 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transparent Application of Machine Learning in Video Processing
May 27, 2021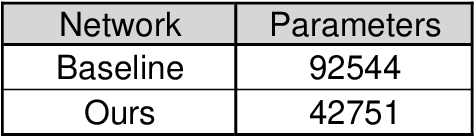
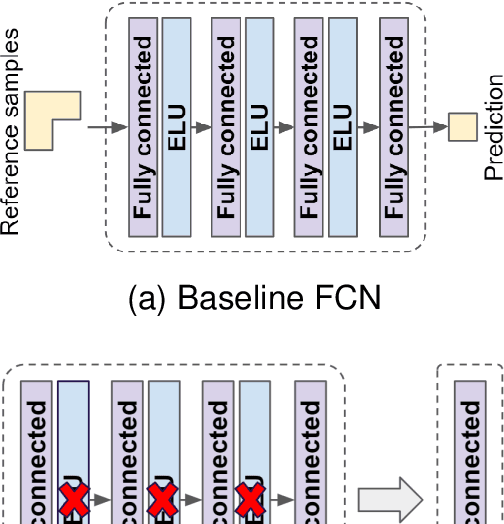
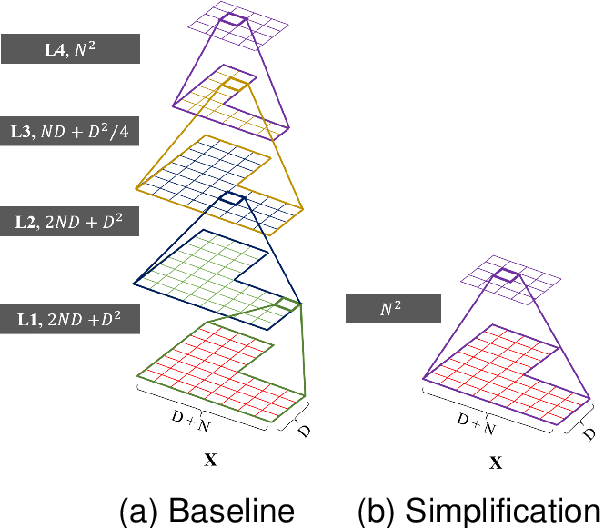
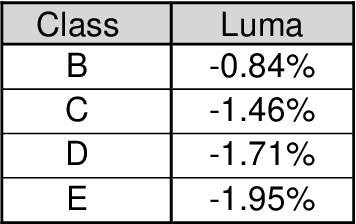
Machine learning techniques for more efficient video compression and video enhancement have been developed thanks to breakthroughs in deep learning. The new techniques, considered as an advanced form of Artificial Intelligence (AI), bring previously unforeseen capabilities. However, they typically come in the form of resource-hungry black-boxes (overly complex with little transparency regarding the inner workings). Their application can therefore be unpredictable and generally unreliable for large-scale use (e.g. in live broadcast). The aim of this work is to understand and optimise learned models in video processing applications so systems that incorporate them can be used in a more trustworthy manner. In this context, the presented work introduces principles for simplification of learned models targeting improved transparency in implementing machine learning for video production and distribution applications. These principles are demonstrated on video compression examples, showing how bitrate savings and reduced complexity can be achieved by simplifying relevant deep learning models.