 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Identification of Diffusion-based Image Manipulations
Jun 05, 2025Changing facial expressions, gestures, or background details may dramatically alter the meaning conveyed by an image. Notably, recent advances in diffusion models greatly improve the quality of image manipulation while also opening the door to misuse. Identifying changes made to authentic images, thus, becomes an important task, constantly challenged by new diffusion-based editing tools. To this end, we propose a novel approach for ReliAble iDentification of inpainted AReas (RADAR). RADAR builds on existing foundation models and combines features from different image modalities. It also incorporates an auxiliary contrastive loss that helps to isolate manipulated image patches. We demonstrate these techniques to significantly improve both the accuracy of our method and its generalisation to a large number of diffusion models. To support realistic evaluation, we further introduce BBC-PAIR, a new comprehensive benchmark, with images tampered by 28 diffusion models. Our experiments show that RADAR achieves excellent results, outperforming the state-of-the-art in detecting and localising image edits made by both seen and unseen diffusion models. Our code, data and models will be publicly available at alex-costanzino.github.io/radar.
PeQuENet: Perceptual Quality Enhancement of Compressed Video with Adaptation- and Attention-based Network
Jun 16, 2022

In this paper we propose a generative adversarial network (GAN) framework to enhance the perceptual quality of compressed videos. Our framework includes attention and adaptation to different quantization parameters (QPs) in a single model. The attention module exploits global receptive fields that can capture and align long-range correlations between consecutive frames, which can be beneficial for enhancing perceptual quality of videos. The frame to be enhanced is fed into the deep network together with its neighboring frames, and in the first stage features at different depths are extracted. Then extracted features are fed into attention blocks to explore global temporal correlations, followed by a series of upsampling and convolution layers. Finally, the resulting features are processed by the QP-conditional adaptation module which leverages the corresponding QP information. In this way, a single model can be used to enhance adaptively to various QPs without requiring multiple models specific for every QP value, while having similar performance. Experimental results demonstrate the superior performance of the proposed PeQuENet compared with the state-of-the-art compressed video quality enhancement algorithms.
Multi-encoder Network for Parameter Reduction of a Kernel-based Interpolation Architecture
May 13, 2022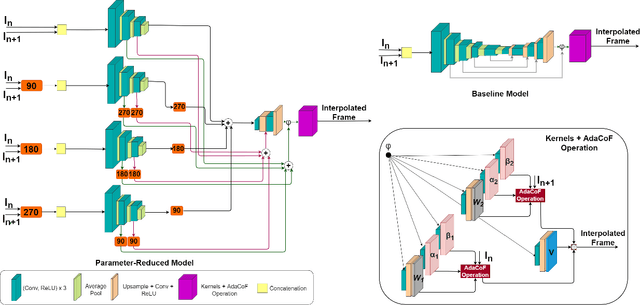
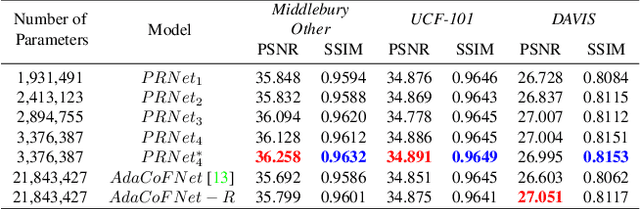


Video frame interpolation involves the synthesis of new frames from existing ones. Convolutional neural networks (CNNs) have been at the forefront of the recent advances in this field. One popular CNN-based approach involves the application of generated kernels to the input frames to obtain an interpolated frame. Despite all the benefits interpolation methods offer, many of these networks require a lot of parameters, with more parameters meaning a heavier computational burden. Reducing the size of the model typically impacts performance negatively. This paper presents a method for parameter reduction for a popular flow-less kernel-based network (Adaptive Collaboration of Flows). Through our technique of removing the layers that require the most parameters and replacing them with smaller encoders, we reduce the number of parameters of the network and even achieve better performance compared to the original method. This is achieved by deploying rotation to force each individual encoder to learn different features from the input images. Ablations are conducted to justify design choices and an evaluation on how our method performs on full-length videos is presented.
DCNGAN: A Deformable Convolutional-Based GAN with QP Adaptation for Perceptual Quality Enhancement of Compressed Video
Jan 28, 2022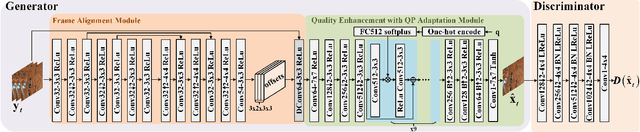
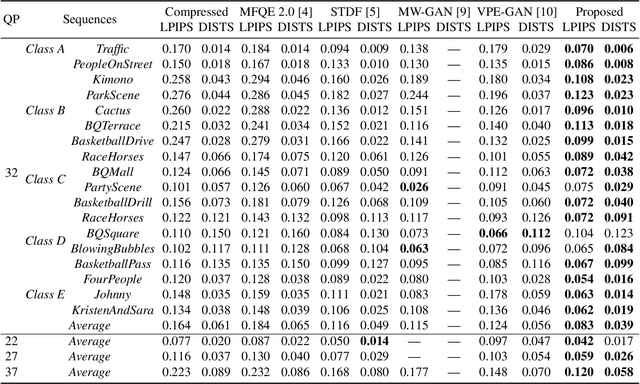

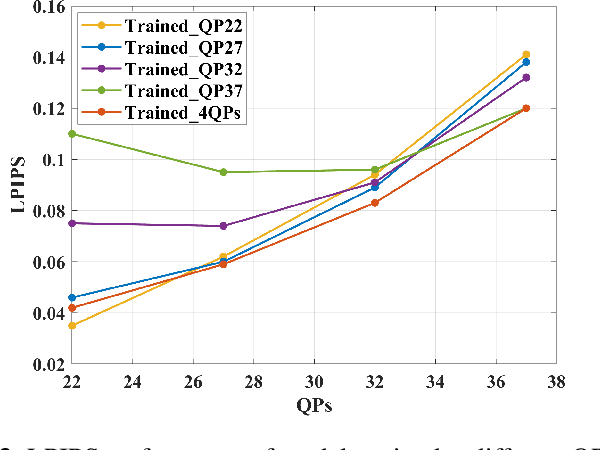
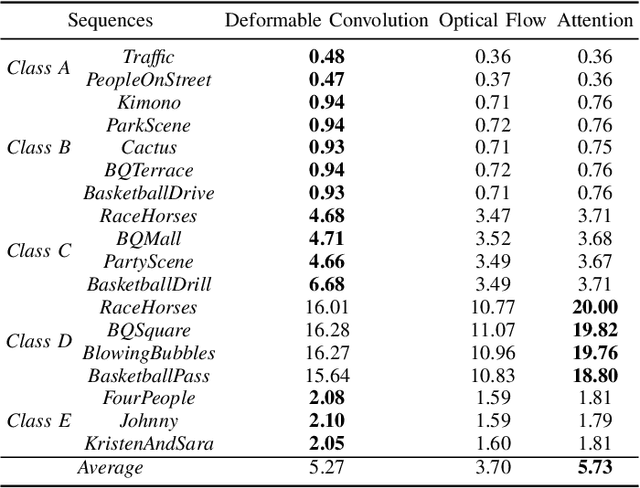
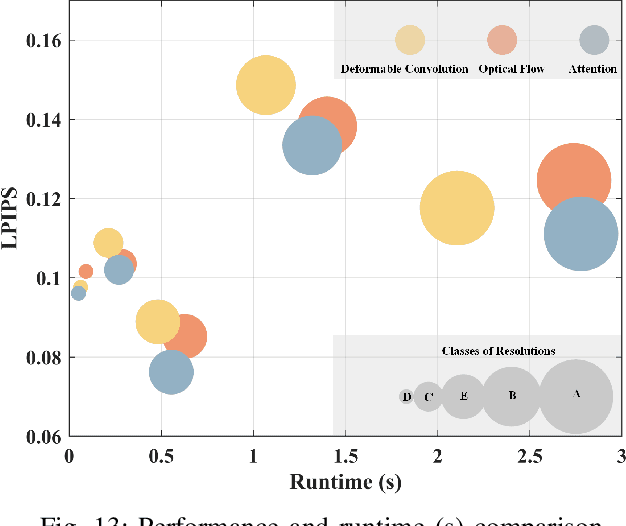
In this paper, we propose a deformable convolution-based generative adversarial network (DCNGAN) for perceptual quality enhancement of compressed videos. DCNGAN is also adaptive to the quantization parameters (QPs). Compared with optical flows, deformable convolutions are more effective and efficient to align frames. Deformable convolutions can operate on multiple frames, thus leveraging more temporal information, which is beneficial for enhancing the perceptual quality of compressed videos. Instead of aligning frames in a pairwise manner, the deformable convolution can process multiple frames simultaneously, which leads to lower computational complexity. Experimental results demonstrate that the proposed DCNGAN outperforms other state-of-the-art compressed video quality enhancement algorithms.
Towards Transparent Application of Machine Learning in Video Processing
May 27, 2021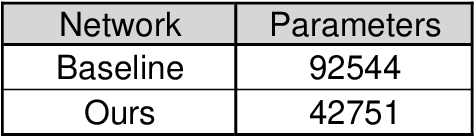
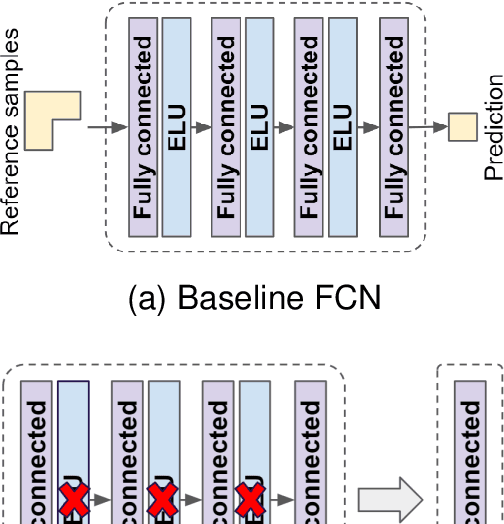
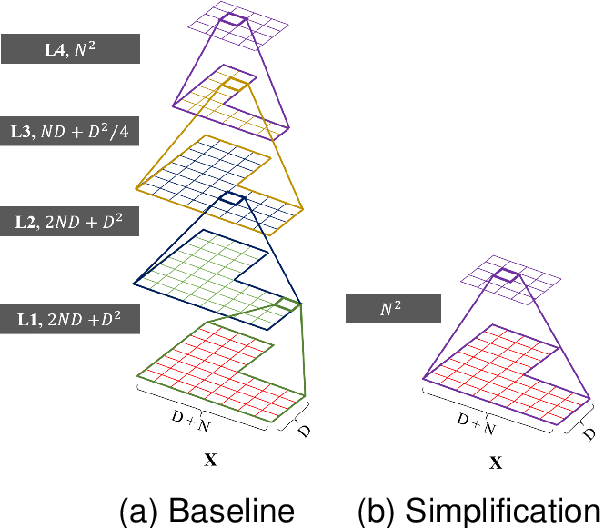
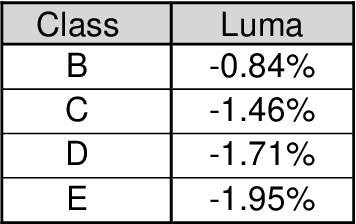
Machine learning techniques for more efficient video compression and video enhancement have been developed thanks to breakthroughs in deep learning. The new techniques, considered as an advanced form of Artificial Intelligence (AI), bring previously unforeseen capabilities. However, they typically come in the form of resource-hungry black-boxes (overly complex with little transparency regarding the inner workings). Their application can therefore be unpredictable and generally unreliable for large-scale use (e.g. in live broadcast). The aim of this work is to understand and optimise learned models in video processing applications so systems that incorporate them can be used in a more trustworthy manner. In this context, the presented work introduces principles for simplification of learned models targeting improved transparency in implementing machine learning for video production and distribution applications. These principles are demonstrated on video compression examples, showing how bitrate savings and reduced complexity can be achieved by simplifying relevant deep learning models.
Attention-based Stylisation for Exemplar Image Colourisation
May 04, 2021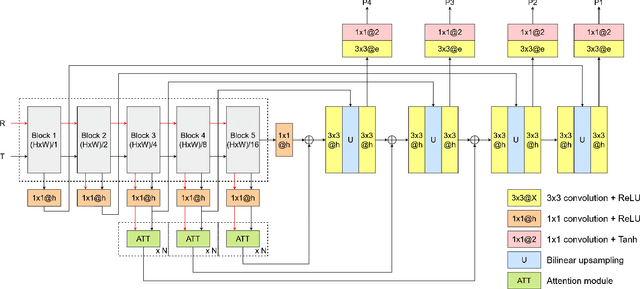
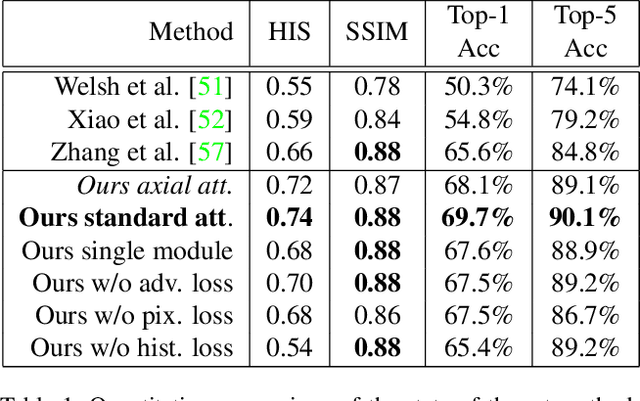
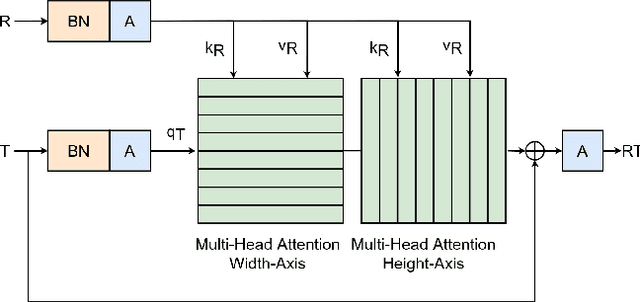
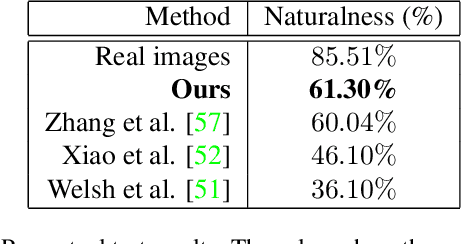
Exemplar-based colourisation aims to add plausible colours to a grayscale image using the guidance of a colour reference image. Most of the existing methods tackle the task as a style transfer problem, using a convolutional neural network (CNN) to obtain deep representations of the content of both inputs. Stylised outputs are then obtained by computing similarities between both feature representations in order to transfer the style of the reference to the content of the target input. However, in order to gain robustness towards dissimilar references, the stylised outputs need to be refined with a second colourisation network, which significantly increases the overall system complexity. This work reformulates the existing methodology introducing a novel end-to-end colourisation network that unifies the feature matching with the colourisation process. The proposed architecture integrates attention modules at different resolutions that learn how to perform the style transfer task in an unsupervised way towards decoding realistic colour predictions. Moreover, axial attention is proposed to simplify the attention operations and to obtain a fast but robust cost-effective architecture. Experimental validations demonstrate efficiency of the proposed methodology which generates high quality and visual appealing colourisation. Furthermore, the complexity of the proposed methodology is reduced compared to the state-of-the-art methods.