 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Identification of Diffusion-based Image Manipulations
Jun 05, 2025Changing facial expressions, gestures, or background details may dramatically alter the meaning conveyed by an image. Notably, recent advances in diffusion models greatly improve the quality of image manipulation while also opening the door to misuse. Identifying changes made to authentic images, thus, becomes an important task, constantly challenged by new diffusion-based editing tools. To this end, we propose a novel approach for ReliAble iDentification of inpainted AReas (RADAR). RADAR builds on existing foundation models and combines features from different image modalities. It also incorporates an auxiliary contrastive loss that helps to isolate manipulated image patches. We demonstrate these techniques to significantly improve both the accuracy of our method and its generalisation to a large number of diffusion models. To support realistic evaluation, we further introduce BBC-PAIR, a new comprehensive benchmark, with images tampered by 28 diffusion models. Our experiments show that RADAR achieves excellent results, outperforming the state-of-the-art in detecting and localising image edits made by both seen and unseen diffusion models. Our code, data and models will be publicly available at alex-costanzino.github.io/radar.
MAD-Sherlock: Multi-Agent Debates for Out-of-Context Misinformation Detection
Oct 26, 2024



One of the most challenging forms of misinformation involves the out-of-context (OOC) use of images paired with misleading text, creating false narratives. Existing AI-driven detection systems lack explainability and require expensive fine-tuning. We address these issues with MAD-Sherlock: a Multi-Agent Debate system for OOC Misinformation Detection. MAD-Sherlock introduces a novel multi-agent debate framework where multimodal agents collaborate to assess contextual consistency and request external information to enhance cross-context reasoning and decision-making. Our framework enables explainable detection with state-of-the-art accuracy even without domain-specific fine-tuning. Extensive ablation studies confirm that external retrieval significantly improves detection accuracy, and user studies demonstrate that MAD-Sherlock boosts performance for both experts and non-experts. These results position MAD-Sherlock as a powerful tool for autonomous and citizen intelligence applications.
Toward Robust Real-World Audio Deepfake Detection: Closing the Explainability Gap
Oct 09, 2024



The rapid proliferation of AI-manipulated or generated audio deepfakes poses serious challenges to media integrity and election security. Current AI-driven detection solutions lack explainability and underperform in real-world settings. In this paper, we introduce novel explainability methods for state-of-the-art transformer-based audio deepfake detectors and open-source a novel benchmark for real-world generalizability. By narrowing the explainability gap between transformer-based audio deepfake detectors and traditional methods, our results not only build trust with human experts, but also pave the way for unlocking the potential of citizen intelligence to overcome the scalability issue in audio deepfake detection.
Tackling Two Challenges of 6D Object Pose Estimation: Lack of Real Annotated RGB Images and Scalability to Number of Objects
Mar 27, 2020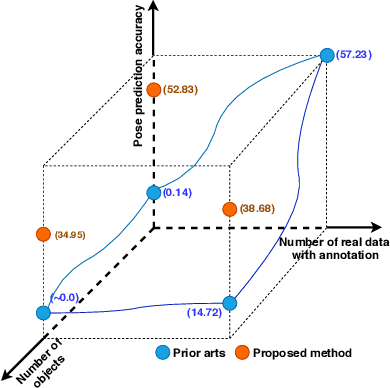
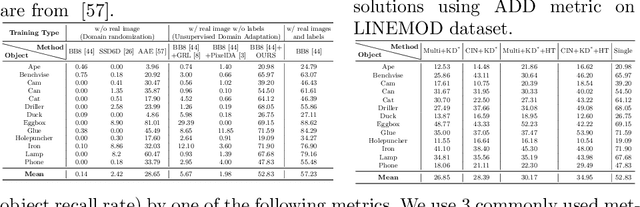
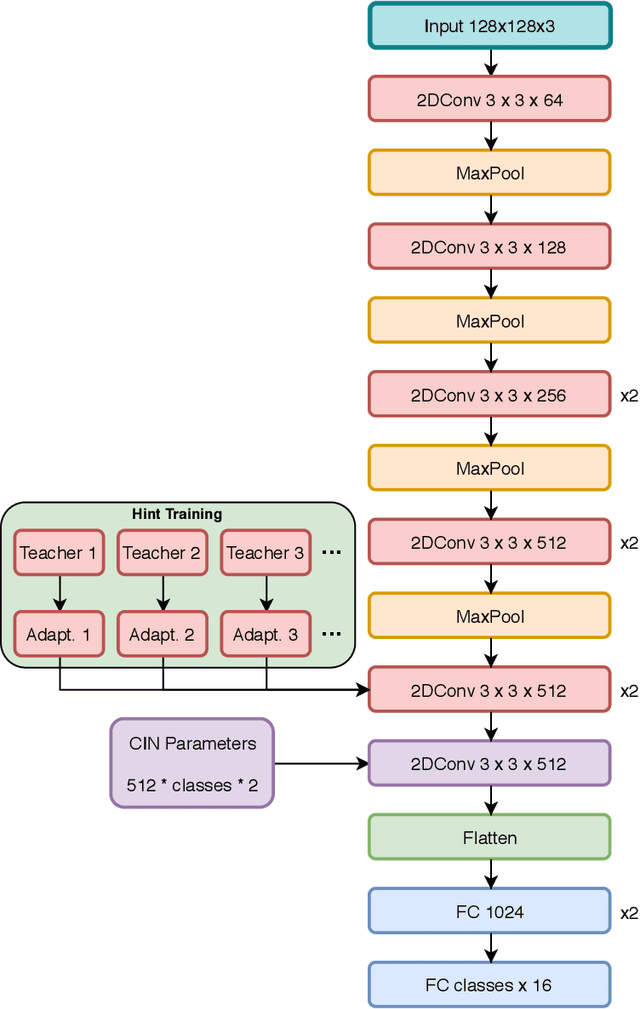
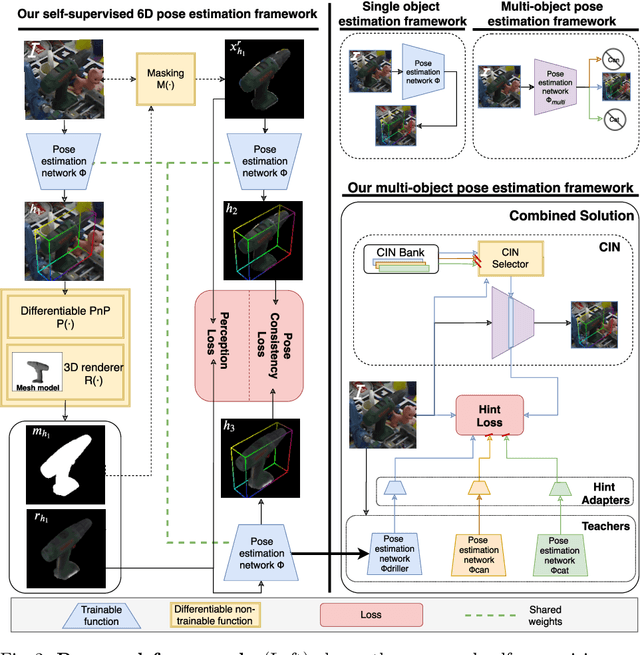
State-of-the-art methods for 6D object pose estimation typically train a Deep Neural Network per object, and its training data first comes from a 3D object mesh. Models trained with synthetic data alone do not generalise well, and training a model for multiple objects sharply drops its accuracy. In this work, we address these two main challenges for 6D object pose estimation and investigate viable methods in experiments. For lack of real RGB data with pose annotations, we propose a novel self-supervision method via pose consistency. For scalability to multiple objects, we apply additional parameterisation to a backbone network and distill knowledge from teachers to a student network for model compression. We further evaluate the combination of the two methods for settings where we are given only synthetic data and a single network for multiple objects. In experiments using LINEMOD, LINEMOD OCCLUSION and T-LESS datasets, the methods significantly boost baseline accuracies and are comparable with the upper bounds, i.e., object specific networks trained on real data with pose labels.
A Review on Object Pose Recovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
Jan 28, 2020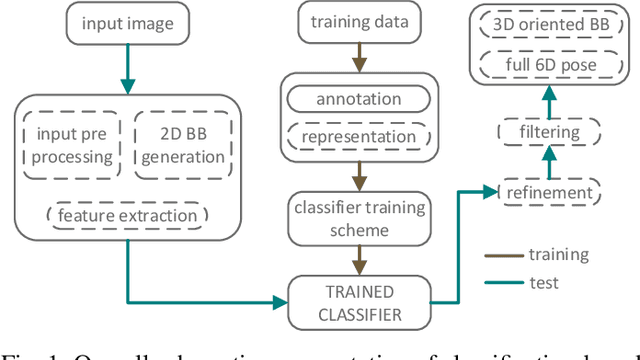
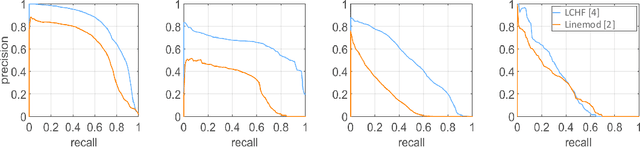
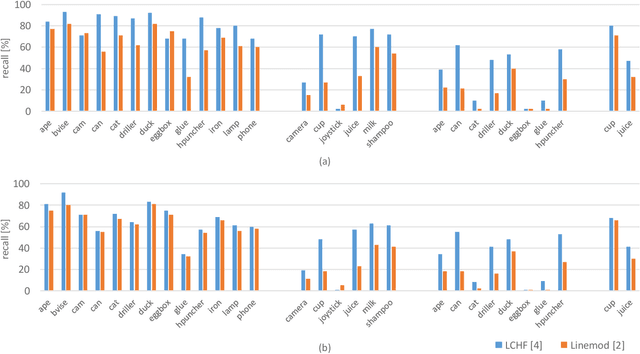
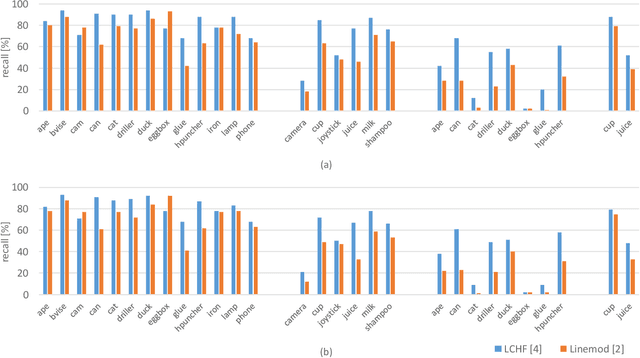
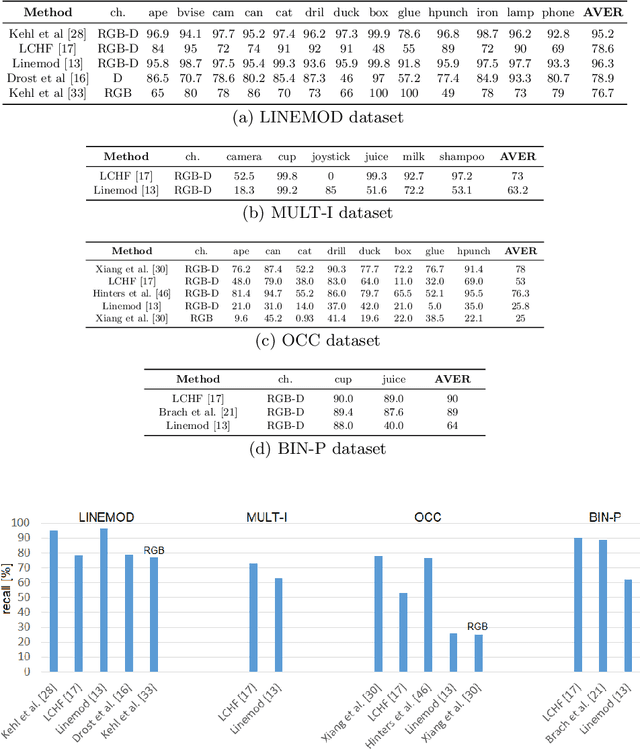
Object pose recovery has gained increasing attention in the computer vision field as it has become an important problem in rapidly evolving technological areas related to autonomous driving, robotics, and augmented reality. Existing review-related studies have addressed the problem at visual level in 2D, going through the methods which produce 2D bounding boxes of objects of interest in RGB images. The 2D search space is enlarged either using the geometry information available in the 3D space along with RGB (Mono/Stereo) images, or utilizing depth data from LIDAR sensors and/or RGB-D cameras. 3D bounding box detectors, producing category-level amodal 3D bounding boxes, are evaluated on gravity aligned images, while full 6D object pose estimators are mostly tested at instance-level on the images where the alignment constraint is removed. Recently, 6D object pose estimation is tackled at the level of categories. In this paper, we present the first comprehensive and most recent review of the methods on object pose recovery, from 3D bounding box detectors to full 6D pose estimators. The methods mathematically model the problem as a classification, regression, classification & regression, template matching, and point-pair feature matching task. Based on this, a mathematical-model-based categorization of the methods is established. Datasets used for evaluating the methods are investigated with respect to the challenges, and evaluation metrics are studied. Quantitative results of experiments in the literature are analysed to show which category of methods best performs across what types of challenges. The analyses are further extended comparing two methods, which are our own implementations, so that the outcomes from the public results are further solidified. Current position of the field is summarized regarding object pose recovery, and possible research directions are identified.
Active 6D Multi-Object Pose Estimation in Cluttered Scenarios with Deep Reinforcement Learning
Oct 19, 2019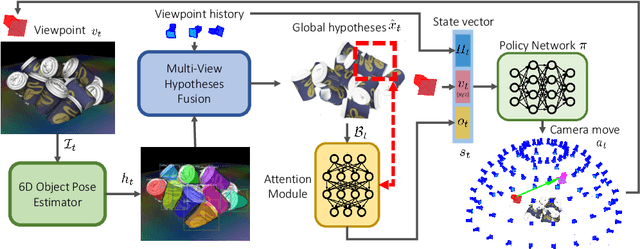
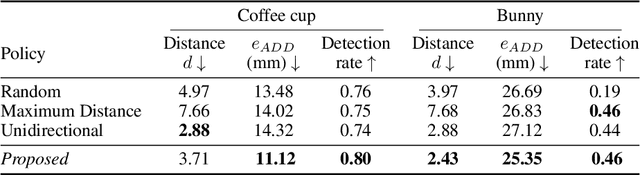
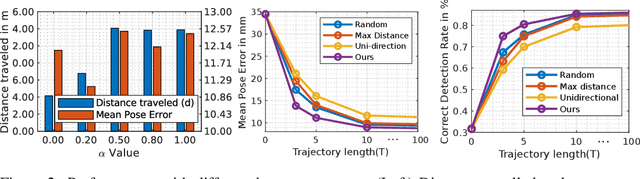

In this work, we explore how a strategic selection of camera movements can facilitate the task of 6D multi-object pose estimation in cluttered scenarios while respecting real-world constraints important in robotics and augmented reality applications, such as time and distance traveled. In the proposed framework, a set of multiple object hypotheses is given to an agent, which is inferred by an object pose estimator and subsequently spatio-temporally selected by a fusion function that makes use of a verification score that circumvents the need of ground-truth annotations. The agent reasons about these hypotheses, directing its attention to the object which it is most uncertain about, moving the camera towards such an object. Unlike previous works that propose short-sighted policies, our agent is trained in simulated scenarios using reinforcement learning, attempting to learn the camera moves that produce the most accurate object poses hypotheses for a given temporal and spatial budget, without the need of viewpoints rendering during inference. Our experiments show that the proposed approach successfully estimates the 6D object pose of a stack of objects in both challenging cluttered synthetic and real scenarios, showing superior performance compared to strong baselines.
Instance- and Category-level 6D Object Pose Estimation
Mar 11, 2019

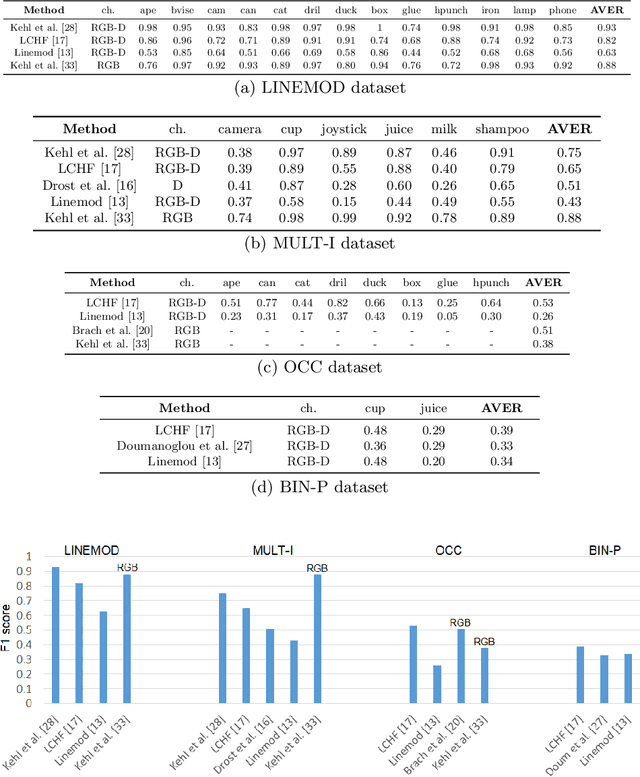
6D object pose estimation is an important task that determines the 3D position and 3D rotation of an object in camera-centred coordinates. By utilizing such a task, one can propose promising solutions for various problems related to scene understanding, augmented reality, control and navigation of robotics. Recent developments on visual depth sensors and low-cost availability of depth data significantly facilitate object pose estimation. Using depth information from RGB-D sensors, substantial progress has been made in the last decade by the methods addressing the challenges such as viewpoint variability, occlusion and clutter, and similar looking distractors. Particularly, with the recent advent of convolutional neural networks, RGB-only based solutions have been presented. However, improved results have only been reported for recovering the pose of known instances, i.e., for the instance-level object pose estimation tasks. More recently, state-of-the-art approaches target to solve object pose estimation problem at the level of categories, recovering the 6D pose of unknown instances. To this end, they address the challenges of the category-level tasks such as distribution shift among source and target domains, high intra-class variations, and shape discrepancies between objects.
Multi-Task Deep Networks for Depth-Based 6D Object Pose and Joint Registration in Crowd Scenarios
Jun 11, 2018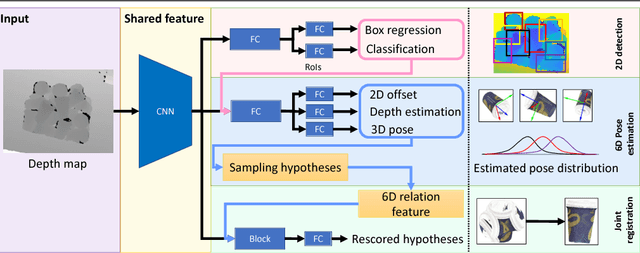


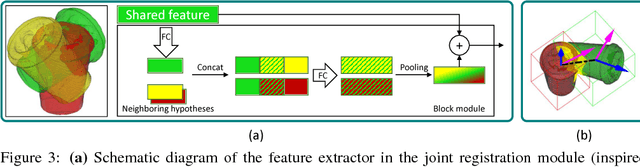
In bin-picking scenarios, multiple instances of an object of interest are stacked in a pile randomly, and hence, the instances are inherently subjected to the challenges: severe occlusion, clutter, and similar-looking distractors. Most existing methods are, however, for single isolated object instances, while some recent methods tackle crowd scenarios as post-refinement which accounts multiple object relations. In this paper, we address recovering 6D poses of multiple instances in bin-picking scenarios in depth modality by multi-task learning in deep neural networks. Our architecture jointly learns multiple sub-tasks: 2D detection, depth, and 3D pose estimation of individual objects; and joint registration of multiple objects. For training data generation, depth images of physically plausible object pose configurations are generated by a 3D object model in a physics simulation, which yields diverse occlusion patterns to learn. We adopt a state-of-the-art object detector, and 2D offsets are further estimated via a network to refine misaligned 2D detections. The depth and 3D pose estimator is designed to generate multiple hypotheses per detection. This allows the joint registration network to learn occlusion patterns and remove physically implausible pose hypotheses. We apply our architecture on both synthetic (our own and Sileane dataset) and real (a public Bin-Picking dataset) data, showing that it significantly outperforms state-of-the-art methods by 15-31% in average precision.