging methods reconstruct hidden scenes by inverting the optical paths of indirect illumination measured at visible relay surfaces. These methods are prone to reconstruction artifacts due to inversion ambiguities and capture noise, which are typically mitigated through the manual selection of filtering functions and parameters. We introduce a fully-differentiable end-to-end NLOS inverse rendering pipeline that self-calibrates the imaging parameters during the reconstruction of hidden scenes, using as input only the measured illumination while working both in the time and frequency domains. Our pipeline extracts a geometric representation of the hidden scene from NLOS volumetric intensities and estimates the time-resolved illumination at the relay wall produced by such geometric information using differentiable transient rendering. We then use gradient descent to optimize imaging parameters by minimizing the error between our simulated time-resolved illumination and the measured illumination. Our end-to-end differentiable pipeline couples diffraction-based volumetric NLOS reconstruction with path-space light transport and a simple ray marching technique to extract detailed, dense sets of surface points and normals of hidden scenes. We demonstrate the robustness of our method to consistently reconstruct geometry and albedo, even under significant noise levels.
Structure-Aware Parametric Representations for Time-Resolved Light Transport
Aug 30, 2023



Time-resolved illumination provides rich spatio-temporal information for applications such as accurate depth sensing or hidden geometry reconstruction, becoming a useful asset for prototyping and as input for data-driven approaches. However, time-resolved illumination measurements are high-dimensional and have a low signal-to-noise ratio, hampering their applicability in real scenarios. We propose a novel method to compactly represent time-resolved illumination using mixtures of exponentially-modified Gaussians that are robust to noise and preserve structural information. Our method yields representations two orders of magnitude smaller than discretized data, providing consistent results in applications such as hidden scene reconstruction and depth estimation, and quantitative improvements over previous approaches.
Virtual Mirrors: Non-Line-of-Sight Imaging Beyond the Third Bounce
Jul 26, 2023
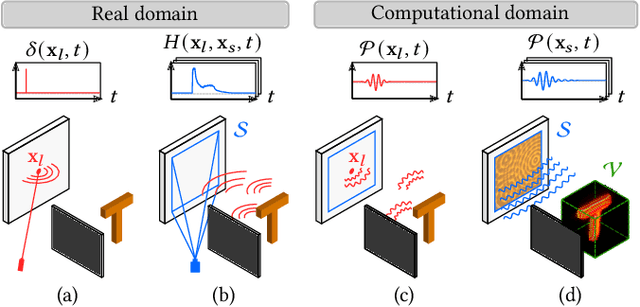


Non-line-of-sight (NLOS) imaging methods are capable of reconstructing complex scenes that are not visible to an observer using indirect illumination. However, they assume only third-bounce illumination, so they are currently limited to single-corner configurations, and present limited visibility when imaging surfaces at certain orientations. To reason about and tackle these limitations, we make the key observation that planar diffuse surfaces behave specularly at wavelengths used in the computational wave-based NLOS imaging domain. We call such surfaces virtual mirrors. We leverage this observation to expand the capabilities of NLOS imaging using illumination beyond the third bounce, addressing two problems: imaging single-corner objects at limited visibility angles, and imaging objects hidden behind two corners. To image objects at limited visibility angles, we first analyze the reflections of the known illuminated point on surfaces of the scene as an estimator of the position and orientation of objects with limited visibility. We then image those limited visibility objects by computationally building secondary apertures at other surfaces that observe the target object from a direct visibility perspective. Beyond single-corner NLOS imaging, we exploit the specular behavior of virtual mirrors to image objects hidden behind a second corner by imaging the space behind such virtual mirrors, where the mirror image of objects hidden around two corners is formed. No specular surfaces were involved in the making of this paper.