 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Geometrically Grounded Lorentz Neural Networks
Jan 29, 2026Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
Balanced Hyperbolic Embeddings Are Natural Out-of-Distribution Detectors
Jun 11, 2025Out-of-distribution recognition forms an important and well-studied problem in deep learning, with the goal to filter out samples that do not belong to the distribution on which a network has been trained. The conclusion of this paper is simple: a good hierarchical hyperbolic embedding is preferred for discriminating in- and out-of-distribution samples. We introduce Balanced Hyperbolic Learning. We outline a hyperbolic class embedding algorithm that jointly optimizes for hierarchical distortion and balancing between shallow and wide subhierarchies. We then use the class embeddings as hyperbolic prototypes for classification on in-distribution data. We outline how to generalize existing out-of-distribution scoring functions to operate with hyperbolic prototypes. Empirical evaluations across 13 datasets and 13 scoring functions show that our hyperbolic embeddings outperform existing out-of-distribution approaches when trained on the same data with the same backbones. We also show that our hyperbolic embeddings outperform other hyperbolic approaches, beat state-of-the-art contrastive methods, and natively enable hierarchical out-of-distribution generalization.
Low-distortion and GPU-compatible Tree Embeddings in Hyperbolic Space
Feb 24, 2025Embedding tree-like data, from hierarchies to ontologies and taxonomies, forms a well-studied problem for representing knowledge across many domains. Hyperbolic geometry provides a natural solution for embedding trees, with vastly superior performance over Euclidean embeddings. Recent literature has shown that hyperbolic tree embeddings can even be placed on top of neural networks for hierarchical knowledge integration in deep learning settings. For all applications, a faithful embedding of trees is needed, with combinatorial constructions emerging as the most effective direction. This paper identifies and solves two key limitations of existing works. First, the combinatorial construction hinges on finding highly separated points on a hypersphere, a notoriously difficult problem. Current approaches achieve poor separation, degrading the quality of the corresponding hyperbolic embedding. We propose highly separated Delaunay tree embeddings (HS-DTE), which integrates angular separation in a generalized formulation of Delaunay embeddings, leading to lower embedding distortion. Second, low-distortion requires additional precision. The current approach for increasing precision is to use multiple precision arithmetic, which renders the embeddings useless on GPUs in deep learning settings. We reformulate the combinatorial construction using floating point expansion arithmetic, leading to superior embedding quality while retaining utility on accelerated hardware.
Adversarial Attacks on Hyperbolic Networks
Dec 02, 2024



As hyperbolic deep learning grows in popularity, so does the need for adversarial robustness in the context of such a non-Euclidean geometry. To this end, this paper proposes hyperbolic alternatives to the commonly used FGM and PGD adversarial attacks. Through interpretable synthetic benchmarks and experiments on existing datasets, we show how the existing and newly proposed attacks differ. Moreover, we investigate the differences in adversarial robustness between Euclidean and fully hyperbolic networks. We find that these networks suffer from different types of vulnerabilities and that the newly proposed hyperbolic attacks cannot address these differences. Therefore, we conclude that the shifts in adversarial robustness are due to the models learning distinct patterns resulting from their different geometries.
Compositional Entailment Learning for Hyperbolic Vision-Language Models
Oct 09, 2024



Image-text representation learning forms a cornerstone in vision-language models, where pairs of images and textual descriptions are contrastively aligned in a shared embedding space. Since visual and textual concepts are naturally hierarchical, recent work has shown that hyperbolic space can serve as a high-potential manifold to learn vision-language representation with strong downstream performance. In this work, for the first time we show how to fully leverage the innate hierarchical nature of hyperbolic embeddings by looking beyond individual image-text pairs. We propose Compositional Entailment Learning for hyperbolic vision-language models. The idea is that an image is not only described by a sentence but is itself a composition of multiple object boxes, each with their own textual description. Such information can be obtained freely by extracting nouns from sentences and using openly available localized grounding models. We show how to hierarchically organize images, image boxes, and their textual descriptions through contrastive and entailment-based objectives. Empirical evaluation on a hyperbolic vision-language model trained with millions of image-text pairs shows that the proposed compositional learning approach outperforms conventional Euclidean CLIP learning, as well as recent hyperbolic alternatives, with better zero-shot and retrieval generalization and clearly stronger hierarchical performance.
HypLL: The Hyperbolic Learning Library
Jun 09, 2023Deep learning in hyperbolic space is quickly gaining traction in the fields of machine learning, multimedia, and computer vision. Deep networks commonly operate in Euclidean space, implicitly assuming that data lies on regular grids. Recent advances have shown that hyperbolic geometry provides a viable alternative foundation for deep learning, especially when data is hierarchical in nature and when working with few embedding dimensions. Currently however, no accessible open-source library exists to build hyperbolic network modules akin to well-known deep learning libraries. We present HypLL, the Hyperbolic Learning Library to bring the progress on hyperbolic deep learning together. HypLL is built on top of PyTorch, with an emphasis in its design for easy-of-use, in order to attract a broad audience towards this new and open-ended research direction. The code is available at: https://github.com/maxvanspengler/hyperbolic_learning_library. The compressed archive is available at: https://doi.org/10.21942/uva.23385506.v4
Poincaré ResNet
Mar 24, 2023This paper introduces an end-to-end residual network that operates entirely on the Poincar\'e ball model of hyperbolic space. Hyperbolic learning has recently shown great potential for visual understanding, but is currently only performed in the penultimate layer(s) of deep networks. All visual representations are still learned through standard Euclidean networks. In this paper we investigate how to learn hyperbolic representations of visual data directly from the pixel-level. We propose Poincar\'e ResNet, a hyperbolic counterpart of the celebrated residual network, starting from Poincar\'e 2D convolutions up to Poincar\'e residual connections. We identify three roadblocks for training convolutional networks entirely in hyperbolic space and propose a solution for each: (i) Current hyperbolic network initializations collapse to the origin, limiting their applicability in deeper networks. We provide an identity-based initialization that preserves norms over many layers. (ii) Residual networks rely heavily on batch normalization, which comes with expensive Fr\'echet mean calculations in hyperbolic space. We introduce Poincar\'e midpoint batch normalization as a faster and equally effective alternative. (iii) Due to the many intermediate operations in Poincar\'e layers, we lastly find that the computation graphs of deep learning libraries blow up, limiting our ability to train on deep hyperbolic networks. We provide manual backward derivations of core hyperbolic operations to maintain manageable computation graphs.
Maximum Class Separation as Inductive Bias in One Matrix
Jun 17, 2022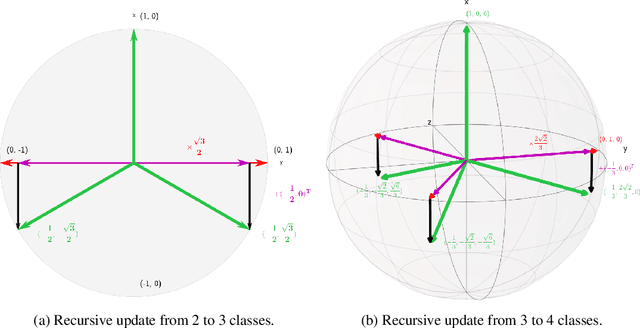
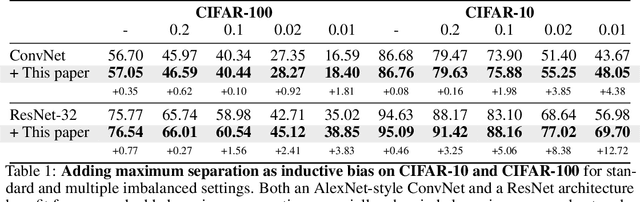
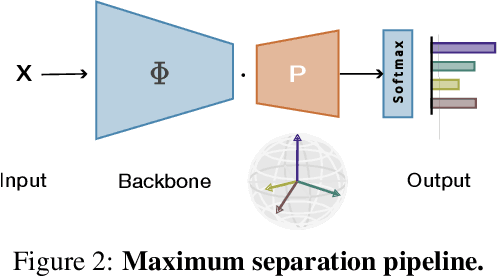
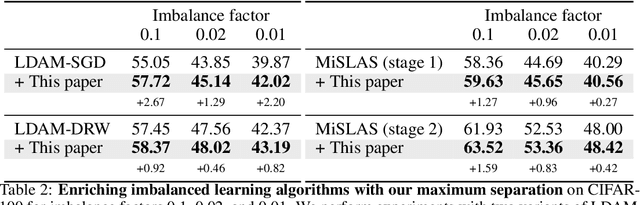
Maximizing the separation between classes constitutes a well-known inductive bias in machine learning and a pillar of many traditional algorithms. By default, deep networks are not equipped with this inductive bias and therefore many alternative solutions have been proposed through differential optimization. Current approaches tend to optimize classification and separation jointly: aligning inputs with class vectors and separating class vectors angularly. This paper proposes a simple alternative: encoding maximum separation as an inductive bias in the network by adding one fixed matrix multiplication before computing the softmax activations. The main observation behind our approach is that separation does not require optimization but can be solved in closed-form prior to training and plugged into a network. We outline a recursive approach to obtain the matrix consisting of maximally separable vectors for any number of classes, which can be added with negligible engineering effort and computational overhead. Despite its simple nature, this one matrix multiplication provides real impact. We show that our proposal directly boosts classification, long-tailed recognition, out-of-distribution detection, and open-set recognition, from CIFAR to ImageNet. We find empirically that maximum separation works best as a fixed bias; making the matrix learnable adds nothing to the performance. The closed-form implementation and code to reproduce the experiments are on github.