 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtifacts of Idiosyncracy in Global Street View Data
May 16, 2025Street view data is increasingly being used in computer vision applications in recent years. Machine learning datasets are collected for these applications using simple sampling techniques. These datasets are assumed to be a systematic representation of cities, especially when densely sampled. Prior works however, show that there are clear gaps in coverage, with certain cities or regions being covered poorly or not at all. Here we demonstrate that a cities' idiosyncracies, such as city layout, may lead to biases in street view data for 28 cities across the globe, even when they are densely covered. We quantitatively uncover biases in the distribution of coverage of street view data and propose a method for evaluation of such distributions to get better insight in idiosyncracies in a cities' coverage. In addition, we perform a case study of Amsterdam with semi-structured interviews, showing how idiosyncracies of the collection process impact representation of cities and regions and allowing us to address biases at their source.
Context-Infused Visual Grounding for Art
Oct 16, 2024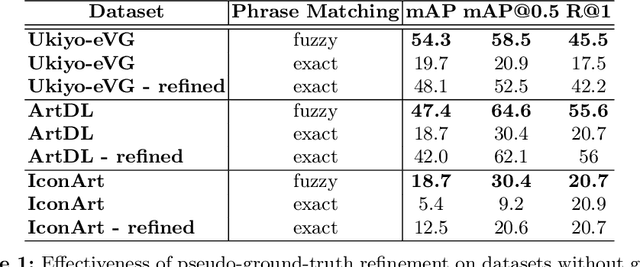

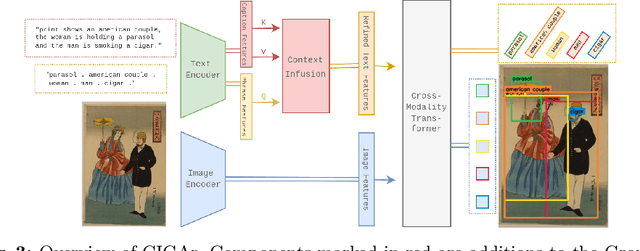
Many artwork collections contain textual attributes that provide rich and contextualised descriptions of artworks. Visual grounding offers the potential for localising subjects within these descriptions on images, however, existing approaches are trained on natural images and generalise poorly to art. In this paper, we present CIGAr (Context-Infused GroundingDINO for Art), a visual grounding approach which utilises the artwork descriptions during training as context, thereby enabling visual grounding on art. In addition, we present a new dataset, Ukiyo-eVG, with manually annotated phrase-grounding annotations, and we set a new state-of-the-art for object detection on two artwork datasets.
Stylistic Multi-Task Analysis of Ukiyo-e Woodblock Prints
Oct 16, 2024



In this work we present a large-scale dataset of \textit{Ukiyo-e} woodblock prints. Unlike previous works and datasets in the artistic domain that primarily focus on western art, this paper explores this pre-modern Japanese art form with the aim of broadening the scope for stylistic analysis and to provide a benchmark to evaluate a variety of art focused Computer Vision approaches. Our dataset consists of over $175.000$ prints with corresponding metadata (\eg artist, era, and creation date) from the 17th century to present day. By approaching stylistic analysis as a Multi-Task problem we aim to more efficiently utilize the available metadata, and learn more general representations of style. We show results for well-known baselines and state-of-the-art multi-task learning frameworks to enable future comparison, and to encourage stylistic analysis on this artistic domain.
TULIP: Token-length Upgraded CLIP
Oct 13, 2024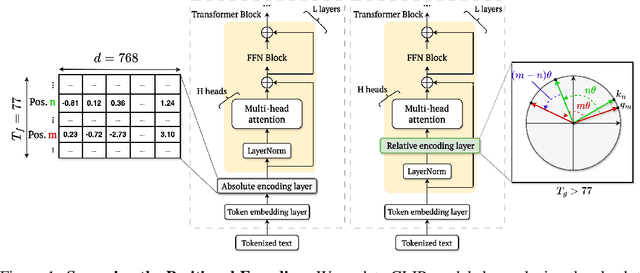
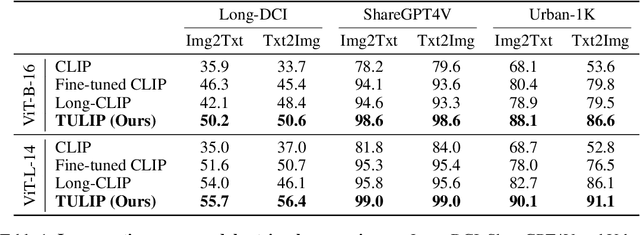
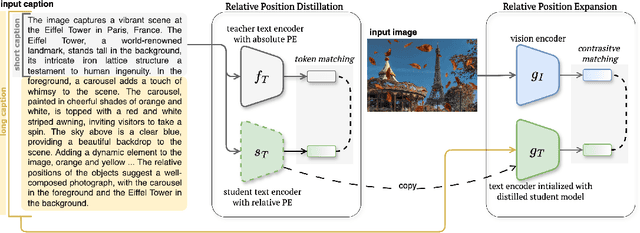
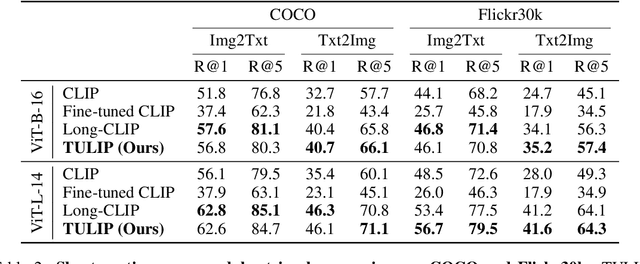
We address the challenge of representing long captions in vision-language models, such as CLIP. By design these models are limited by fixed, absolute positional encodings, restricting inputs to a maximum of 77 tokens and hindering performance on tasks requiring longer descriptions. Although recent work has attempted to overcome this limit, their proposed approaches struggle to model token relationships over longer distances and simply extend to a fixed new token length. Instead, we propose a generalizable method, named TULIP, able to upgrade the token length to any length for CLIP-like models. We do so by improving the architecture with relative position encodings, followed by a training procedure that (i) distills the original CLIP text encoder into an encoder with relative position encodings and (ii) enhances the model for aligning longer captions with images. By effectively encoding captions longer than the default 77 tokens, our model outperforms baselines on cross-modal tasks such as retrieval and text-to-image generation.
Find the Cliffhanger: Multi-Modal Trailerness in Soap Operas
Jan 29, 2024Creating a trailer requires carefully picking out and piecing together brief enticing moments out of a longer video, making it a challenging and time-consuming task. This requires selecting moments based on both visual and dialogue information. We introduce a multi-modal method for predicting the trailerness to assist editors in selecting trailer-worthy moments from long-form videos. We present results on a newly introduced soap opera dataset, demonstrating that predicting trailerness is a challenging task that benefits from multi-modal information. Code is available at https://github.com/carlobretti/cliffhanger
Blind Dates: Examining the Expression of Temporality in Historical Photographs
Oct 10, 2023
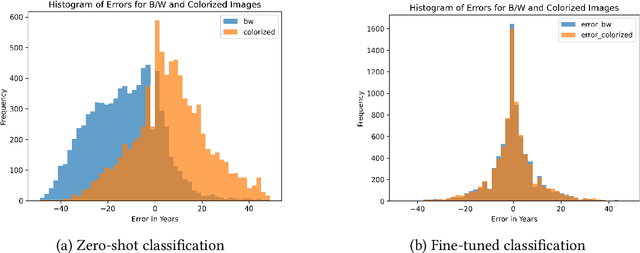

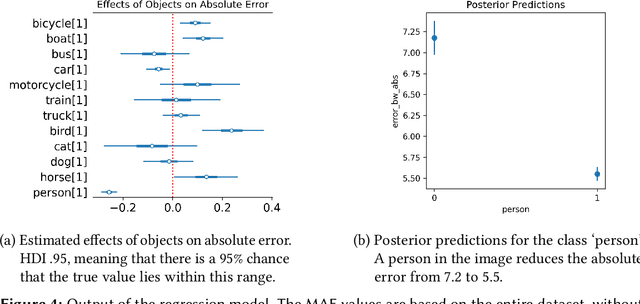
This paper explores the capacity of computer vision models to discern temporal information in visual content, focusing specifically on historical photographs. We investigate the dating of images using OpenCLIP, an open-source implementation of CLIP, a multi-modal language and vision model. Our experiment consists of three steps: zero-shot classification, fine-tuning, and analysis of visual content. We use the \textit{De Boer Scene Detection} dataset, containing 39,866 gray-scale historical press photographs from 1950 to 1999. The results show that zero-shot classification is relatively ineffective for image dating, with a bias towards predicting dates in the past. Fine-tuning OpenCLIP with a logistic classifier improves performance and eliminates the bias. Additionally, our analysis reveals that images featuring buses, cars, cats, dogs, and people are more accurately dated, suggesting the presence of temporal markers. The study highlights the potential of machine learning models like OpenCLIP in dating images and emphasizes the importance of fine-tuning for accurate temporal analysis. Future research should explore the application of these findings to color photographs and diverse datasets.
Prototype-based Dataset Comparison
Sep 05, 2023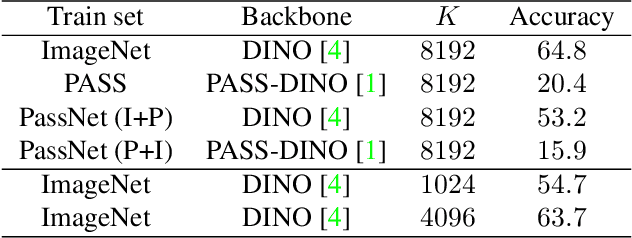



Dataset summarisation is a fruitful approach to dataset inspection. However, when applied to a single dataset the discovery of visual concepts is restricted to those most prominent. We argue that a comparative approach can expand upon this paradigm to enable richer forms of dataset inspection that go beyond the most prominent concepts. To enable dataset comparison we present a module that learns concept-level prototypes across datasets. We leverage self-supervised learning to discover these prototypes without supervision, and we demonstrate the benefits of our approach in two case-studies. Our findings show that dataset comparison extends dataset inspection and we hope to encourage more works in this direction. Code and usage instructions available at https://github.com/Nanne/ProtoSim
Hierarchical Explanations for Video Action Recognition
Jan 04, 2023



We propose Hierarchical ProtoPNet: an interpretable network that explains its reasoning process by considering the hierarchical relationship between classes. Different from previous methods that explain their reasoning process by dissecting the input image and finding the prototypical parts responsible for the classification, we propose to explain the reasoning process for video action classification by dissecting the input video frames on multiple levels of the class hierarchy. The explanations leverage the hierarchy to deal with uncertainty, akin to human reasoning: When we observe water and human activity, but no definitive action it can be recognized as the water sports parent class. Only after observing a person swimming can we definitively refine it to the swimming action. Experiments on ActivityNet and UCF-101 show performance improvements while providing multi-level explanations.
An Analytics of Culture: Modeling Subjectivity, Scalability, Contextuality, and Temporality
Nov 14, 2022There is a bidirectional relationship between culture and AI; AI models are increasingly used to analyse culture, thereby shaping our understanding of culture. On the other hand, the models are trained on collections of cultural artifacts thereby implicitly, and not always correctly, encoding expressions of culture. This creates a tension that both limits the use of AI for analysing culture and leads to problems in AI with respect to cultural complex issues such as bias. One approach to overcome this tension is to more extensively take into account the intricacies and complexities of culture. We structure our discussion using four concepts that guide humanistic inquiry into culture: subjectivity, scalability, contextuality, and temporality. We focus on these concepts because they have not yet been sufficiently represented in AI research. We believe that possible implementations of these aspects into AI research leads to AI that better captures the complexities of culture. In what follows, we briefly describe these four concepts and their absence in AI research. For each concept, we define possible research challenges.
Hyperbolic Image Segmentation
Mar 11, 2022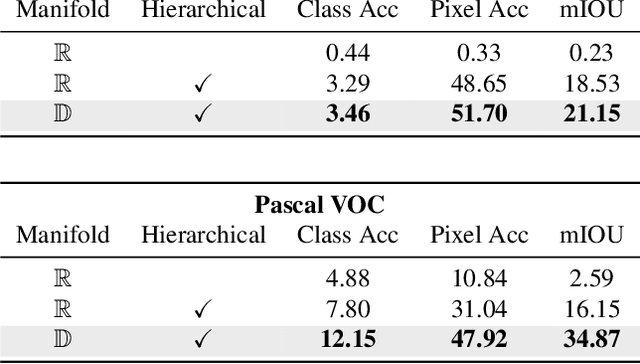
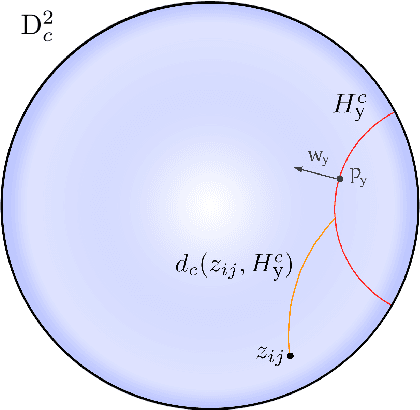
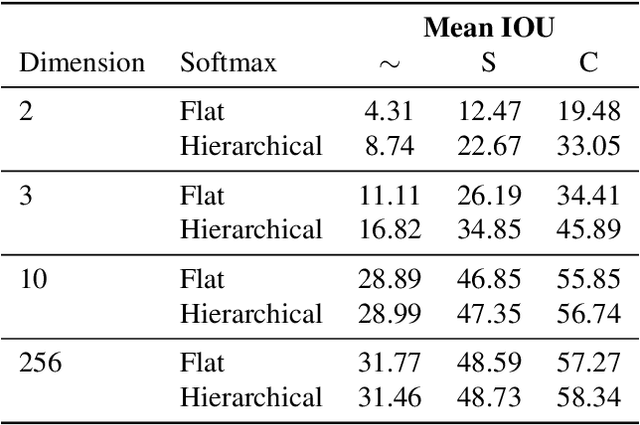
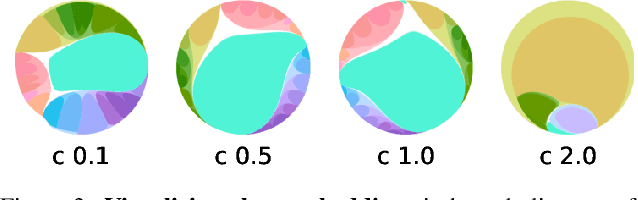
For image segmentation, the current standard is to perform pixel-level optimization and inference in Euclidean output embedding spaces through linear hyperplanes. In this work, we show that hyperbolic manifolds provide a valuable alternative for image segmentation and propose a tractable formulation of hierarchical pixel-level classification in hyperbolic space. Hyperbolic Image Segmentation opens up new possibilities and practical benefits for segmentation, such as uncertainty estimation and boundary information for free, zero-label generalization, and increased performance in low-dimensional output embeddings.