 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle-Aware Gloss Control for Generative Non-Photorealistic Rendering
Feb 19, 2026Humans can infer material characteristics of objects from their visual appearance, and this ability extends to artistic depictions, where similar perceptual strategies guide the interpretation of paintings or drawings. Among the factors that define material appearance, gloss, along with color, is widely regarded as one of the most important, and recent studies indicate that humans can perceive gloss independently of the artistic style used to depict an object. To investigate how gloss and artistic style are represented in learned models, we train an unsupervised generative model on a newly curated dataset of painterly objects designed to systematically vary such factors. Our analysis reveals a hierarchical latent space in which gloss is disentangled from other appearance factors, allowing for a detailed study of how gloss is represented and varies across artistic styles. Building on this representation, we introduce a lightweight adapter that connects our style- and gloss-aware latent space to a latent-diffusion model, enabling the synthesis of non-photorealistic images with fine-grained control of these factors. We compare our approach with previous models and observe improved disentanglement and controllability of the learned factors.
Fine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
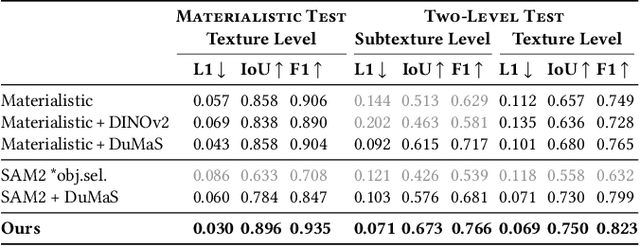

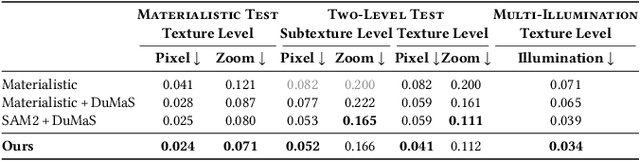
Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
A Controllable Appearance Representation for Flexible Transfer and Editing
Apr 21, 2025We present a method that computes an interpretable representation of material appearance within a highly compact, disentangled latent space. This representation is learned in a self-supervised fashion using an adapted FactorVAE. We train our model with a carefully designed unlabeled dataset, avoiding possible biases induced by human-generated labels. Our model demonstrates strong disentanglement and interpretability by effectively encoding material appearance and illumination, despite the absence of explicit supervision. Then, we use our representation as guidance for training a lightweight IP-Adapter to condition a diffusion pipeline that transfers the appearance of one or more images onto a target geometry, and allows the user to further edit the resulting appearance. Our approach offers fine-grained control over the generated results: thanks to the well-structured compact latent space, users can intuitively manipulate attributes such as hue or glossiness in image space to achieve the desired final appearance.
TexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024
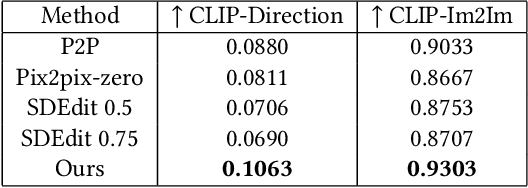


Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Mar 26, 2024Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations ("strong labels") can be effectively augmented with automatically derived "weak labels" in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
The Visual Language of Fabrics
Jul 25, 2023



We introduce text2fabric, a novel dataset that links free-text descriptions to various fabric materials. The dataset comprises 15,000 natural language descriptions associated to 3,000 corresponding images of fabric materials. Traditionally, material descriptions come in the form of tags/keywords, which limits their expressivity, induces pre-existing knowledge of the appropriate vocabulary, and ultimately leads to a chopped description system. Therefore, we study the use of free-text as a more appropriate way to describe material appearance, taking the use case of fabrics as a common item that non-experts may often deal with. Based on the analysis of the dataset, we identify a compact lexicon, set of attributes and key structure that emerge from the descriptions. This allows us to accurately understand how people describe fabrics and draw directions for generalization to other types of materials. We also show that our dataset enables specializing large vision-language models such as CLIP, creating a meaningful latent space for fabric appearance, and significantly improving applications such as fine-grained material retrieval and automatic captioning.
A Probabilistic Time-Evolving Approach to Scanpath Prediction
Apr 20, 2022


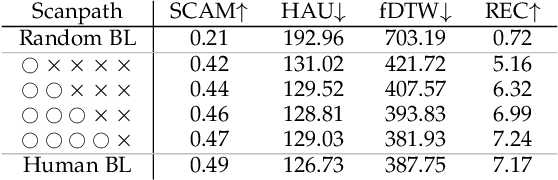
Human visual attention is a complex phenomenon that has been studied for decades. Within it, the particular problem of scanpath prediction poses a challenge, particularly due to the inter- and intra-observer variability, among other reasons. Besides, most existing approaches to scanpath prediction have focused on optimizing the prediction of a gaze point given the previous ones. In this work, we present a probabilistic time-evolving approach to scanpath prediction, based on Bayesian deep learning. We optimize our model using a novel spatio-temporal loss function based on a combination of Kullback-Leibler divergence and dynamic time warping, jointly considering the spatial and temporal dimensions of scanpaths. Our scanpath prediction framework yields results that outperform those of current state-of-the-art approaches, and are almost on par with the human baseline, suggesting that our model is able to generate scanpaths whose behavior closely resembles those of the real ones.
Single-image Full-body Human Relighting
Jul 15, 2021


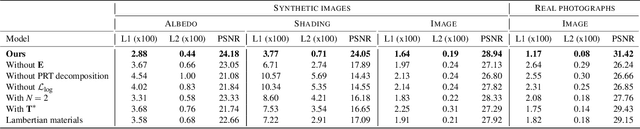
We present a single-image data-driven method to automatically relight images with full-body humans in them. Our framework is based on a realistic scene decomposition leveraging precomputed radiance transfer (PRT) and spherical harmonics (SH) lighting. In contrast to previous work, we lift the assumptions on Lambertian materials and explicitly model diffuse and specular reflectance in our data. Moreover, we introduce an additional light-dependent residual term that accounts for errors in the PRT-based image reconstruction. We propose a new deep learning architecture, tailored to the decomposition performed in PRT, that is trained using a combination of L1, logarithmic, and rendering losses. Our model outperforms the state of the art for full-body human relighting both with synthetic images and photographs.
* 11 pages, 12 figures
ScanGAN360: A Generative Model of Realistic Scanpaths for 360$^{\circ}$ Images
Mar 25, 2021
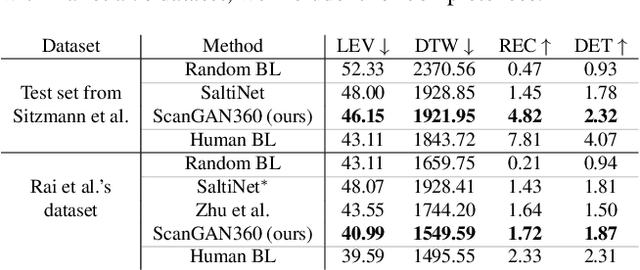
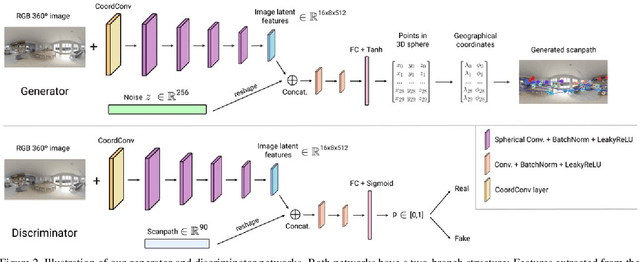
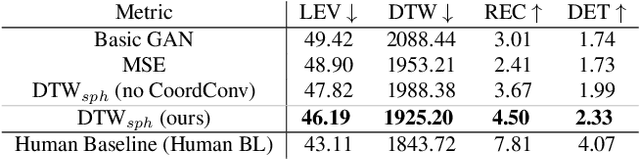
Understanding and modeling the dynamics of human gaze behavior in 360$^\circ$ environments is a key challenge in computer vision and virtual reality. Generative adversarial approaches could alleviate this challenge by generating a large number of possible scanpaths for unseen images. Existing methods for scanpath generation, however, do not adequately predict realistic scanpaths for 360$^\circ$ images. We present ScanGAN360, a new generative adversarial approach to address this challenging problem. Our network generator is tailored to the specifics of 360$^\circ$ images representing immersive environments. Specifically, we accomplish this by leveraging the use of a spherical adaptation of dynamic-time warping as a loss function and proposing a novel parameterization of 360$^\circ$ scanpaths. The quality of our scanpaths outperforms competing approaches by a large margin and is almost on par with the human baseline. ScanGAN360 thus allows fast simulation of large numbers of virtual observers, whose behavior mimics real users, enabling a better understanding of gaze behavior and novel applications in virtual scene design.
The joint role of geometry and illumination on material recognition
Feb 04, 2021



Observing and recognizing materials is a fundamental part of our daily life. Under typical viewing conditions, we are capable of effortlessly identifying the objects that surround us and recognizing the materials they are made of. Nevertheless, understanding the underlying perceptual processes that take place to accurately discern the visual properties of an object is a long-standing problem. In this work, we perform a comprehensive and systematic analysis of how the interplay of geometry, illumination, and their spatial frequencies affects human performance on material recognition tasks. We carry out large-scale behavioral experiments where participants are asked to recognize different reference materials among a pool of candidate samples. In the different experiments, we carefully sample the information in the frequency domain of the stimuli. From our analysis, we find significant first-order interactions between the geometry and the illumination, of both the reference and the candidates. In addition, we observe that simple image statistics and higher-order image histograms do not correlate with human performance. Therefore, we perform a high-level comparison of highly non-linear statistics by training a deep neural network on material recognition tasks. Our results show that such models can accurately classify materials, which suggests that they are capable of defining a meaningful representation of material appearance from labeled proximal image data. Last, we find preliminary evidence that these highly non-linear models and humans may use similar high-level factors for material recognition tasks.
* 15 pages, 16 figures, Accepted to the Journal of Vision, 2021