 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Spatially Varying Material Selection in Images
Jun 11, 2025
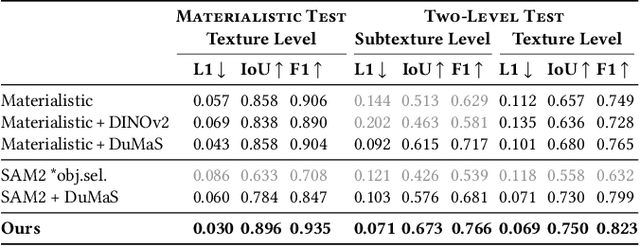

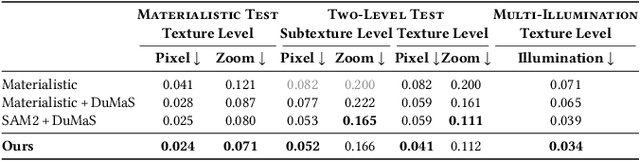
Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
A Controllable Appearance Representation for Flexible Transfer and Editing
Apr 21, 2025We present a method that computes an interpretable representation of material appearance within a highly compact, disentangled latent space. This representation is learned in a self-supervised fashion using an adapted FactorVAE. We train our model with a carefully designed unlabeled dataset, avoiding possible biases induced by human-generated labels. Our model demonstrates strong disentanglement and interpretability by effectively encoding material appearance and illumination, despite the absence of explicit supervision. Then, we use our representation as guidance for training a lightweight IP-Adapter to condition a diffusion pipeline that transfers the appearance of one or more images onto a target geometry, and allows the user to further edit the resulting appearance. Our approach offers fine-grained control over the generated results: thanks to the well-structured compact latent space, users can intuitively manipulate attributes such as hue or glossiness in image space to achieve the desired final appearance.
TexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024
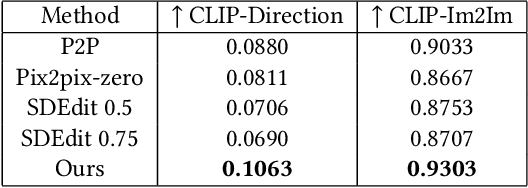


Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Mar 26, 2024Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations ("strong labels") can be effectively augmented with automatically derived "weak labels" in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
The Visual Language of Fabrics
Jul 25, 2023



We introduce text2fabric, a novel dataset that links free-text descriptions to various fabric materials. The dataset comprises 15,000 natural language descriptions associated to 3,000 corresponding images of fabric materials. Traditionally, material descriptions come in the form of tags/keywords, which limits their expressivity, induces pre-existing knowledge of the appropriate vocabulary, and ultimately leads to a chopped description system. Therefore, we study the use of free-text as a more appropriate way to describe material appearance, taking the use case of fabrics as a common item that non-experts may often deal with. Based on the analysis of the dataset, we identify a compact lexicon, set of attributes and key structure that emerge from the descriptions. This allows us to accurately understand how people describe fabrics and draw directions for generalization to other types of materials. We also show that our dataset enables specializing large vision-language models such as CLIP, creating a meaningful latent space for fabric appearance, and significantly improving applications such as fine-grained material retrieval and automatic captioning.
Semi-Supervised Disparity Estimation with Deep Feature Reconstruction
Jun 01, 2021


Despite the success of deep learning in disparity estimation, the domain generalization gap remains an issue. We propose a semi-supervised pipeline that successfully adapts DispNet to a real-world domain by joint supervised training on labeled synthetic data and self-supervised training on unlabeled real data. Furthermore, accounting for the limitations of the widely-used photometric loss, we analyze the impact of deep feature reconstruction as a promising supervisory signal for disparity estimation.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
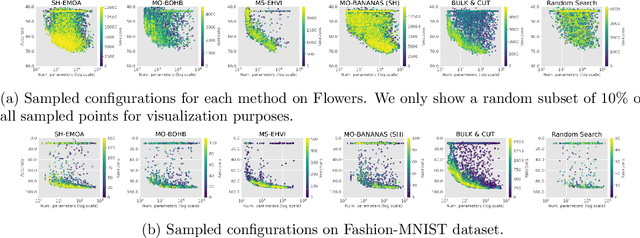
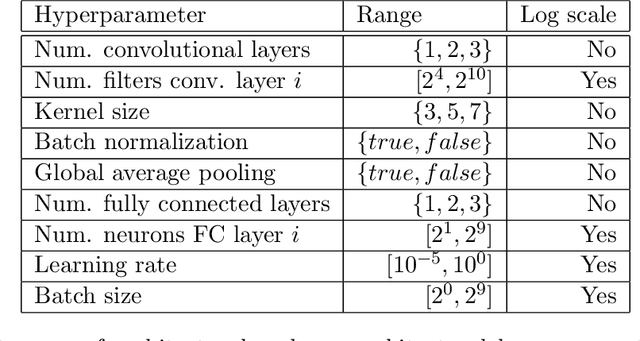
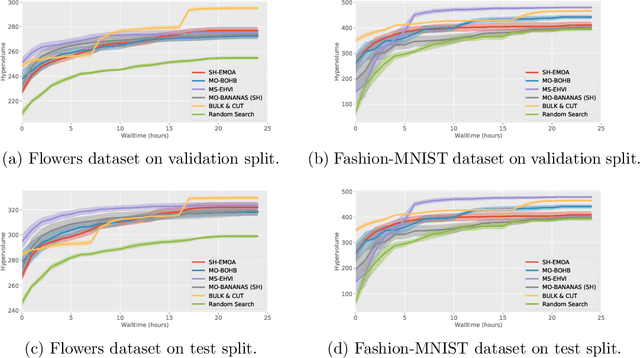
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.
What's in my Room? Object Recognition on Indoor Panoramic Images
Oct 14, 2019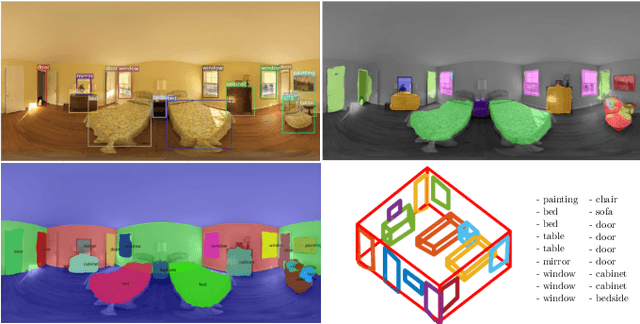

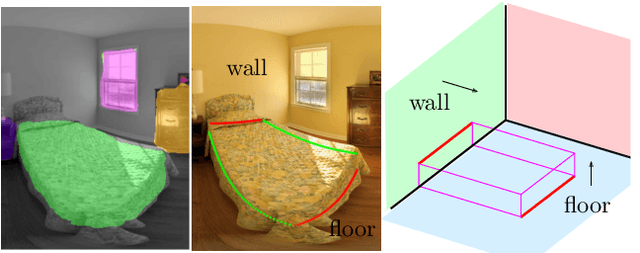
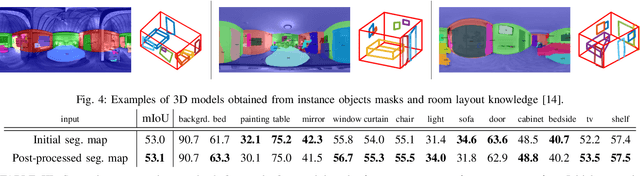
In the last few years, there has been a growing interest in taking advantage of the 360 panoramic images potential, while managing the new challenges they imply. While several tasks have been improved thanks to the contextual information these images offer, object recognition in indoor scenes still remains a challenging problem that has not been deeply investigated. This paper provides an object recognition system that performs object detection and semantic segmentation tasks by using a deep learning model adapted to match the nature of equirectangular images. From these results, instance segmentation masks are recovered, refined and transformed into 3D bounding boxes that are placed into the 3D model of the room. Quantitative and qualitative results support that our method outperforms the state of the art by a large margin and show a complete understanding of the main objects in indoor scenes.