 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Splatter: Feed-Forward View Synthesis with Georeferenced Images
May 19, 2026We present Cross-View Splatter, a feed-forward method that predicts pixel-aligned Gaussian splats for outdoor scenes captured at ground level AND by satellite. Faithful reconstructions require good camera coverage, but ground imagery is time-consuming and hard to capture at scale for large outdoor scenes. Fortunately, satellite imagery can provide a global geometric prior that is easy to access via public APIs. Cross-View Splatter fuses orthorectified satellite views with GPS-tagged ground photos to predict Gaussian splats in a unified 3D coordinate frame. By aligning ground and bird's-eye feature representations, our model improves scene coverage and novel-view synthesis, compared to ground imagery alone. We train on curated georeferenced datasets and paired satellite-terrain data, mined from open mapping services. We evaluate our method on a new benchmark for novel-view synthesis with georeferenced imagery allowing comparison to prior state-of-the-art methods. Our code and data preparation will be available at https://nianticspatial.github.io/cross-view-splatter/.
PlaceIt3D: Language-Guided Object Placement in Real 3D Scenes
May 08, 2025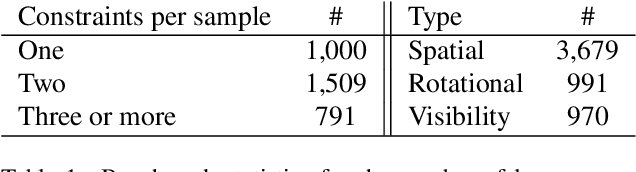
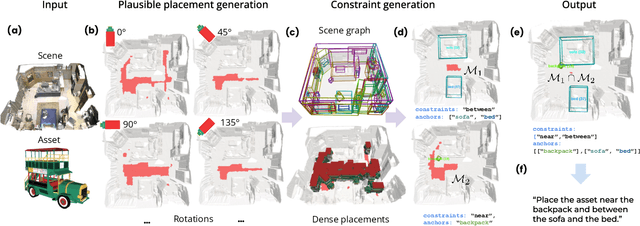
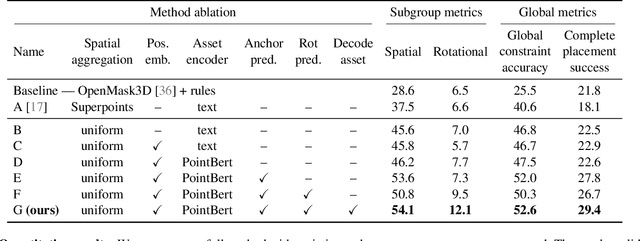
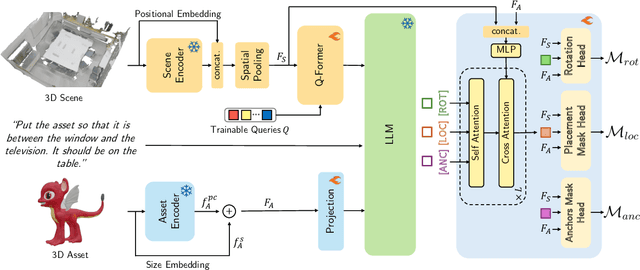
We introduce the novel task of Language-Guided Object Placement in Real 3D Scenes. Our model is given a 3D scene's point cloud, a 3D asset, and a textual prompt broadly describing where the 3D asset should be placed. The task here is to find a valid placement for the 3D asset that respects the prompt. Compared with other language-guided localization tasks in 3D scenes such as grounding, this task has specific challenges: it is ambiguous because it has multiple valid solutions, and it requires reasoning about 3D geometric relationships and free space. We inaugurate this task by proposing a new benchmark and evaluation protocol. We also introduce a new dataset for training 3D LLMs on this task, as well as the first method to serve as a non-trivial baseline. We believe that this challenging task and our new benchmark could become part of the suite of benchmarks used to evaluate and compare generalist 3D LLM models.
MVSAnywhere: Zero-Shot Multi-View Stereo
Mar 28, 2025Computing accurate depth from multiple views is a fundamental and longstanding challenge in computer vision. However, most existing approaches do not generalize well across different domains and scene types (e.g. indoor vs. outdoor). Training a general-purpose multi-view stereo model is challenging and raises several questions, e.g. how to best make use of transformer-based architectures, how to incorporate additional metadata when there is a variable number of input views, and how to estimate the range of valid depths which can vary considerably across different scenes and is typically not known a priori? To address these issues, we introduce MVSA, a novel and versatile Multi-View Stereo architecture that aims to work Anywhere by generalizing across diverse domains and depth ranges. MVSA combines monocular and multi-view cues with an adaptive cost volume to deal with scale-related issues. We demonstrate state-of-the-art zero-shot depth estimation on the Robust Multi-View Depth Benchmark, surpassing existing multi-view stereo and monocular baselines.
HandDGP: Camera-Space Hand Mesh Prediction with Differentiable Global Positioning
Jul 22, 2024
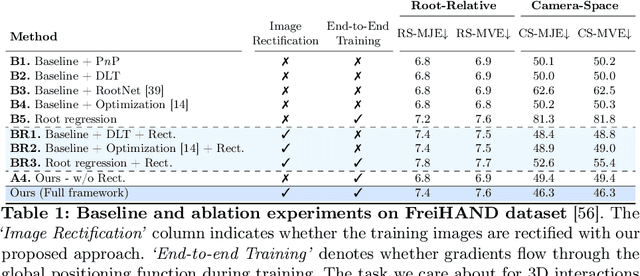
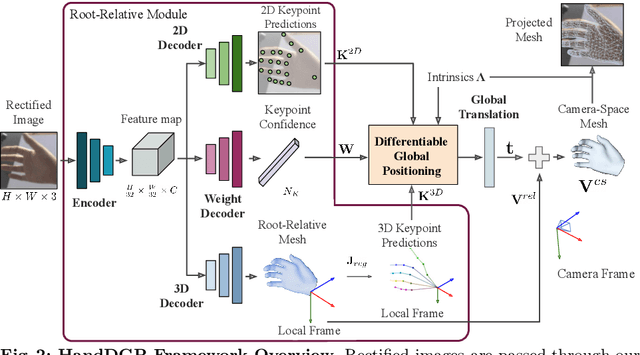
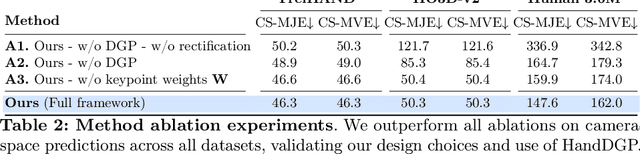
Predicting camera-space hand meshes from single RGB images is crucial for enabling realistic hand interactions in 3D virtual and augmented worlds. Previous work typically divided the task into two stages: given a cropped image of the hand, predict meshes in relative coordinates, followed by lifting these predictions into camera space in a separate and independent stage, often resulting in the loss of valuable contextual and scale information. To prevent the loss of these cues, we propose unifying these two stages into an end-to-end solution that addresses the 2D-3D correspondence problem. This solution enables back-propagation from camera space outputs to the rest of the network through a new differentiable global positioning module. We also introduce an image rectification step that harmonizes both the training dataset and the input image as if they were acquired with the same camera, helping to alleviate the inherent scale-depth ambiguity of the problem. We validate the effectiveness of our framework in evaluations against several baselines and state-of-the-art approaches across three public benchmarks.
DoubleTake: Geometry Guided Depth Estimation
Jun 26, 2024
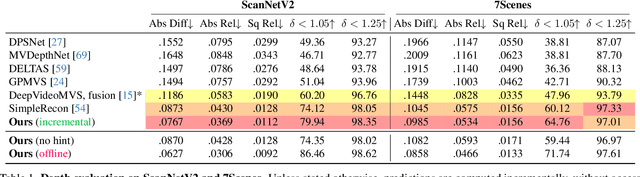
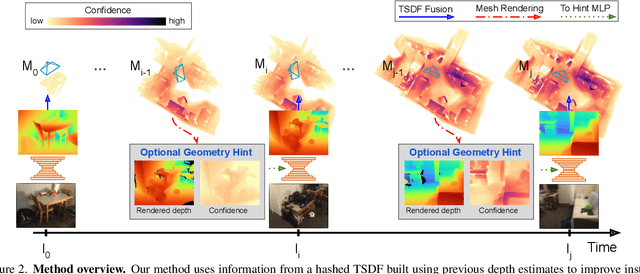
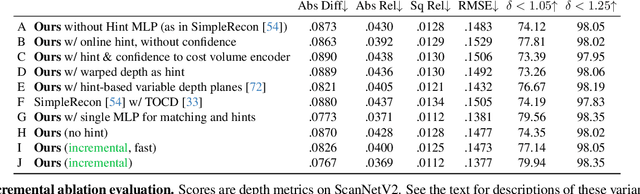
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
Removing Objects From Neural Radiance Fields
Dec 22, 2022Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
Map-free Visual Relocalization: Metric Pose Relative to a Single Image
Oct 11, 2022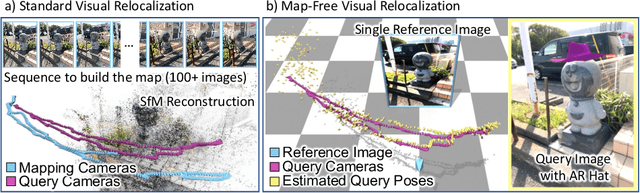

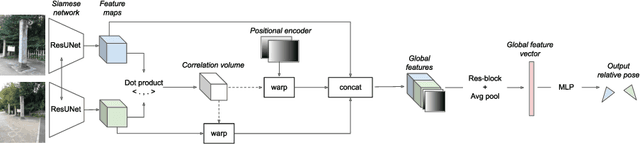

Can we relocalize in a scene represented by a single reference image? Standard visual relocalization requires hundreds of images and scale calibration to build a scene-specific 3D map. In contrast, we propose Map-free Relocalization, i.e., using only one photo of a scene to enable instant, metric scaled relocalization. Existing datasets are not suitable to benchmark map-free relocalization, due to their focus on large scenes or their limited variability. Thus, we have constructed a new dataset of 655 small places of interest, such as sculptures, murals and fountains, collected worldwide. Each place comes with a reference image to serve as a relocalization anchor, and dozens of query images with known, metric camera poses. The dataset features changing conditions, stark viewpoint changes, high variability across places, and queries with low to no visual overlap with the reference image. We identify two viable families of existing methods to provide baseline results: relative pose regression, and feature matching combined with single-image depth prediction. While these methods show reasonable performance on some favorable scenes in our dataset, map-free relocalization proves to be a challenge that requires new, innovative solutions.
Predicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Aug 13, 2020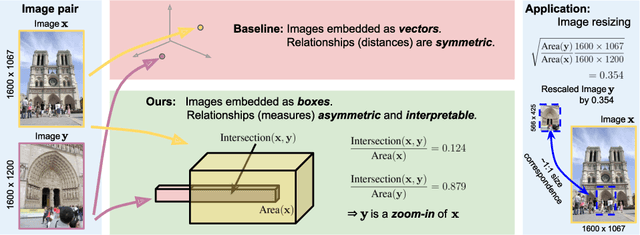
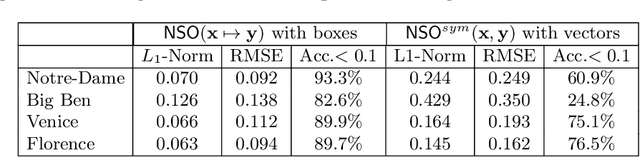

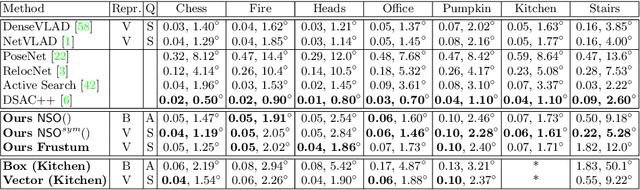
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.
Physics-Based Dexterous Manipulations with Estimated Hand Poses and Residual Reinforcement Learning
Aug 07, 2020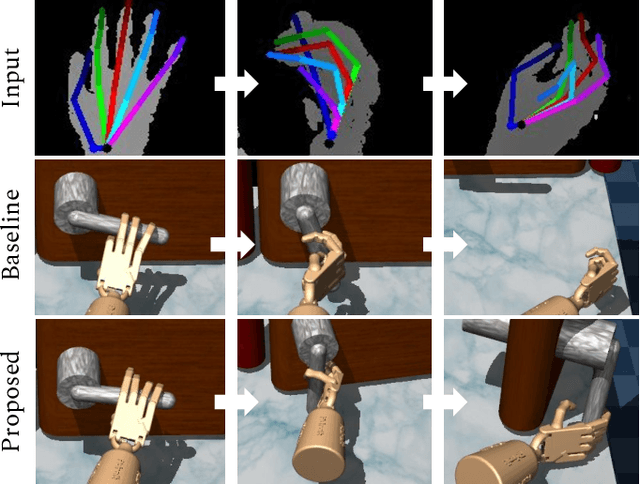
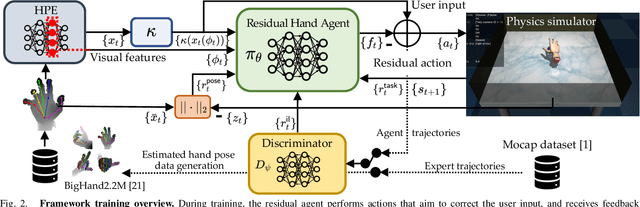
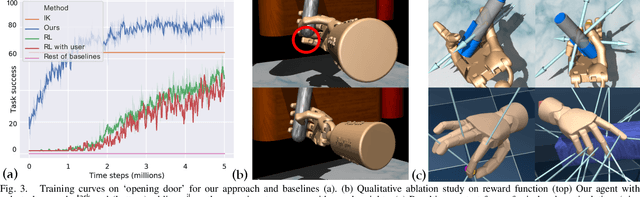
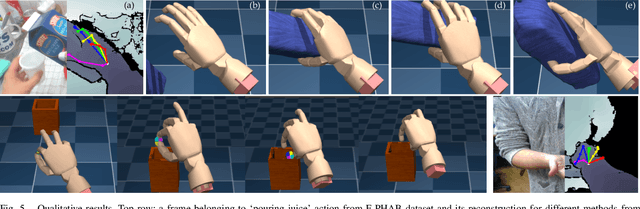
Dexterous manipulation of objects in virtual environments with our bare hands, by using only a depth sensor and a state-of-the-art 3D hand pose estimator (HPE), is challenging. While virtual environments are ruled by physics, e.g. object weights and surface frictions, the absence of force feedback makes the task challenging, as even slight inaccuracies on finger tips or contact points from HPE may make the interactions fail. Prior arts simply generate contact forces in the direction of the fingers' closures, when finger joints penetrate virtual objects. Although useful for simple grasping scenarios, they cannot be applied to dexterous manipulations such as in-hand manipulation. Existing reinforcement learning (RL) and imitation learning (IL) approaches train agents that learn skills by using task-specific rewards, without considering any online user input. In this work, we propose to learn a model that maps noisy input hand poses to target virtual poses, which introduces the needed contacts to accomplish the tasks on a physics simulator. The agent is trained in a residual setting by using a model-free hybrid RL+IL approach. A 3D hand pose estimation reward is introduced leading to an improvement on HPE accuracy when the physics-guided corrected target poses are remapped to the input space. As the model corrects HPE errors by applying minor but crucial joint displacements for contacts, this helps to keep the generated motion visually close to the user input. Since HPE sequences performing successful virtual interactions do not exist, a data generation scheme to train and evaluate the system is proposed. We test our framework in two applications that use hand pose estimates for dexterous manipulations: hand-object interactions in VR and hand-object motion reconstruction in-the-wild.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
Mar 30, 2020
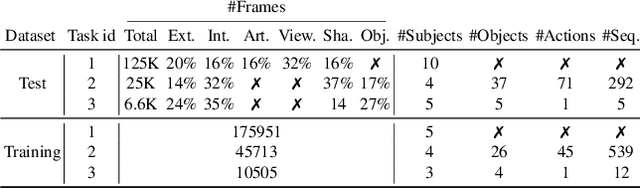
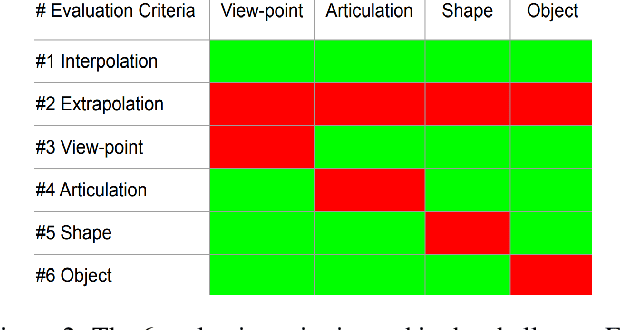
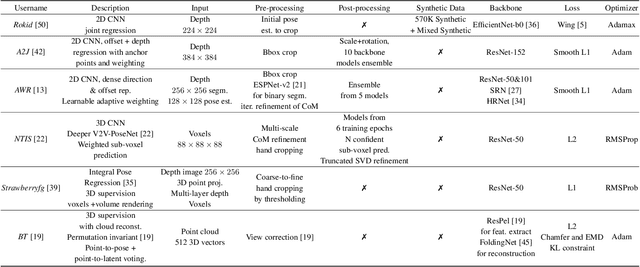
In this work, we study how well different type of approaches generalise in the task of 3D hand pose estimation under hand-object interaction and single hand scenarios. We show that the accuracy of state-of-the-art methods can drop, and that they fail mostly on poses absent from the training set. Unfortunately, since the space of hand poses is highly dimensional, it is inherently not feasible to cover the whole space densely, despite recent efforts in collecting large-scale training datasets. This sampling problem is even more severe when hands are interacting with objects and/or inputs are RGB rather than depth images, as RGB images also vary with lighting conditions and colors. To address these issues, we designed a public challenge to evaluate the abilities of current 3D hand pose estimators~(HPEs) to interpolate and extrapolate the poses of a training set. More exactly, our challenge is designed (a) to evaluate the influence of both depth and color modalities on 3D hand pose estimation, under the presence or absence of objects; (b) to assess the generalisation abilities \wrt~four main axes: shapes, articulations, viewpoints, and objects; (c) to explore the use of a synthetic hand model to fill the gaps of current datasets. Through the challenge, the overall accuracy has dramatically improved over the baseline, especially on extrapolation tasks, from 27mm to 13mm mean joint error. Our analyses highlight the impacts of: Data pre-processing, ensemble approaches, the use of MANO model, and different HPE methods/backbones.