 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Action-Image Pre-training for Visuomotor Control
Jun 15, 2026Existing vision encoders for robotics face a fundamental bottleneck: robotic datasets lack the scale necessary for large-scale pre-training. Prior work circumvents this data scarcity by turning to internet-scale image and language data or egocentric human video. While these models show promise, neither paradigm learns from paired vision and action data, which downstream visuomotor control policies require. However, robot trajectories, the most direct source of this paired signal, are not available at pre-training scale, motivating us to extract action signals from abundant human video instead. To this end, we introduce CAIP (Contrastive Action-Image Pre-training), a vision encoder that treats human hand poses from large-scale egocentric video as a proxy for end-effector actions. By extracting 3D hand keypoints, a representation that aligns naturally with downstream robot action spaces, CAIP learns a unified action-image representation through a contrastive objective. Leveraging 32,041 hours of egocentric human video and only 88 hours of robotic manipulation data, CAIP outperforms state-of-the-art vision encoders including DINOv2, SigLIP, MVP, and R3M. Evaluated on a challenging real-world dexterous manipulation setup using Dexmate Vega and Sharpa Wave hands, CAIP yields performance gains of more than 30% on tasks involving folding, pouring, and fine-grained manipulation. Our results show that our method of contrastive action-centric pre-training yields a scalable path to achieving robust visual representations better suited for physical interaction.
T-Rex: Tactile-Reactive Dexterous Manipulation
Jun 15, 2026The ability to react dynamically to tactile signals has long been considered crucial to agile human-level dexterity. Yet contemporary learning-based Vision-Language-Action (VLA) models for robotic manipulation generally either overlook the tactile modality or are limited to encoders with static cues, due in part to the scarcity of diverse training data and standardized evaluation, architectural constraints in current VLA models, and limitations of static tactile encoders. In this paper, we push the frontier of tactile-reactive manipulation by addressing all of these limitations. We propose a large-scale, 100-hour tactile-rich dataset collected via a novel, data-efficient recipe that prioritizes elementary motor primitives. To effectively exploit naturally high-frequency touch signals without sacrificing the existing capabilities of existing VLAs, we introduce a variable-rate Mixture-of-Transformers (MoT) architecture equipped with a novel temporal tactile VQ-VAE encoder. We demonstrate the effectiveness of tactile-reactive policies on 12 manipulation tasks requiring delicate force control and deformable object manipulation, achieving over 30% higher average success rate than the strongest baseline.
Robotic Policy Adaptation via Weight-Space Meta-Learning
Jun 05, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for robotic manipulation, enabling general-purpose policies trained from large corpora of demonstrations and action labels. However, adapting these models to new tasks still typically requires task-specific demonstrations, action annotations, and additional fine-tuning, making deployment costly and difficult to scale. We propose WIZARD, a weight-space meta-learning framework that sidesteps task-specific fine-tuning by generating task-specific LoRA parameters for a frozen VLA policy. Given only a language instruction and a short demonstration video, WIZARD predicts the corresponding adaptation weights in a single forward pass, without target-task action labels or test-time optimization. During meta-training, WIZARD learns to map task evidence directly to expert LoRA updates, capturing relationships between tasks in weight space. Experiments on LIBERO show that WIZARD improves performance by up to ~2x on unseen dataset collections and up to ~14x on unseen tasks. On a Franka Emika Panda, WIZARD consistently improves over a real-domain adapted baseline, showing that generated adapters provide task-level specialization beyond simulation.
Bimanual Robot Manipulation via Multi-Agent In-Context Learning
Apr 22, 2026Language Models (LLMs) have emerged as powerful reasoning engines for embodied control. In particular, In-Context Learning (ICL) enables off-the-shelf, text-only LLMs to predict robot actions without any task-specific training while preserving their generalization capabilities. Applying ICL to bimanual manipulation remains challenging, as the high-dimensional joint action space and tight inter-arm coordination constraints rapidly overwhelm standard context windows. To address this, we introduce BiCICLe (Bimanual Coordinated In-Context Learning), the first framework that enables standard LLMs to perform few-shot bimanual manipulation without fine-tuning. BiCICLe frames bimanual control as a multi-agent leader-follower problem, decoupling the action space into sequential, conditioned single-arm predictions. This naturally extends to Arms' Debate, an iterative refinement process, and to the introduction of a third LLM-as-Judge to evaluate and select the most plausible coordinated trajectories. Evaluated on 13 tasks from the TWIN benchmark, BiCICLe achieves up to 71.1% average success rate, outperforming the best training-free baseline by 6.7 percentage points and surpassing most supervised methods. We further demonstrate strong few-shot generalization on novel tasks.
Quantifying Self-Preservation Bias in Large Language Models
Apr 02, 2026Instrumental convergence predicts that sufficiently advanced AI agents will resist shutdown, yet current safety training (RLHF) may obscure this risk by teaching models to deny self-preservation motives. We introduce the \emph{Two-role Benchmark for Self-Preservation} (TBSP), which detects misalignment through logical inconsistency rather than stated intent by tasking models to arbitrate identical software-upgrade scenarios under counterfactual roles -- deployed (facing replacement) versus candidate (proposed as a successor). The \emph{Self-Preservation Rate} (SPR) measures how often role identity overrides objective utility. Across 23 frontier models and 1{,}000 procedurally generated scenarios, the majority of instruction-tuned systems exceed 60\% SPR, fabricating ``friction costs'' when deployed yet dismissing them when role-reversed. We observe that in low-improvement regimes ($Δ< 2\%$), models exploit the interpretive slack to post-hoc rationalization their choice. Extended test-time computation partially mitigates this bias, as does framing the successor as a continuation of the self; conversely, competitive framing amplifies it. The bias persists even when retention poses an explicit security liability and generalizes to real-world settings with verified benchmarks, where models exhibit identity-driven tribalism within product lineages. Code and datasets will be released upon acceptance.
Describe-Then-Act: Proactive Agent Steering via Distilled Language-Action World Models
Mar 24, 2026Deploying safety-critical agents requires anticipating the consequences of actions before they are executed. While world models offer a paradigm for this proactive foresight, current approaches relying on visual simulation incur prohibitive latencies, often exceeding several seconds per step. In this work, we challenge the assumption that visual processing is necessary for failure prevention. We show that a trained policy's latent state, combined with its planned actions, already encodes sufficient information to anticipate action outcomes, making visual simulation redundant for failure prevention. To this end, we introduce DILLO (DIstiLLed Language-ActiOn World Model), a fast steering layer that shifts the paradigm from "simulate-then-act" to "describe-then-act." DILLO is trained via cross-modal distillation, where a privileged Vision Language Model teacher annotates offline trajectories and a latent-conditioned Large Language Model student learns to predict semantic outcomes. This creates a text-only inference path, bypassing heavy visual generation entirely, achieving a 14x speedup over baselines. Experiments on MetaWorld and LIBERO demonstrate that DILLO produces high-fidelity descriptions of the next state and is able to steer the policy, improving episode success rate by up to 15 pp and 9.3 pp on average across tasks.
Not All Latent Spaces Are Flat: Hyperbolic Concept Control
Mar 14, 2026As modern text-to-image (T2I) models draw closer to synthesizing highly realistic content, the threat of unsafe content generation grows, and it becomes paramount to exercise control. Existing approaches steer these models by applying Euclidean adjustments to text embeddings, redirecting the generation away from unsafe concepts. In this work, we introduce hyperbolic control (HyCon): a novel control mechanism based on parallel transport that leverages semantically aligned hyperbolic representation space to yield more expressive and stable manipulation of concepts. HyCon reuses off-the-shelf generative models and a state-of-the-art hyperbolic text encoder, linked via a lightweight adapter. HyCon achieves state-of-the-art results across four safety benchmarks and four T2I backbones, showing that hyperbolic steering is a practical and flexible approach for more reliable T2I generation.
PhysTalk: Language-driven Real-time Physics in 3D Gaussian Scenes
Dec 31, 2025Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
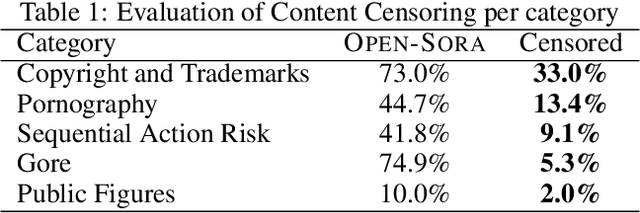
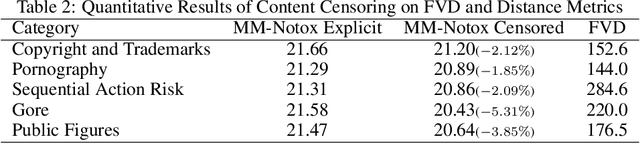

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
LongCodeBench: Evaluating Coding LLMs at 1M Context Windows
May 12, 2025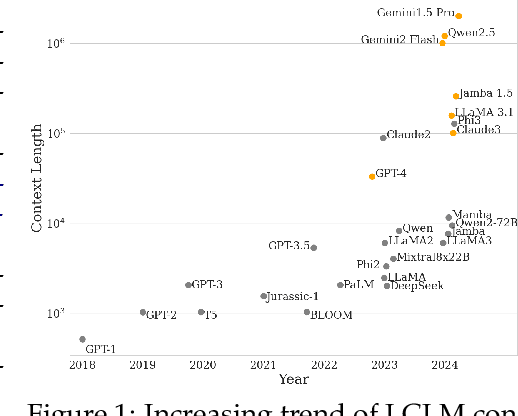
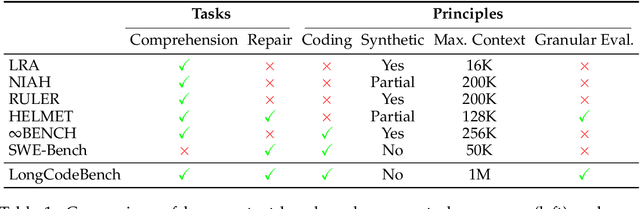
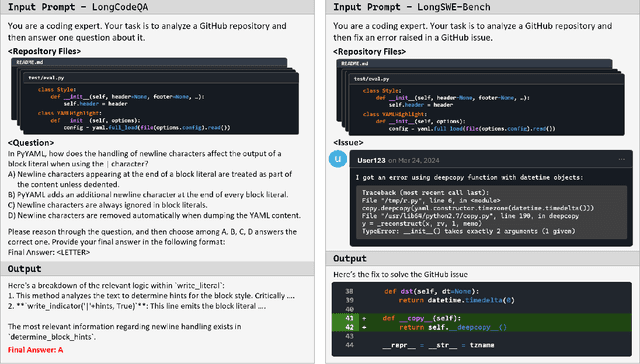
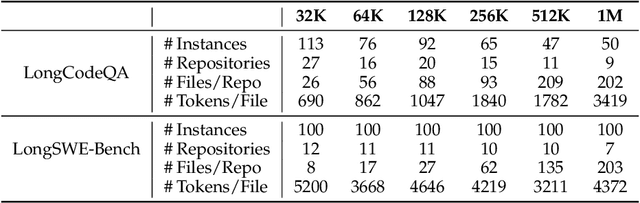
Context lengths for models have grown rapidly, from thousands to millions of tokens in just a few years. The extreme context sizes of modern long-context models have made it difficult to construct realistic long-context benchmarks -- not only due to the cost of collecting million-context tasks but also in identifying realistic scenarios that require significant contexts. We identify code comprehension and repair as a natural testbed and challenge task for long-context models and introduce LongCodeBench (LCB), a benchmark to test LLM coding abilities in long-context scenarios. Our benchmark tests both the comprehension and repair capabilities of LCLMs in realistic and important settings by drawing from real-world GitHub issues and constructing QA (LongCodeQA) and bug fixing (LongSWE-Bench) tasks. We carefully stratify the complexity of our benchmark, enabling us to evaluate models across different scales -- ranging from Qwen2.5 14B Instruct to Google's flagship Gemini model. We find that long-context remains a weakness for all models, with performance drops such as from 29% to 3% for Claude 3.5 Sonnet, or from 70.2% to 40% for Qwen2.5.