 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
Single-Shot Metric Depth from Focused Plenoptic Cameras
Dec 03, 2024



Metric depth estimation from visual sensors is crucial for robots to perceive, navigate, and interact with their environment. Traditional range imaging setups, such as stereo or structured light cameras, face hassles including calibration, occlusions, and hardware demands, with accuracy limited by the baseline between cameras. Single- and multi-view monocular depth offers a more compact alternative, but is constrained by the unobservability of the metric scale. Light field imaging provides a promising solution for estimating metric depth by using a unique lens configuration through a single device. However, its application to single-view dense metric depth is under-addressed mainly due to the technology's high cost, the lack of public benchmarks, and proprietary geometrical models and software. Our work explores the potential of focused plenoptic cameras for dense metric depth. We propose a novel pipeline that predicts metric depth from a single plenoptic camera shot by first generating a sparse metric point cloud using machine learning, which is then used to scale and align a dense relative depth map regressed by a foundation depth model, resulting in dense metric depth. To validate it, we curated the Light Field & Stereo Image Dataset (LFS) of real-world light field images with stereo depth labels, filling a current gap in existing resources. Experimental results show that our pipeline produces accurate metric depth predictions, laying a solid groundwork for future research in this field.
Close, But Not There: Boosting Geographic Distance Sensitivity in Visual Place Recognition
Jul 02, 2024



Visual Place Recognition (VPR) plays a critical role in many localization and mapping pipelines. It consists of retrieving the closest sample to a query image, in a certain embedding space, from a database of geotagged references. The image embedding is learned to effectively describe a place despite variations in visual appearance, viewpoint, and geometric changes. In this work, we formulate how limitations in the Geographic Distance Sensitivity of current VPR embeddings result in a high probability of incorrectly sorting the top-k retrievals, negatively impacting the recall. In order to address this issue in single-stage VPR, we propose a novel mining strategy, CliqueMining, that selects positive and negative examples by sampling cliques from a graph of visually similar images. Our approach boosts the sensitivity of VPR embeddings at small distance ranges, significantly improving the state of the art on relevant benchmarks. In particular, we raise recall@1 from 75% to 82% in MSLS Challenge, and from 76% to 90% in Nordland. Models and code are available at https://github.com/serizba/cliquemining.
Optimal Transport Aggregation for Visual Place Recognition
Nov 27, 2023



The task of Visual Place Recognition (VPR) aims to match a query image against references from an extensive database of images from different places, relying solely on visual cues. State-of-the-art pipelines focus on the aggregation of features extracted from a deep backbone, in order to form a global descriptor for each image. In this context, we introduce SALAD (Sinkhorn Algorithm for Locally Aggregated Descriptors), which reformulates NetVLAD's soft-assignment of local features to clusters as an optimal transport problem. In SALAD, we consider both feature-to-cluster and cluster-to-feature relations and we also introduce a 'dustbin' cluster, designed to selectively discard features deemed non-informative, enhancing the overall descriptor quality. Additionally, we leverage and fine-tune DINOv2 as a backbone, which provides enhanced description power for the local features, and dramatically reduces the required training time. As a result, our single-stage method not only surpasses single-stage baselines in public VPR datasets, but also surpasses two-stage methods that add a re-ranking with significantly higher cost. Code and models are available at https://github.com/serizba/salad.
SfM-TTR: Using Structure from Motion for Test-Time Refinement of Single-View Depth Networks
Nov 24, 2022



Estimating a dense depth map from a single view is geometrically ill-posed, and state-of-the-art methods rely on learning depth's relation with visual appearance using deep neural networks. On the other hand, Structure from Motion (SfM) leverages multi-view constraints to produce very accurate but sparse maps, as accurate matching across images is limited by locally discriminative texture. In this work, we combine the strengths of both approaches by proposing a novel test-time refinement (TTR) method, denoted as SfM-TTR, that boosts the performance of single-view depth networks at test time using SfM multi-view cues. Specifically, and differently from the state of the art, we use sparse SfM point clouds as test-time self-supervisory signal, fine-tuning the network encoder to learn a better representation of the test scene. Our results show how the addition of SfM-TTR to several state-of-the-art self-supervised and supervised networks improves significantly their performance, outperforming previous TTR baselines mainly based on photometric multi-view consistency.
Conditional Visual Servoing for Multi-Step Tasks
May 17, 2022



Visual Servoing has been effectively used to move a robot into specific target locations or to track a recorded demonstration. It does not require manual programming, but it is typically limited to settings where one demonstration maps to one environment state. We propose a modular approach to extend visual servoing to scenarios with multiple demonstration sequences. We call this conditional servoing, as we choose the next demonstration conditioned on the observation of the robot. This method presents an appealing strategy to tackle multi-step problems, as individual demonstrations can be combined flexibly into a control policy. We propose different selection functions and compare them on a shape-sorting task in simulation. With the reprojection error yielding the best overall results, we implement this selection function on a real robot and show the efficacy of the proposed conditional servoing. For videos of our experiments, please check out our project page: https://lmb.informatik.uni-freiburg.de/projects/conditional_servoing/
Semi-Supervised Disparity Estimation with Deep Feature Reconstruction
Jun 01, 2021


Despite the success of deep learning in disparity estimation, the domain generalization gap remains an issue. We propose a semi-supervised pipeline that successfully adapts DispNet to a real-world domain by joint supervised training on labeled synthetic data and self-supervised training on unlabeled real data. Furthermore, accounting for the limitations of the widely-used photometric loss, we analyze the impact of deep feature reconstruction as a promising supervisory signal for disparity estimation.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
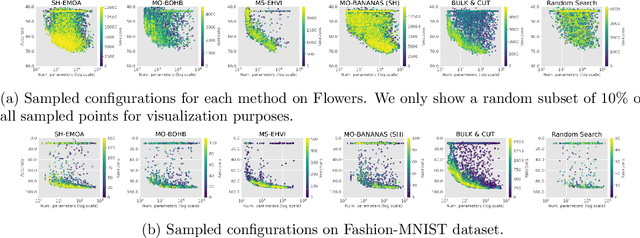
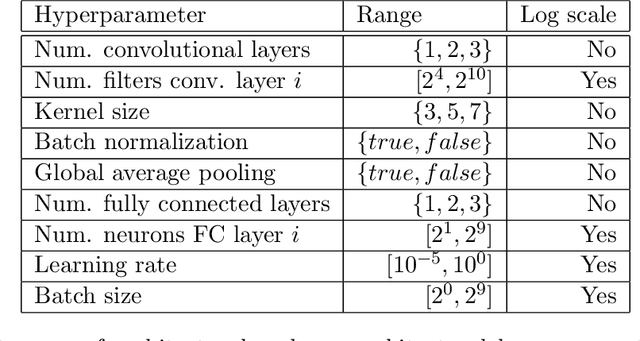
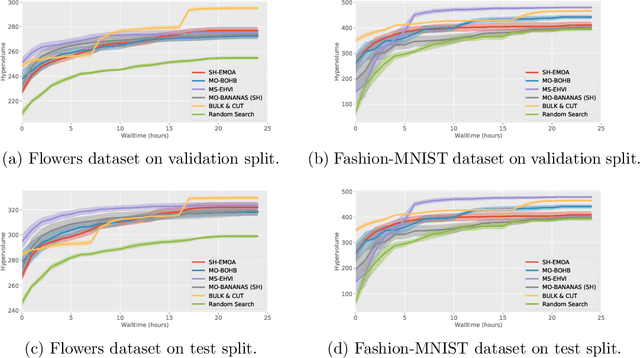
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.