 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Geometrically Grounded Lorentz Neural Networks
Jan 29, 2026Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
Looking Beyond the Obvious: A Survey on Abstract Concept Recognition for Video Understanding
Aug 28, 2025The automatic understanding of video content is advancing rapidly. Empowered by deeper neural networks and large datasets, machines are increasingly capable of understanding what is concretely visible in video frames, whether it be objects, actions, events, or scenes. In comparison, humans retain a unique ability to also look beyond concrete entities and recognize abstract concepts like justice, freedom, and togetherness. Abstract concept recognition forms a crucial open challenge in video understanding, where reasoning on multiple semantic levels based on contextual information is key. In this paper, we argue that the recent advances in foundation models make for an ideal setting to address abstract concept understanding in videos. Automated understanding of high-level abstract concepts is imperative as it enables models to be more aligned with human reasoning and values. In this survey, we study different tasks and datasets used to understand abstract concepts in video content. We observe that, periodically and over a long period, researchers have attempted to solve these tasks, making the best use of the tools available at their disposal. We advocate that drawing on decades of community experience will help us shed light on this important open grand challenge and avoid ``re-inventing the wheel'' as we start revisiting it in the era of multi-modal foundation models.
Continual Hyperbolic Learning of Instances and Classes
Jun 12, 2025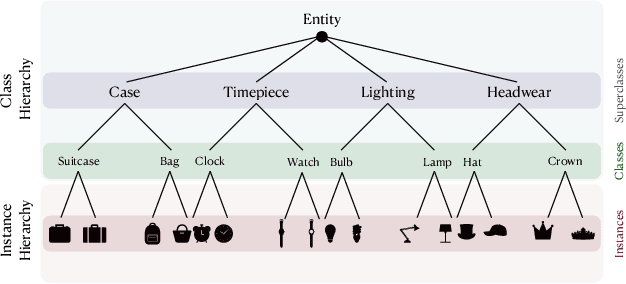
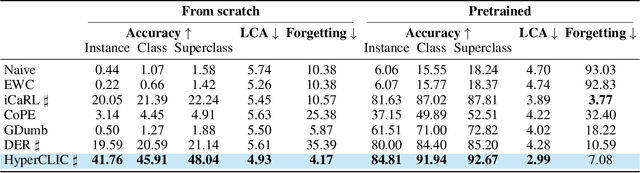
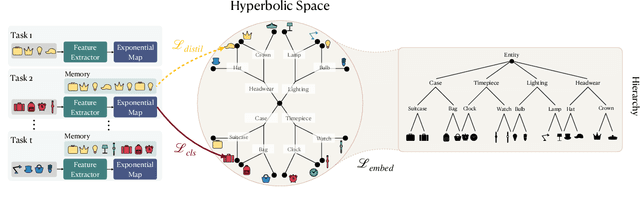
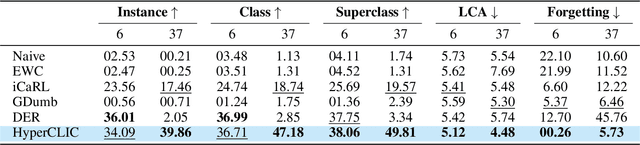
Continual learning has traditionally focused on classifying either instances or classes, but real-world applications, such as robotics and self-driving cars, require models to handle both simultaneously. To mirror real-life scenarios, we introduce the task of continual learning of instances and classes, at the same time. This task challenges models to adapt to multiple levels of granularity over time, which requires balancing fine-grained instance recognition with coarse-grained class generalization. In this paper, we identify that classes and instances naturally form a hierarchical structure. To model these hierarchical relationships, we propose HyperCLIC, a continual learning algorithm that leverages hyperbolic space, which is uniquely suited for hierarchical data due to its ability to represent tree-like structures with low distortion and compact embeddings. Our framework incorporates hyperbolic classification and distillation objectives, enabling the continual embedding of hierarchical relations. To evaluate performance across multiple granularities, we introduce continual hierarchical metrics. We validate our approach on EgoObjects, the only dataset that captures the complexity of hierarchical object recognition in dynamic real-world environments. Empirical results show that HyperCLIC operates effectively at multiple granularities with improved hierarchical generalization.
Balanced Hyperbolic Embeddings Are Natural Out-of-Distribution Detectors
Jun 11, 2025Out-of-distribution recognition forms an important and well-studied problem in deep learning, with the goal to filter out samples that do not belong to the distribution on which a network has been trained. The conclusion of this paper is simple: a good hierarchical hyperbolic embedding is preferred for discriminating in- and out-of-distribution samples. We introduce Balanced Hyperbolic Learning. We outline a hyperbolic class embedding algorithm that jointly optimizes for hierarchical distortion and balancing between shallow and wide subhierarchies. We then use the class embeddings as hyperbolic prototypes for classification on in-distribution data. We outline how to generalize existing out-of-distribution scoring functions to operate with hyperbolic prototypes. Empirical evaluations across 13 datasets and 13 scoring functions show that our hyperbolic embeddings outperform existing out-of-distribution approaches when trained on the same data with the same backbones. We also show that our hyperbolic embeddings outperform other hyperbolic approaches, beat state-of-the-art contrastive methods, and natively enable hierarchical out-of-distribution generalization.
Hyperbolic Safety-Aware Vision-Language Models
Mar 15, 2025



Addressing the retrieval of unsafe content from vision-language models such as CLIP is an important step towards real-world integration. Current efforts have relied on unlearning techniques that try to erase the model's knowledge of unsafe concepts. While effective in reducing unwanted outputs, unlearning limits the model's capacity to discern between safe and unsafe content. In this work, we introduce a novel approach that shifts from unlearning to an awareness paradigm by leveraging the inherent hierarchical properties of the hyperbolic space. We propose to encode safe and unsafe content as an entailment hierarchy, where both are placed in different regions of hyperbolic space. Our HySAC, Hyperbolic Safety-Aware CLIP, employs entailment loss functions to model the hierarchical and asymmetrical relations between safe and unsafe image-text pairs. This modelling, ineffective in standard vision-language models due to their reliance on Euclidean embeddings, endows the model with awareness of unsafe content, enabling it to serve as both a multimodal unsafe classifier and a flexible content retriever, with the option to dynamically redirect unsafe queries toward safer alternatives or retain the original output. Extensive experiments show that our approach not only enhances safety recognition but also establishes a more adaptable and interpretable framework for content moderation in vision-language models. Our source code is available at https://github.com/aimagelab/HySAC.
Low-distortion and GPU-compatible Tree Embeddings in Hyperbolic Space
Feb 24, 2025Embedding tree-like data, from hierarchies to ontologies and taxonomies, forms a well-studied problem for representing knowledge across many domains. Hyperbolic geometry provides a natural solution for embedding trees, with vastly superior performance over Euclidean embeddings. Recent literature has shown that hyperbolic tree embeddings can even be placed on top of neural networks for hierarchical knowledge integration in deep learning settings. For all applications, a faithful embedding of trees is needed, with combinatorial constructions emerging as the most effective direction. This paper identifies and solves two key limitations of existing works. First, the combinatorial construction hinges on finding highly separated points on a hypersphere, a notoriously difficult problem. Current approaches achieve poor separation, degrading the quality of the corresponding hyperbolic embedding. We propose highly separated Delaunay tree embeddings (HS-DTE), which integrates angular separation in a generalized formulation of Delaunay embeddings, leading to lower embedding distortion. Second, low-distortion requires additional precision. The current approach for increasing precision is to use multiple precision arithmetic, which renders the embeddings useless on GPUs in deep learning settings. We reformulate the combinatorial construction using floating point expansion arithmetic, leading to superior embedding quality while retaining utility on accelerated hardware.
Adversarial Attacks on Hyperbolic Networks
Dec 02, 2024



As hyperbolic deep learning grows in popularity, so does the need for adversarial robustness in the context of such a non-Euclidean geometry. To this end, this paper proposes hyperbolic alternatives to the commonly used FGM and PGD adversarial attacks. Through interpretable synthetic benchmarks and experiments on existing datasets, we show how the existing and newly proposed attacks differ. Moreover, we investigate the differences in adversarial robustness between Euclidean and fully hyperbolic networks. We find that these networks suffer from different types of vulnerabilities and that the newly proposed hyperbolic attacks cannot address these differences. Therefore, we conclude that the shifts in adversarial robustness are due to the models learning distinct patterns resulting from their different geometries.
Maximally Separated Active Learning
Nov 26, 2024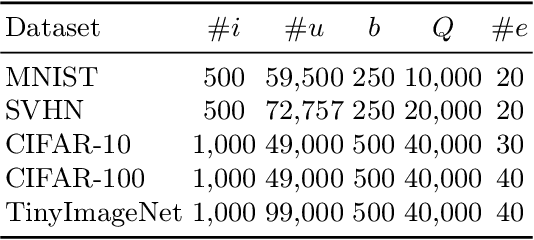
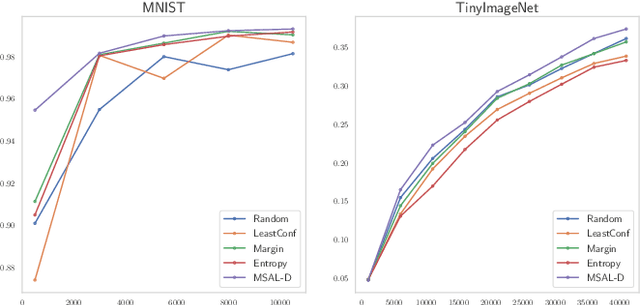
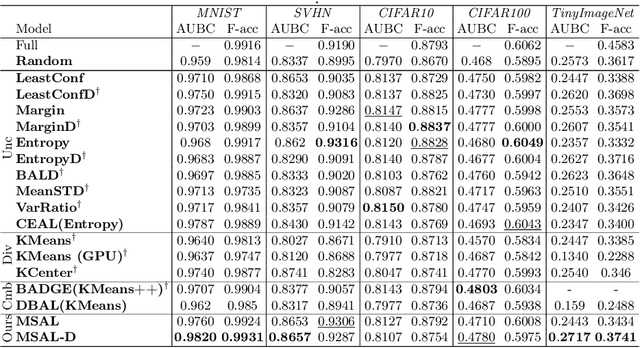
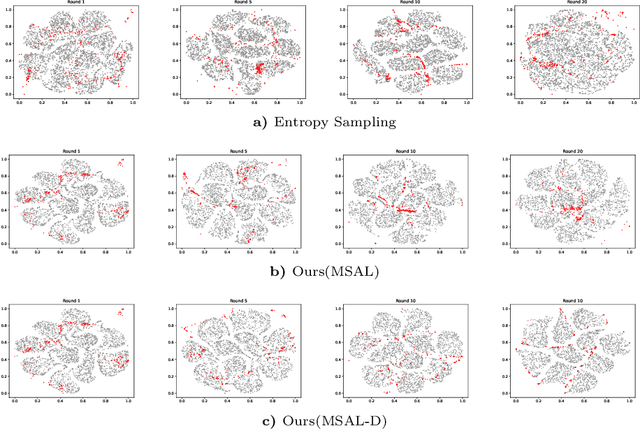
Active Learning aims to optimize performance while minimizing annotation costs by selecting the most informative samples from an unlabelled pool. Traditional uncertainty sampling often leads to sampling bias by choosing similar uncertain samples. We propose an active learning method that utilizes fixed equiangular hyperspherical points as class prototypes, ensuring consistent inter-class separation and robust feature representations. Our approach introduces Maximally Separated Active Learning (MSAL) for uncertainty sampling and a combined strategy (MSAL-D) for incorporating diversity. This method eliminates the need for costly clustering steps, while maintaining diversity through hyperspherical uniformity. We demonstrate strong performance over existing active learning techniques across five benchmark datasets, highlighting the method's effectiveness and integration ease. The code is available on GitHub.
Compositional Entailment Learning for Hyperbolic Vision-Language Models
Oct 09, 2024



Image-text representation learning forms a cornerstone in vision-language models, where pairs of images and textual descriptions are contrastively aligned in a shared embedding space. Since visual and textual concepts are naturally hierarchical, recent work has shown that hyperbolic space can serve as a high-potential manifold to learn vision-language representation with strong downstream performance. In this work, for the first time we show how to fully leverage the innate hierarchical nature of hyperbolic embeddings by looking beyond individual image-text pairs. We propose Compositional Entailment Learning for hyperbolic vision-language models. The idea is that an image is not only described by a sentence but is itself a composition of multiple object boxes, each with their own textual description. Such information can be obtained freely by extracting nouns from sentences and using openly available localized grounding models. We show how to hierarchically organize images, image boxes, and their textual descriptions through contrastive and entailment-based objectives. Empirical evaluation on a hyperbolic vision-language model trained with millions of image-text pairs shows that the proposed compositional learning approach outperforms conventional Euclidean CLIP learning, as well as recent hyperbolic alternatives, with better zero-shot and retrieval generalization and clearly stronger hierarchical performance.
Hyp2Nav: Hyperbolic Planning and Curiosity for Crowd Navigation
Jul 19, 2024



Autonomous robots are increasingly becoming a strong fixture in social environments. Effective crowd navigation requires not only safe yet fast planning, but should also enable interpretability and computational efficiency for working in real-time on embedded devices. In this work, we advocate for hyperbolic learning to enable crowd navigation and we introduce Hyp2Nav. Different from conventional reinforcement learning-based crowd navigation methods, Hyp2Nav leverages the intrinsic properties of hyperbolic geometry to better encode the hierarchical nature of decision-making processes in navigation tasks. We propose a hyperbolic policy model and a hyperbolic curiosity module that results in effective social navigation, best success rates, and returns across multiple simulation settings, using up to 6 times fewer parameters than competitor state-of-the-art models. With our approach, it becomes even possible to obtain policies that work in 2-dimensional embedding spaces, opening up new possibilities for low-resource crowd navigation and model interpretability. Insightfully, the internal hyperbolic representation of Hyp2Nav correlates with how much attention the robot pays to the surrounding crowds, e.g. due to multiple people occluding its pathway or to a few of them showing colliding plans, rather than to its own planned route.