 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling Two Challenges of 6D Object Pose Estimation: Lack of Real Annotated RGB Images and Scalability to Number of Objects
Paper and Code
Mar 27, 2020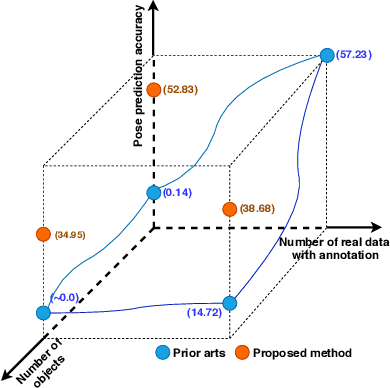
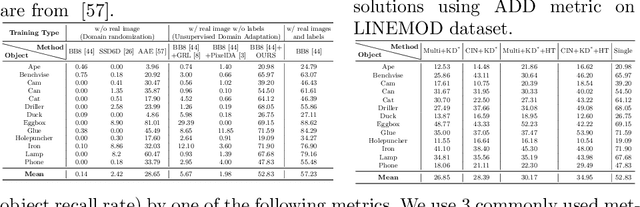
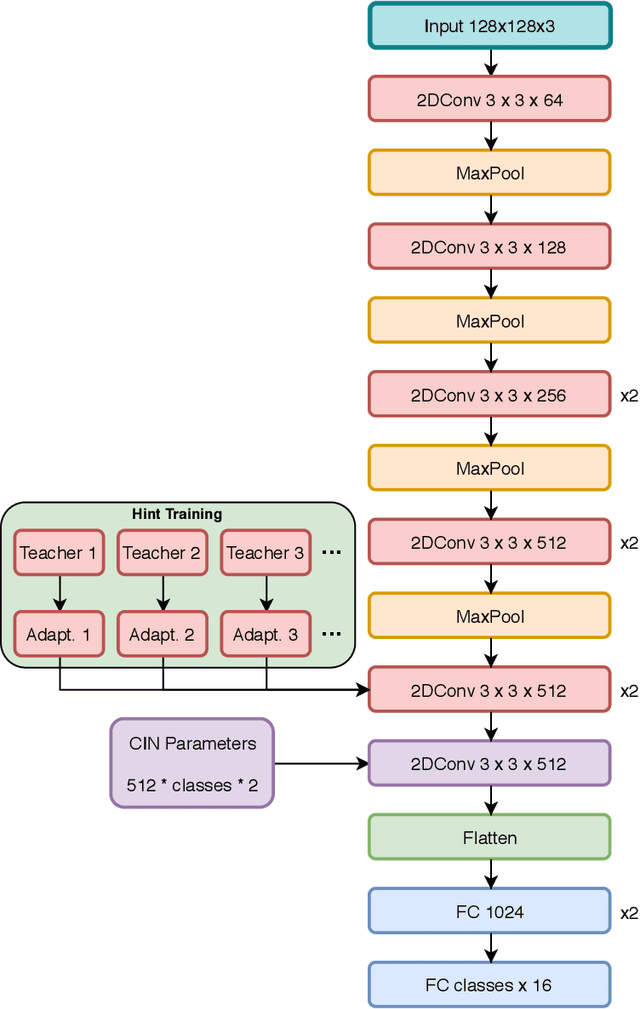
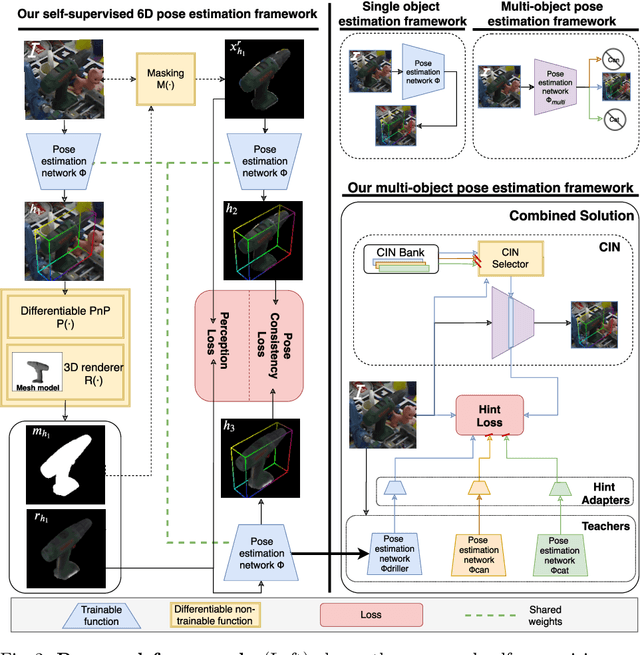
State-of-the-art methods for 6D object pose estimation typically train a Deep Neural Network per object, and its training data first comes from a 3D object mesh. Models trained with synthetic data alone do not generalise well, and training a model for multiple objects sharply drops its accuracy. In this work, we address these two main challenges for 6D object pose estimation and investigate viable methods in experiments. For lack of real RGB data with pose annotations, we propose a novel self-supervision method via pose consistency. For scalability to multiple objects, we apply additional parameterisation to a backbone network and distill knowledge from teachers to a student network for model compression. We further evaluate the combination of the two methods for settings where we are given only synthetic data and a single network for multiple objects. In experiments using LINEMOD, LINEMOD OCCLUSION and T-LESS datasets, the methods significantly boost baseline accuracies and are comparable with the upper bounds, i.e., object specific networks trained on real data with pose labels.