 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bitter Lesson for Data Filtering
May 19, 2026We investigate data filtering for large model pretraining via new scaling studies that target the high compute, data-scarce regime. In spite of an apparently common belief that filtering data to include only high-quality information is essential, our experiments suggest that with enough compute, the best data filter is no data filter. We find that sufficiently trained large parameter models not only tolerate low-quality and distractor data, but in fact benefit from nominally ``poor'' data.
Scaling Self-Play with Self-Guidance
Apr 22, 2026LLM self-play algorithms are notable in that, in principle, nothing bounds their learning: a Conjecturer model creates problems for a Solver, and both improve together. However, in practice, existing LLM self-play methods do not scale well with large amounts of compute, instead hitting learning plateaus. We argue this is because over long training runs, the Conjecturer learns to hack its reward, collapsing to artificially complex problems that do not help the Solver improve. To overcome this, we introduce Self-Guided Self-Play (SGS), a self-play algorithm in which the language model itself guides the Conjecturer away from degeneracy. In SGS, the model takes on three roles: Solver, Conjecturer, and a Guide that scores synthetic problems by their relevance to unsolved target problems and how clean and natural they are, providing supervision against Conjecturer collapse. Our core hypothesis is that language models can assess whether a subproblem is useful for achieving a goal. We evaluate the scaling properties of SGS by running training for significantly longer than prior works and by fitting scaling laws to cumulative solve rate curves. Applying SGS to formal theorem proving in Lean4, we find that it surpasses the asymptotic solve rate of our strongest RL baseline in fewer than 80 rounds of self-play and enables a 7B parameter model, after 200 rounds of self-play, to solve more problems than a 671B parameter model pass@4.
Synthetic Data for any Differentiable Target
Apr 09, 2026What are the limits of controlling language models via synthetic training data? We develop a reinforcement learning (RL) primitive, the Dataset Policy Gradient (DPG), which can precisely optimize synthetic data generators to produce a dataset of targeted examples. When used for supervised fine-tuning (SFT) of a target model, these examples cause the target model to do well on a differentiable metric of our choice. Our approach achieves this by taking exact data attribution via higher-order gradients and using those scores as policy gradient rewards. We prove that this procedure closely approximates the true, intractable gradient for the synthetic data generator. To illustrate the potential of DPG, we show that, using only SFT on generated examples, we can cause the target model's LM head weights to (1) embed a QR code, (2) embed the pattern $\texttt{67}$, and (3) have lower $\ell^2$ norm. We additionally show that we can cause the generator to (4) rephrase inputs in a new language and (5) produce a specific UUID, even though neither of these objectives is conveyed in the generator's input prompts. These findings suggest that DPG is a powerful and flexible technique for shaping model properties using only synthetic training examples.
Data-efficient pre-training by scaling synthetic megadocs
Mar 19, 2026Synthetic data augmentation has emerged as a promising solution when pre-training is constrained by data rather than compute. We study how to design synthetic data algorithms that achieve better loss scaling: not only lowering loss at finite compute but especially as compute approaches infinity. We first show that pre-training on web data mixed with synthetically generated rephrases improves i.i.d. validation loss on the web data, despite the synthetic data coming from an entirely different distribution. With optimal mixing and epoching, loss and benchmark accuracy improve without overfitting as the number of synthetic generations grows, plateauing near $1.48\times$ data efficiency at 32 rephrases per document. We find even better loss scaling under a new perspective: synthetic generations from the same document can form a single substantially longer megadocument instead of many short documents. We show two ways to construct megadocs: stitching synthetic rephrases from the same web document or stretching a document by inserting rationales. Both methods improve i.i.d. loss, downstream benchmarks, and especially long-context loss relative to simple rephrasing, increasing data efficiency from $1.48\times$ to $1.80\times$ at $32$ generations per document. Importantly, the improvement of megadocs over simple rephrasing widens as more synthetic data is generated. Our results show how to design synthetic data algorithms that benefit more from increasing compute when data-constrained.
Towards Execution-Grounded Automated AI Research
Jan 20, 2026Automated AI research holds great potential to accelerate scientific discovery. However, current LLMs often generate plausible-looking but ineffective ideas. Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback. To investigate these, we first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. We then convert two realistic research problems - LLM pre-training and post-training - into execution environments and demonstrate that our automated executor can implement a large fraction of the ideas sampled from frontier LLMs. We analyze two methods to learn from the execution feedback: evolutionary search and reinforcement learning. Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline (69.4% vs 48.0%) on post-training, and finds a pre-training recipe that outperforms the nanoGPT baseline (19.7 minutes vs 35.9 minutes) on pre-training, all within just ten search epochs. Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends. Reinforcement learning from execution reward, on the other hand, suffers from mode collapse. It successfully improves the average reward of the ideator model but not the upper-bound, due to models converging on simple ideas. We thoroughly analyze the executed ideas and training dynamics to facilitate future efforts towards execution-grounded automated AI research.
End-to-End Test-Time Training for Long Context
Dec 31, 2025We formulate long-context language modeling as a problem in continual learning rather than architecture design. Under this formulation, we only use a standard architecture -- a Transformer with sliding-window attention. However, our model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. In addition, we improve the model's initialization for learning at test time via meta-learning at training time. Overall, our method, a form of Test-Time Training (TTT), is End-to-End (E2E) both at test time (via next-token prediction) and training time (via meta-learning), in contrast to previous forms. We conduct extensive experiments with a focus on scaling properties. In particular, for 3B models trained with 164B tokens, our method (TTT-E2E) scales with context length in the same way as Transformer with full attention, while others, such as Mamba 2 and Gated DeltaNet, do not. However, similar to RNNs, TTT-E2E has constant inference latency regardless of context length, making it 2.7 times faster than full attention for 128K context. Our code is publicly available.
Pre-training under infinite compute
Sep 18, 2025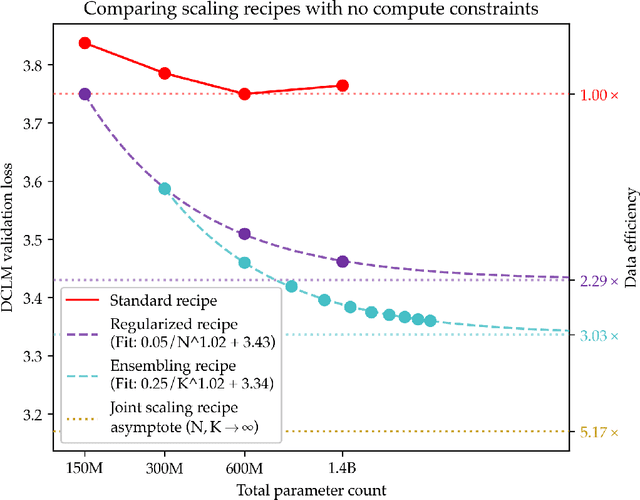

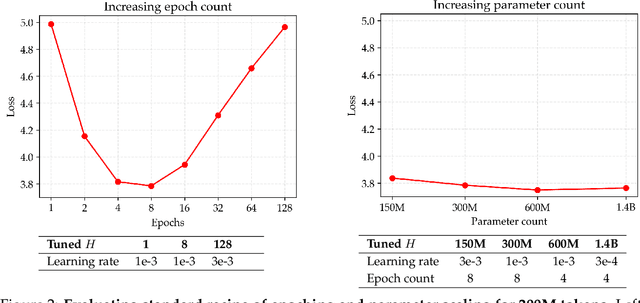
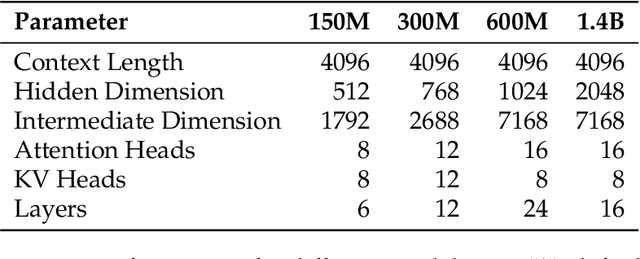
Since compute grows much faster than web text available for language model pre-training, we ask how one should approach pre-training under fixed data and no compute constraints. We first show that existing data-constrained approaches of increasing epoch count and parameter count eventually overfit, and we significantly improve upon such recipes by properly tuning regularization, finding that the optimal weight decay is $30\times$ larger than standard practice. Since our regularized recipe monotonically decreases loss following a simple power law in parameter count, we estimate its best possible performance via the asymptote of its scaling law rather than the performance at a fixed compute budget. We then identify that ensembling independently trained models achieves a significantly lower loss asymptote than the regularized recipe. Our best intervention combining epoching, regularization, parameter scaling, and ensemble scaling achieves an asymptote at 200M tokens using $5.17\times$ less data than our baseline, and our data scaling laws predict that this improvement persists at higher token budgets. We find that our data efficiency gains can be realized at much smaller parameter counts as we can distill an ensemble into a student model that is 8$\times$ smaller and retains $83\%$ of the ensembling benefit. Finally, our interventions designed for validation loss generalize to downstream benchmarks, achieving a $9\%$ improvement for pre-training evals and a $17.5\times$ data efficiency improvement over continued pre-training on math mid-training data. Our results show that simple algorithmic improvements can enable significantly more data-efficient pre-training in a compute-rich future.
Synthetic bootstrapped pretraining
Sep 17, 2025We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers a significant fraction of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases -- SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
The Ideation-Execution Gap: Execution Outcomes of LLM-Generated versus Human Research Ideas
Jun 25, 2025Large Language Models (LLMs) have shown promise in accelerating the scientific research pipeline. A key capability for this process is the ability to generate novel research ideas, and prior studies have found settings in which LLM-generated research ideas were judged as more novel than human-expert ideas. However, a good idea should not simply appear to be novel, it should also result in better research after being executed. To test whether AI-generated ideas lead to better research outcomes, we conduct an execution study by recruiting 43 expert researchers to execute randomly-assigned ideas, either written by experts or generated by an LLM. Each expert spent over 100 hours implementing the idea and wrote a 4-page short paper to document the experiments. All the executed projects are then reviewed blindly by expert NLP researchers. Comparing the review scores of the same ideas before and after execution, the scores of the LLM-generated ideas decrease significantly more than expert-written ideas on all evaluation metrics (novelty, excitement, effectiveness, and overall; p < 0.05), closing the gap between LLM and human ideas observed at the ideation stage. When comparing the aggregated review scores from the execution study, we even observe that for many metrics there is a flip in rankings where human ideas score higher than LLM ideas. This ideation-execution gap highlights the limitations of current LLMs in generating truly effective research ideas and the challenge of evaluating research ideas in the absence of execution outcomes.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.