 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentRAG: Latent Reasoning and Retrieval for Efficient Agentic RAG
May 07, 2026Single-step retrieval-augmented generation (RAG) provides an efficient way to incorporate external information for simple question answering tasks but struggles with complex questions. Agentic RAG extends this paradigm by replacing single-step retrieval with a multi-step process, in which the large language model (LLM) acts as a search agent that generates intermediate thoughts and subqueries to iteratively interact with the retrieval system. This iterative process incurs substantial latency due to the autoregressive generation of lengthy thoughts and subqueries. To address this limitation, we propose LatentRAG, a novel framework that shifts both reasoning and retrieval from discrete language space to continuous latent space. Unlike existing explicit methods that generate natural language thoughts or subqueries token-by-token, LatentRAG produces latent tokens for thoughts and subqueries directly from the hidden states in a single forward pass. We align LLMs with dense retrieval models in the latent space, enabling retrieval over latent subquery tokens and supporting end-to-end joint optimization. To improve transparency and encourage semantically meaningful latent representations, we incorporate a parallel latent decoding mechanism that translates latent tokens back into natural language. Extensive experiments on seven benchmark datasets show that LatentRAG achieves performance comparable to explicit agentic RAG methods while reducing inference latency by approximately 90%, substantially narrowing the latency gap with traditional single-step RAG.
A-MAR: Agent-based Multimodal Art Retrieval for Fine-Grained Artwork Understanding
Apr 21, 2026Understanding artworks requires multi-step reasoning over visual content and cultural, historical, and stylistic context. While recent multimodal large language models show promise in artwork explanation, they rely on implicit reasoning and internalized knowl- edge, limiting interpretability and explicit evidence grounding. We propose A-MAR, an Agent-based Multimodal Art Retrieval framework that explicitly conditions retrieval on structured reasoning plans. Given an artwork and a user query, A-MAR first decomposes the task into a structured reasoning plan that specifies the goals and evidence requirements for each step. Retrieval is then conditionedon this plan, enabling targeted evidence selection and supporting step-wise, grounded explanations. To evaluate agent-based multi- modal reasoning within the art domain, we introduce ArtCoT-QA. This diagnostic benchmark features multi-step reasoning chains for diverse art-related queries, enabling a granular analysis that extends beyond simple final answer accuracy. Experiments on SemArt and Artpedia show that A-MAR consistently outperforms static, non planned retrieval and strong MLLM baselines in final explanation quality, while evaluations on ArtCoT-QA further demonstrate its advantages in evidence grounding and multi-step reasoning ability. These results highlight the importance of reasoning-conditioned retrieval for knowledge-intensive multimodal understanding and position A-MAR as a step toward interpretable, goal-driven AI systems, with particular relevance to cultural industries. The code and data are available at: https://github.com/ShuaiWang97/A-MAR.
VL-KGE: Vision-Language Models Meet Knowledge Graph Embeddings
Mar 02, 2026Real-world multimodal knowledge graphs (MKGs) are inherently heterogeneous, modeling entities that are associated with diverse modalities. Traditional knowledge graph embedding (KGE) methods excel at learning continuous representations of entities and relations, yet they are typically designed for unimodal settings. Recent approaches extend KGE to multimodal settings but remain constrained, often processing modalities in isolation, resulting in weak cross-modal alignment, and relying on simplistic assumptions such as uniform modality availability across entities. Vision-Language Models (VLMs) offer a powerful way to align diverse modalities within a shared embedding space. We propose Vision-Language Knowledge Graph Embeddings (VL-KGE), a framework that integrates cross-modal alignment from VLMs with structured relational modeling to learn unified multimodal representations of knowledge graphs. Experiments on WN9-IMG and two novel fine art MKGs, WikiArt-MKG-v1 and WikiArt-MKG-v2, demonstrate that VL-KGE consistently improves over traditional unimodal and multimodal KGE methods in link prediction tasks. Our results highlight the value of VLMs for multimodal KGE, enabling more robust and structured reasoning over large-scale heterogeneous knowledge graphs.
* Published in Proceedings of the ACM Web Conference 2026 (WWW '26). This arXiv version includes extended supplementary material
InfoCIR: Multimedia Analysis for Composed Image Retrieval
Feb 13, 2026Composed Image Retrieval (CIR) allows users to search for images by combining a reference image with a text prompt that describes desired modifications. While vision-language models like CLIP have popularized this task by embedding multiple modalities into a joint space, developers still lack tools that reveal how these multimodal prompts interact with embedding spaces and why small wording changes can dramatically alter the results. We present InfoCIR, a visual analytics system that closes this gap by coupling retrieval, explainability, and prompt engineering in a single, interactive dashboard. InfoCIR integrates a state-of-the-art CIR back-end (SEARLE arXiv:2303.15247) with a six-panel interface that (i) lets users compose image + text queries, (ii) projects the top-k results into a low-dimensional space using Uniform Manifold Approximation and Projection (UMAP) for spatial reasoning, (iii) overlays similarity-based saliency maps and gradient-derived token-attribution bars for local explanation, and (iv) employs an LLM-powered prompt enhancer that generates counterfactual variants and visualizes how these changes affect the ranking of user-selected target images. A modular architecture built on Plotly-Dash allows new models, datasets, and attribution methods to be plugged in with minimal effort. We argue that InfoCIR helps diagnose retrieval failures, guides prompt enhancement, and accelerates insight generation during model development. All source code allowing for a reproducible demo is available at https://github.com/giannhskp/InfoCIR.
Using Large Language Models to Tackle Fundamental Challenges in Graph Learning: A Comprehensive Survey
May 24, 2025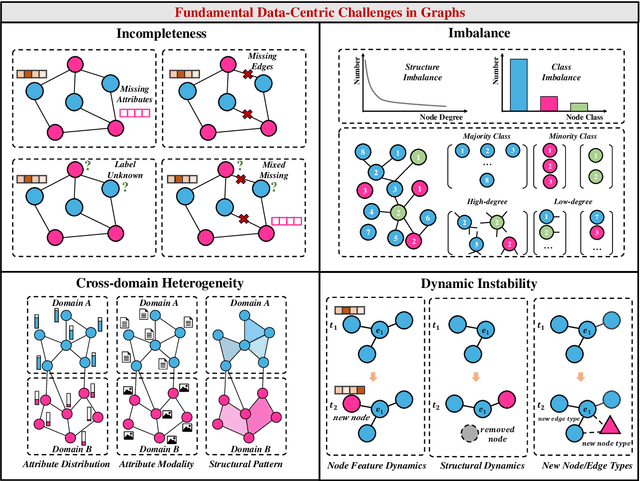
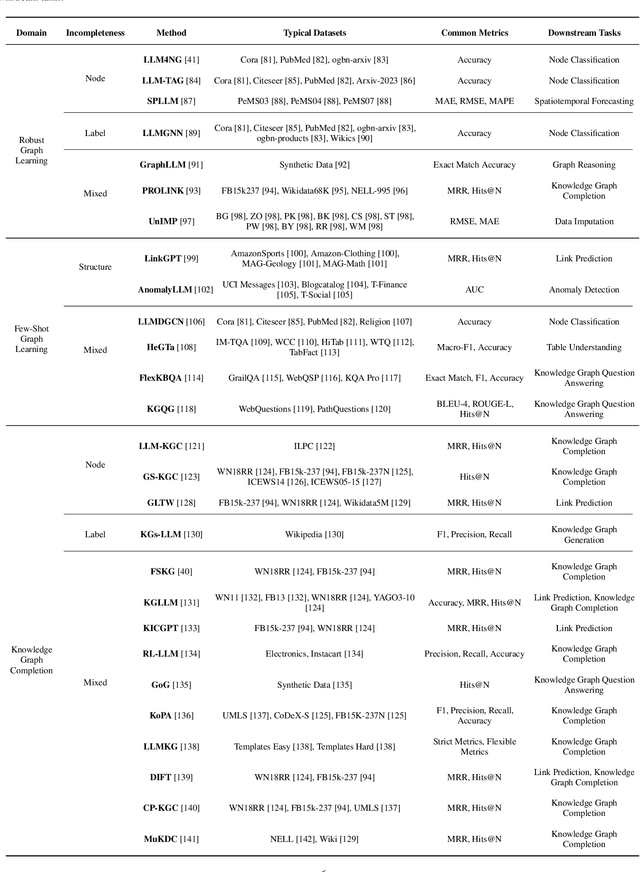
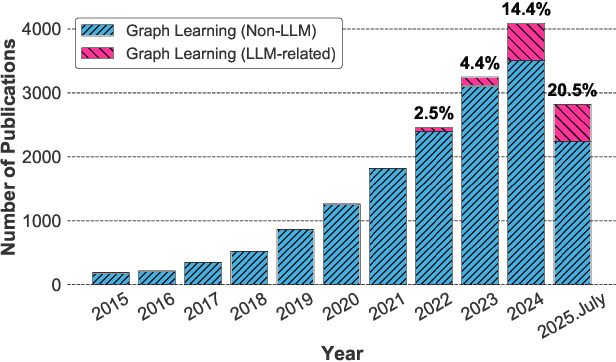
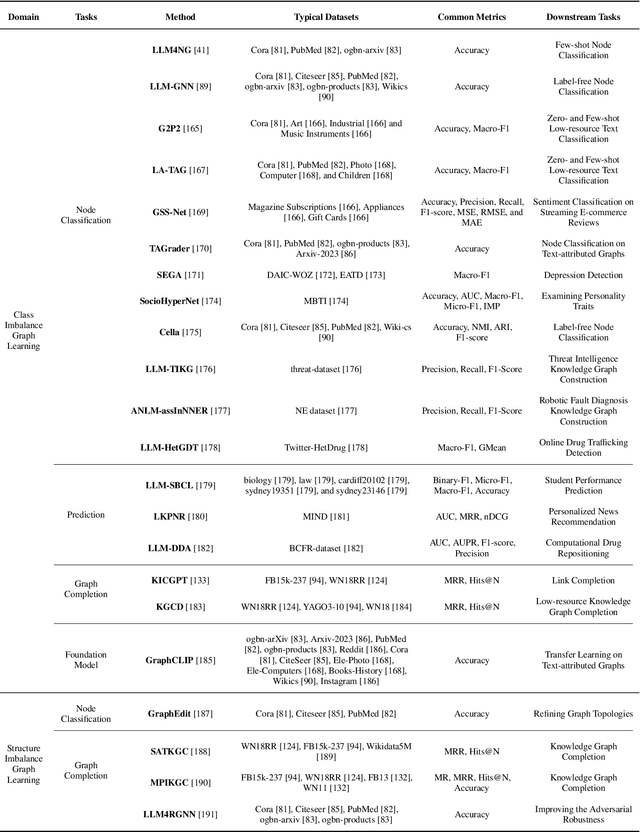
Graphs are a widely used paradigm for representing non-Euclidean data, with applications ranging from social network analysis to biomolecular prediction. Conventional graph learning approaches typically rely on fixed structural assumptions or fully observed data, limiting their effectiveness in more complex, noisy, or evolving settings. Consequently, real-world graph data often violates the assumptions of traditional graph learning methods, in particular, it leads to four fundamental challenges: (1) Incompleteness, real-world graphs have missing nodes, edges, or attributes; (2) Imbalance, the distribution of the labels of nodes or edges and their structures for real-world graphs are highly skewed; (3) Cross-domain Heterogeneity, graphs from different domains exhibit incompatible feature spaces or structural patterns; and (4) Dynamic Instability, graphs evolve over time in unpredictable ways. Recent advances in Large Language Models (LLMs) offer the potential to tackle these challenges by leveraging rich semantic reasoning and external knowledge. This survey provides a comprehensive review of how LLMs can be integrated with graph learning to address the aforementioned challenges. For each challenge, we review both traditional solutions and modern LLM-driven approaches, highlighting how LLMs contribute unique advantages. Finally, we discuss open research questions and promising future directions in this emerging interdisciplinary field. To support further exploration, we have curated a repository of recent advances on graph learning challenges: https://github.com/limengran98/Awesome-Literature-Graph-Learning-Challenges.
ArtRAG: Retrieval-Augmented Generation with Structured Context for Visual Art Understanding
May 09, 2025



Understanding visual art requires reasoning across multiple perspectives -- cultural, historical, and stylistic -- beyond mere object recognition. While recent multimodal large language models (MLLMs) perform well on general image captioning, they often fail to capture the nuanced interpretations that fine art demands. We propose ArtRAG, a novel, training-free framework that combines structured knowledge with retrieval-augmented generation (RAG) for multi-perspective artwork explanation. ArtRAG automatically constructs an Art Context Knowledge Graph (ACKG) from domain-specific textual sources, organizing entities such as artists, movements, themes, and historical events into a rich, interpretable graph. At inference time, a multi-granular structured retriever selects semantically and topologically relevant subgraphs to guide generation. This enables MLLMs to produce contextually grounded, culturally informed art descriptions. Experiments on the SemArt and Artpedia datasets show that ArtRAG outperforms several heavily trained baselines. Human evaluations further confirm that ArtRAG generates coherent, insightful, and culturally enriched interpretations.
A Multimedia Analytics Model for the Foundation Model Era
Apr 10, 2025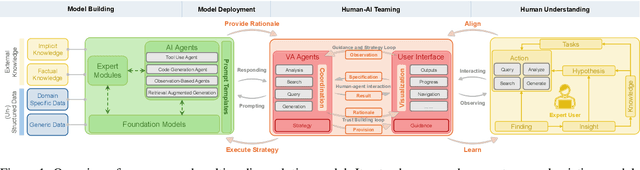
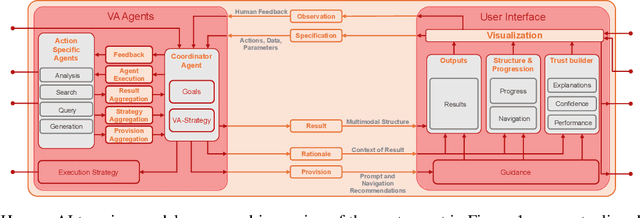
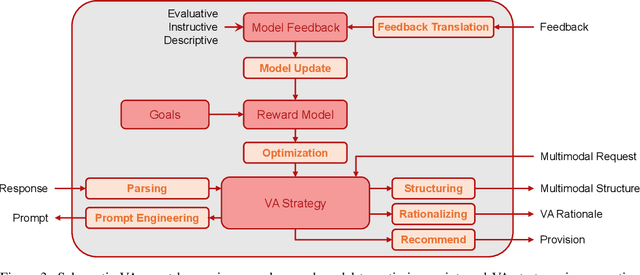
The rapid advances in Foundation Models and agentic Artificial Intelligence are transforming multimedia analytics by enabling richer, more sophisticated interactions between humans and analytical systems. Existing conceptual models for visual and multimedia analytics, however, do not adequately capture the complexity introduced by these powerful AI paradigms. To bridge this gap, we propose a comprehensive multimedia analytics model specifically designed for the foundation model era. Building upon established frameworks from visual analytics, multimedia analytics, knowledge generation, analytic task definition, mixed-initiative guidance, and human-in-the-loop reinforcement learning, our model emphasizes integrated human-AI teaming based on visual analytics agents from both technical and conceptual perspectives. Central to the model is a seamless, yet explicitly separable, interaction channel between expert users and semi-autonomous analytical processes, ensuring continuous alignment between user intent and AI behavior. The model addresses practical challenges in sensitive domains such as intelligence analysis, investigative journalism, and other fields handling complex, high-stakes data. We illustrate through detailed case studies how our model facilitates deeper understanding and targeted improvement of multimedia analytics solutions. By explicitly capturing how expert users can optimally interact with and guide AI-powered multimedia analytics systems, our conceptual framework sets a clear direction for system design, comparison, and future research.
TULIP: Token-length Upgraded CLIP
Oct 13, 2024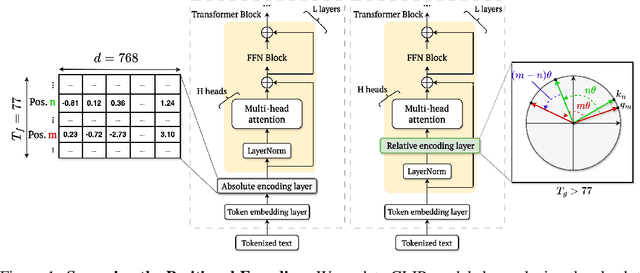
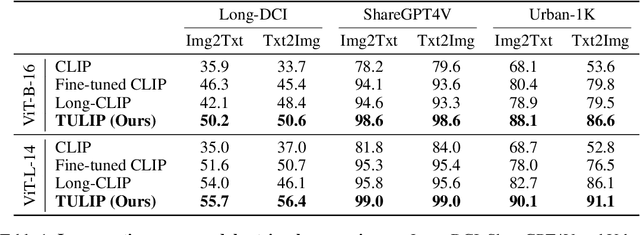
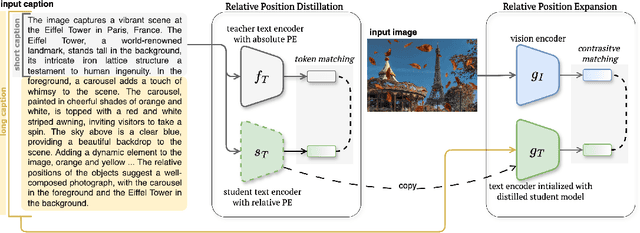
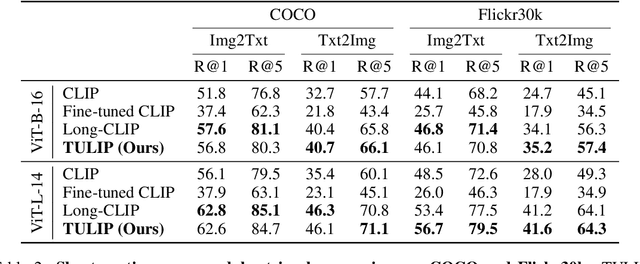
We address the challenge of representing long captions in vision-language models, such as CLIP. By design these models are limited by fixed, absolute positional encodings, restricting inputs to a maximum of 77 tokens and hindering performance on tasks requiring longer descriptions. Although recent work has attempted to overcome this limit, their proposed approaches struggle to model token relationships over longer distances and simply extend to a fixed new token length. Instead, we propose a generalizable method, named TULIP, able to upgrade the token length to any length for CLIP-like models. We do so by improving the architecture with relative position encodings, followed by a training procedure that (i) distills the original CLIP text encoder into an encoder with relative position encodings and (ii) enhances the model for aligning longer captions with images. By effectively encoding captions longer than the default 77 tokens, our model outperforms baselines on cross-modal tasks such as retrieval and text-to-image generation.
Set2Seq Transformer: Learning Permutation Aware Set Representations of Artistic Sequences
Aug 06, 2024
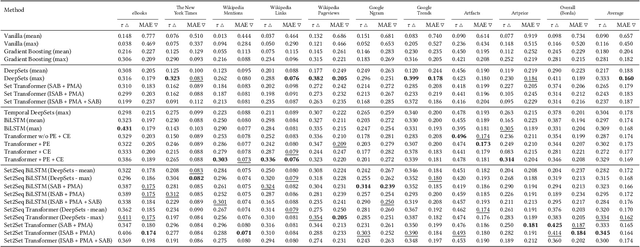
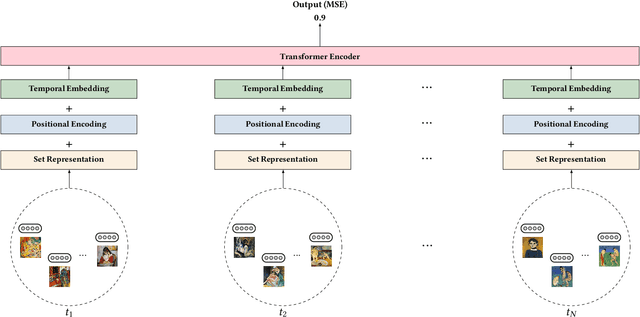
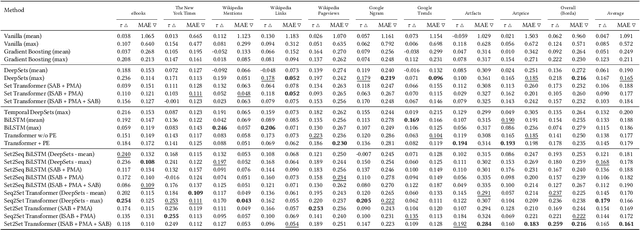
We propose Set2Seq Transformer, a novel sequential multiple instance architecture, that learns to rank permutation aware set representations of sequences. First, we illustrate that learning temporal position-aware representations of discrete timesteps can greatly improve static visual multiple instance learning methods that do not regard temporality and concentrate almost exclusively on visual content analysis. We further demonstrate the significant advantages of end-to-end sequential multiple instance learning, integrating visual content and temporal information in a multimodal manner. As application we focus on fine art analysis related tasks. To that end, we show that our Set2Seq Transformer can leverage visual set and temporal position-aware representations for modelling visual artists' oeuvres for predicting artistic success. Finally, through extensive quantitative and qualitative evaluation using a novel dataset, WikiArt-Seq2Rank, and a visual learning-to-rank downstream task, we show that our Set2Seq Transformer captures essential temporal information improving the performance of strong static and sequential multiple instance learning methods for predicting artistic success.
Co-Representation Neural Hypergraph Diffusion for Edge-Dependent Node Classification
May 23, 2024



Hypergraphs are widely employed to represent complex higher-order relationships in real-world applications. Most hypergraph learning research focuses on node- or edge-level tasks. A practically relevant but more challenging task, edge-dependent node classification (ENC), is only recently proposed. In ENC, a node can have different labels across different hyperedges, which requires the modeling of node-hyperedge pairs instead of single nodes or hyperedges. Existing solutions for this task are based on message passing and model within-edge and within-node interactions as multi-input single-output functions. This brings three limitations: (1) non-adaptive representation size, (2) node/edge agnostic messages, and (3) insufficient interactions among nodes or hyperedges. To tackle these limitations, we develop CoNHD, a new solution based on hypergraph diffusion. Specifically, we first extend hypergraph diffusion using node-hyperedge co-representations. This extension explicitly models both within-edge and within-node interactions as multi-input multi-output functions using two equivariant diffusion operators. To avoid handcrafted regularization functions, we propose a neural implementation for the co-representation hypergraph diffusion process. Extensive experiments demonstrate the effectiveness and efficiency of the proposed CoNHD model.