 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Convolution and Transformer-Based Network for Video Frame Interpolation
Jul 12, 2023
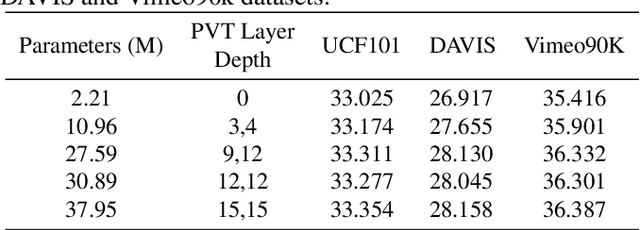
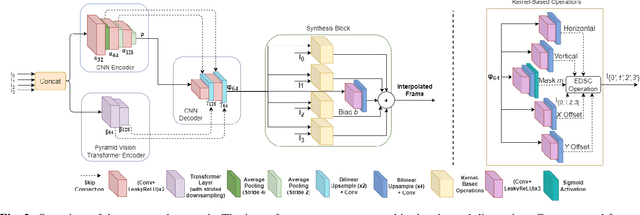

Video frame interpolation is an increasingly important research task with several key industrial applications in the video coding, broadcast and production sectors. Recently, transformers have been introduced to the field resulting in substantial performance gains. However, this comes at a cost of greatly increased memory usage, training and inference time. In this paper, a novel method integrating a transformer encoder and convolutional features is proposed. This network reduces the memory burden by close to 50% and runs up to four times faster during inference time compared to existing transformer-based interpolation methods. A dual-encoder architecture is introduced which combines the strength of convolutions in modelling local correlations with those of the transformer for long-range dependencies. Quantitative evaluations are conducted on various benchmarks with complex motion to showcase the robustness of the proposed method, achieving competitive performance compared to state-of-the-art interpolation networks.
Query-based Video Summarization with Pseudo Label Supervision
Jul 04, 2023Existing datasets for manually labelled query-based video summarization are costly and thus small, limiting the performance of supervised deep video summarization models. Self-supervision can address the data sparsity challenge by using a pretext task and defining a method to acquire extra data with pseudo labels to pre-train a supervised deep model. In this work, we introduce segment-level pseudo labels from input videos to properly model both the relationship between a pretext task and a target task, and the implicit relationship between the pseudo label and the human-defined label. The pseudo labels are generated based on existing human-defined frame-level labels. To create more accurate query-dependent video summaries, a semantics booster is proposed to generate context-aware query representations. Furthermore, we propose mutual attention to help capture the interactive information between visual and textual modalities. Three commonly-used video summarization benchmarks are used to thoroughly validate the proposed approach. Experimental results show that the proposed video summarization algorithm achieves state-of-the-art performance.
Complexity Reduction of Learned In-Loop Filtering in Video Coding
Mar 17, 2022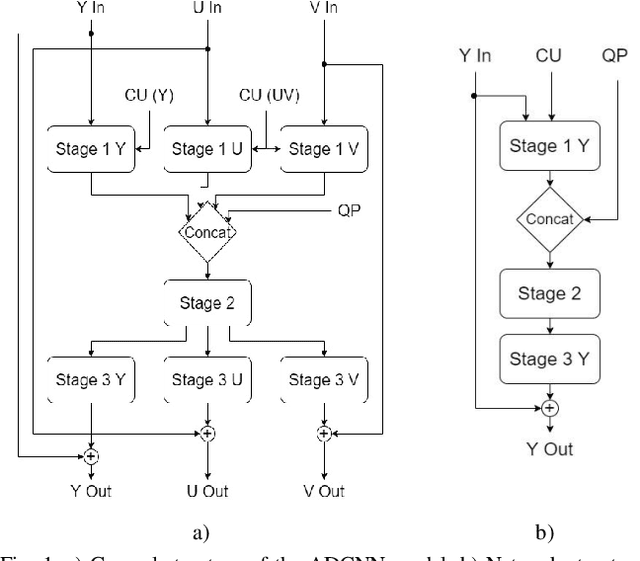
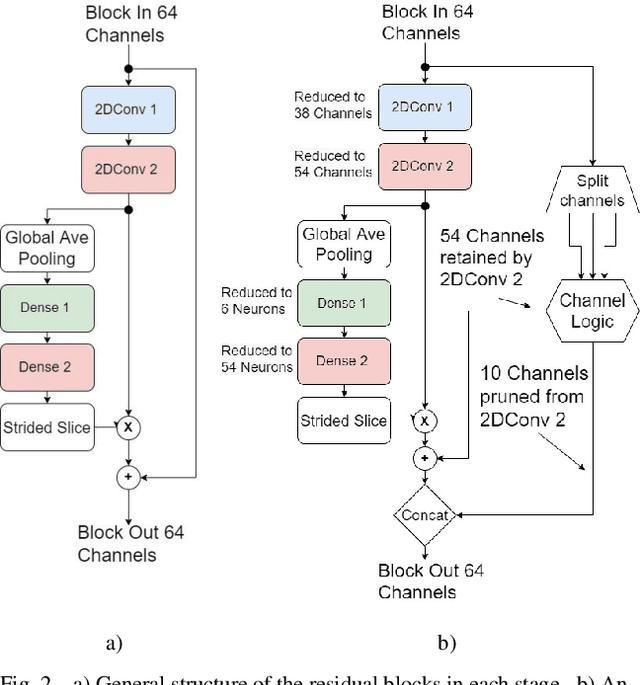
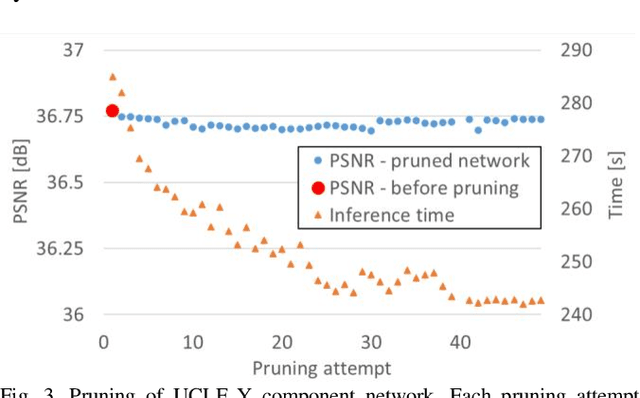
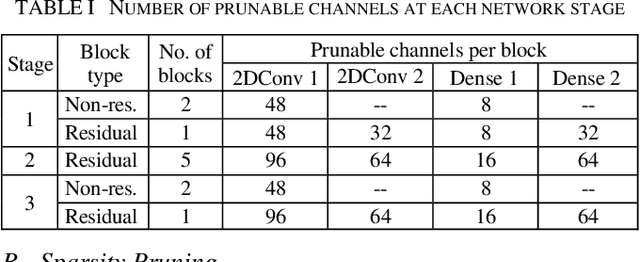
In video coding, in-loop filters are applied on reconstructed video frames to enhance their perceptual quality, before storing the frames for output. Conventional in-loop filters are obtained by hand-crafted methods. Recently, learned filters based on convolutional neural networks that utilize attention mechanisms have been shown to improve upon traditional techniques. However, these solutions are typically significantly more computationally expensive, limiting their potential for practical applications. The proposed method uses a novel combination of sparsity and structured pruning for complexity reduction of learned in-loop filters. This is done through a three-step training process of magnitude-guidedweight pruning, insignificant neuron identification and removal, and fine-tuning. Through initial tests we find that network parameters can be significantly reduced with a minimal impact on network performance.
Improved CNN-based Learning of Interpolation Filters for Low-Complexity Inter Prediction in Video Coding
Jun 16, 2021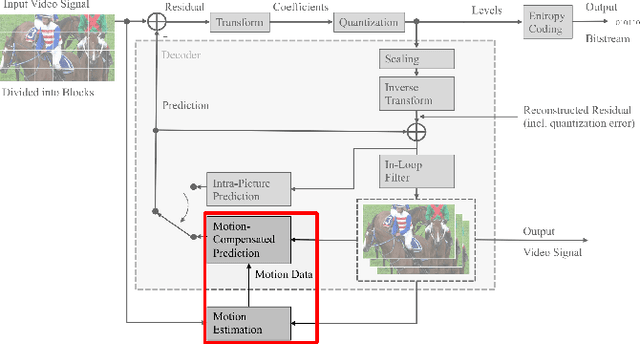
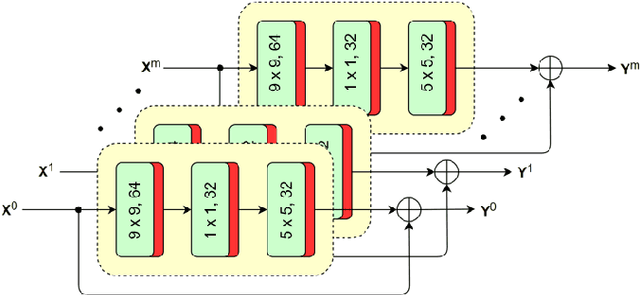
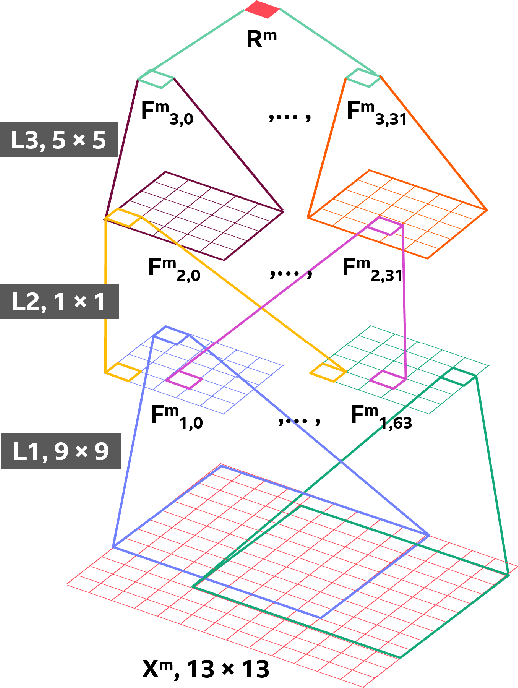
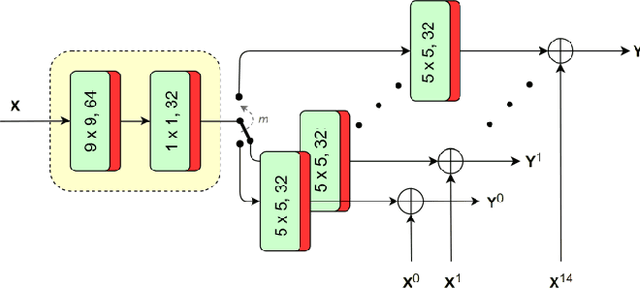
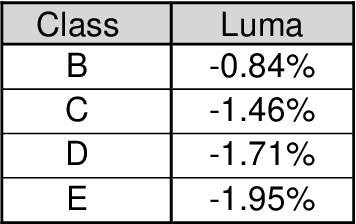
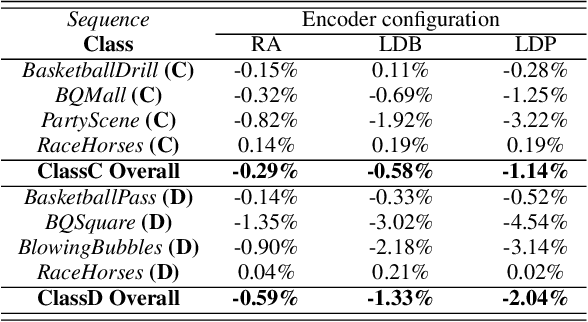
The versatility of recent machine learning approaches makes them ideal for improvement of next generation video compression solutions. Unfortunately, these approaches typically bring significant increases in computational complexity and are difficult to interpret into explainable models, affecting their potential for implementation within practical video coding applications. This paper introduces a novel explainable neural network-based inter-prediction scheme, to improve the interpolation of reference samples needed for fractional precision motion compensation. The approach requires a single neural network to be trained from which a full quarter-pixel interpolation filter set is derived, as the network is easily interpretable due to its linear structure. A novel training framework enables each network branch to resemble a specific fractional shift. This practical solution makes it very efficient to use alongside conventional video coding schemes. When implemented in the context of the state-of-the-art Versatile Video Coding (VVC) test model, 0.77%, 1.27% and 2.25% BD-rate savings can be achieved on average for lower resolution sequences under the random access, low-delay B and low-delay P configurations, respectively, while the complexity of the learned interpolation schemes is significantly reduced compared to the interpolation with full CNNs.
Towards Transparent Application of Machine Learning in Video Processing
May 27, 2021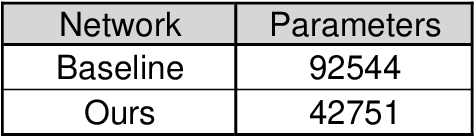
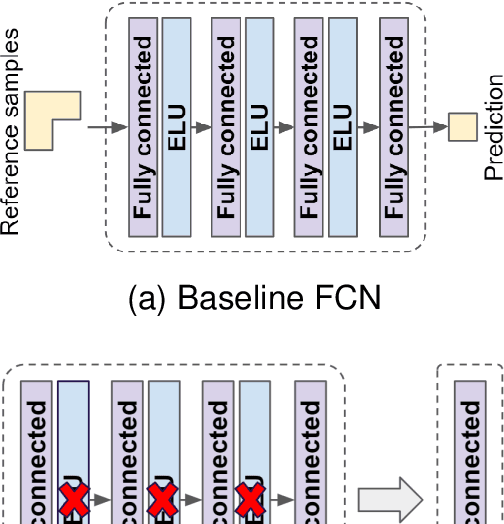
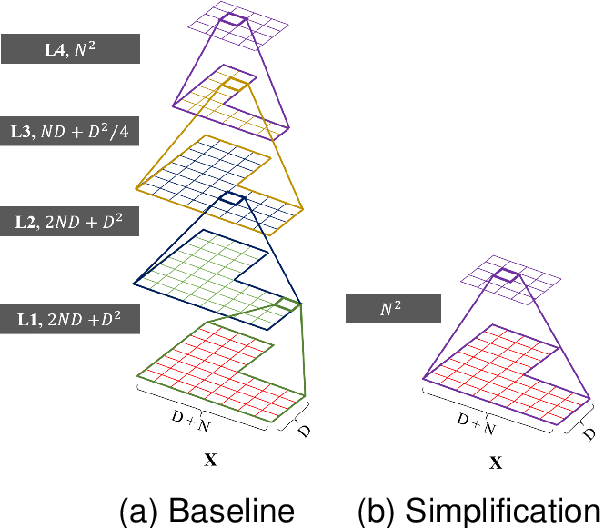
Machine learning techniques for more efficient video compression and video enhancement have been developed thanks to breakthroughs in deep learning. The new techniques, considered as an advanced form of Artificial Intelligence (AI), bring previously unforeseen capabilities. However, they typically come in the form of resource-hungry black-boxes (overly complex with little transparency regarding the inner workings). Their application can therefore be unpredictable and generally unreliable for large-scale use (e.g. in live broadcast). The aim of this work is to understand and optimise learned models in video processing applications so systems that incorporate them can be used in a more trustworthy manner. In this context, the presented work introduces principles for simplification of learned models targeting improved transparency in implementing machine learning for video production and distribution applications. These principles are demonstrated on video compression examples, showing how bitrate savings and reduced complexity can be achieved by simplifying relevant deep learning models.
GPT2MVS: Generative Pre-trained Transformer-2 for Multi-modal Video Summarization
Apr 26, 2021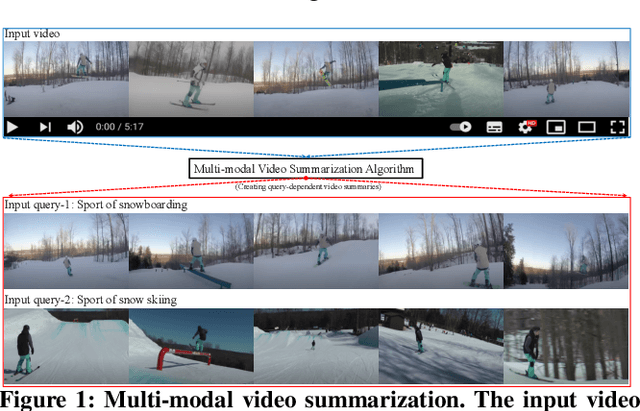
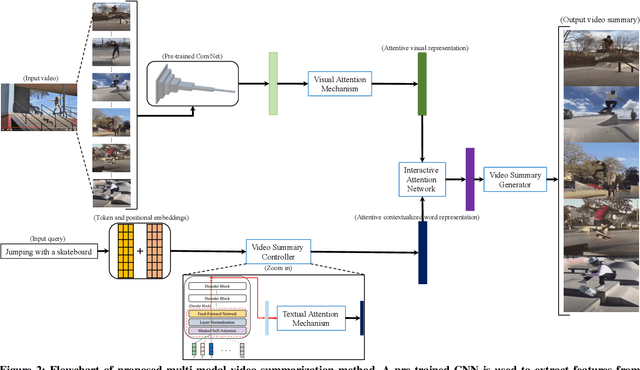
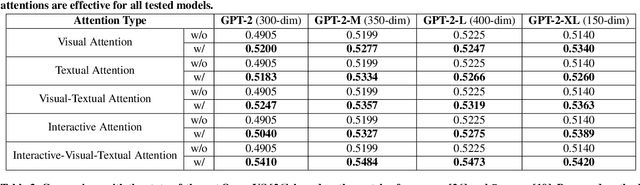
Traditional video summarization methods generate fixed video representations regardless of user interest. Therefore such methods limit users' expectations in content search and exploration scenarios. Multi-modal video summarization is one of the methods utilized to address this problem. When multi-modal video summarization is used to help video exploration, a text-based query is considered as one of the main drivers of video summary generation, as it is user-defined. Thus, encoding the text-based query and the video effectively are both important for the task of multi-modal video summarization. In this work, a new method is proposed that uses a specialized attention network and contextualized word representations to tackle this task. The proposed model consists of a contextualized video summary controller, multi-modal attention mechanisms, an interactive attention network, and a video summary generator. Based on the evaluation of the existing multi-modal video summarization benchmark, experimental results show that the proposed model is effective with the increase of +5.88% in accuracy and +4.06% increase of F1-score, compared with the state-of-the-art method.
Interpreting CNN for Low Complexity Learned Sub-pixel Motion Compensation in Video Coding
Jun 11, 2020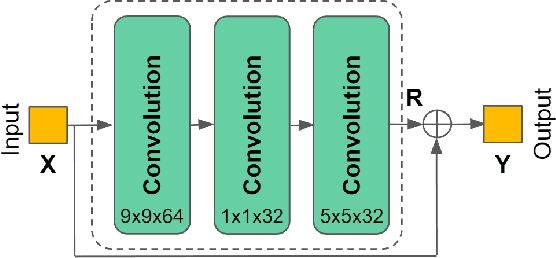
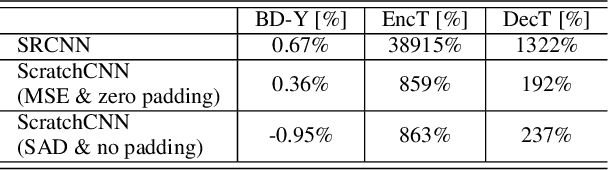
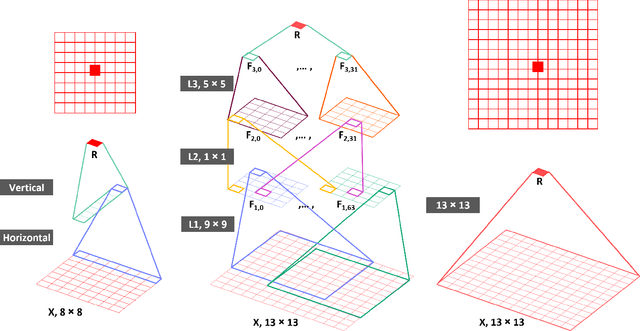
Deep learning has shown great potential in image and video compression tasks. However, it brings bit savings at the cost of significant increases in coding complexity, which limits its potential for implementation within practical applications. In this paper, a novel neural network-based tool is presented which improves the interpolation of reference samples needed for fractional precision motion compensation. Contrary to previous efforts, the proposed approach focuses on complexity reduction achieved by interpreting the interpolation filters learned by the networks. When the approach is implemented in the Versatile Video Coding (VVC) test model, up to 4.5% BD-rate saving for individual sequences is achieved compared with the baseline VVC, while the complexity of learned interpolation is significantly reduced compared to the application of full neural network.