 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCodeBench: Evaluating Coding LLMs at 1M Context Windows
May 12, 2025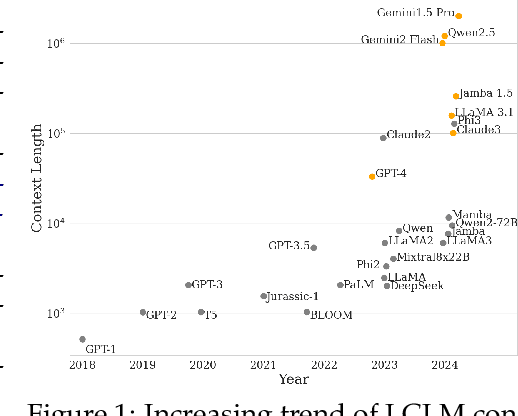
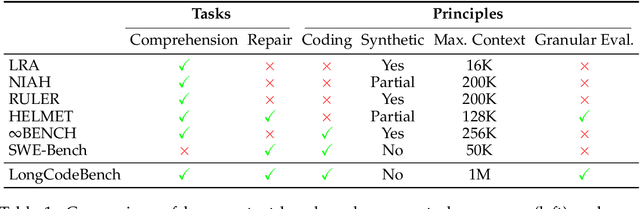
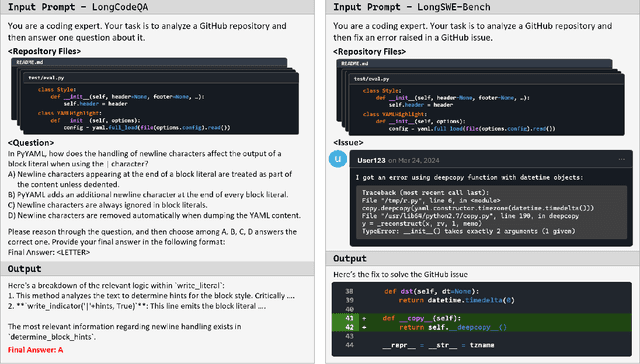
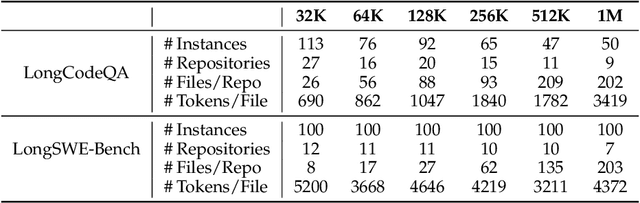
Context lengths for models have grown rapidly, from thousands to millions of tokens in just a few years. The extreme context sizes of modern long-context models have made it difficult to construct realistic long-context benchmarks -- not only due to the cost of collecting million-context tasks but also in identifying realistic scenarios that require significant contexts. We identify code comprehension and repair as a natural testbed and challenge task for long-context models and introduce LongCodeBench (LCB), a benchmark to test LLM coding abilities in long-context scenarios. Our benchmark tests both the comprehension and repair capabilities of LCLMs in realistic and important settings by drawing from real-world GitHub issues and constructing QA (LongCodeQA) and bug fixing (LongSWE-Bench) tasks. We carefully stratify the complexity of our benchmark, enabling us to evaluate models across different scales -- ranging from Qwen2.5 14B Instruct to Google's flagship Gemini model. We find that long-context remains a weakness for all models, with performance drops such as from 29% to 3% for Claude 3.5 Sonnet, or from 70.2% to 40% for Qwen2.5.
SeRpEnt: Selective Resampling for Expressive State Space Models
Jan 20, 2025



State Space Models (SSMs) have recently enjoyed a rise to prominence in the field of deep learning for sequence modeling, especially as an alternative to Transformers. Their success stems from avoiding two well-known drawbacks of attention-based models: quadratic complexity with respect to the sequence length and inability to model long-range dependencies. The SSM variant Mamba has demonstrated performance comparable to Transformers without any form of attention, thanks to the use of a selective mechanism for the state parameters. Selectivity, however, is only evaluated empirically and the reasons of its effectiveness remain unclear. In this work, we show how selectivity is related to the sequence processing. Our analysis shows that selective time intervals in Mamba act as linear approximators of information. Then, we propose our SeRpEnt architecture, a SSM that further exploits selectivity to compress sequences in an information-aware fashion. It employs a resampling mechanism that aggregates elements based on their information content. Our empirical results in the Long Range Arena benchmark and other language modeling tasks show benefits of the SeRpEnt's resampling mechanism.
Latent Conservative Objective Models for Data-Driven Crystal Structure Prediction
Oct 16, 2023



In computational chemistry, crystal structure prediction (CSP) is an optimization problem that involves discovering the lowest energy stable crystal structure for a given chemical formula. This problem is challenging as it requires discovering globally optimal designs with the lowest energies on complex manifolds. One approach to tackle this problem involves building simulators based on density functional theory (DFT) followed by running search in simulation, but these simulators are painfully slow. In this paper, we study present and study an alternate, data-driven approach to crystal structure prediction: instead of directly searching for the most stable structures in simulation, we train a surrogate model of the crystal formation energy from a database of existing crystal structures, and then optimize this model with respect to the parameters of the crystal structure. This surrogate model is trained to be conservative so as to prevent exploitation of its errors by the optimizer. To handle optimization in the non-Euclidean space of crystal structures, we first utilize a state-of-the-art graph diffusion auto-encoder (CD-VAE) to convert a crystal structure into a vector-based search space and then optimize a conservative surrogate model of the crystal energy, trained on top of this vector representation. We show that our approach, dubbed LCOMs (latent conservative objective models), performs comparably to the best current approaches in terms of success rate of structure prediction, while also drastically reducing computational cost.