 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegral Field Unit Spectroscopy with One Fiber
Jun 08, 2026Integral field unit (IFU) spectroscopy provides spatially resolved spectra across galaxies, offering crucial insights into their evolution. However, its high observational cost limits current IFU datasets to $\sim 10^4$ objects. We present a multi-modal, probabilistic foundation model that predicts high-resolution spectra with calibrated uncertainties at arbitrary spatial locations within a galaxy directly from broadband images. Built on a masked autoencoder framework, our architecture injects fiber positional encodings and redshift aware wavelength encodings, enabling spatially conditioned predictions. Trained on 4.7 million images and single fiber spectroscopic observations from the Dark Energy Spectroscopic Instrument (DESI) survey, our model exploits the natural variance of fiber placements and the morphological self-similarity of galaxies to achieve IFU-like capabilities without any IFU training data. Predicted emission line flux maps match independent IFU observations from the Mapping Nearby Galaxies at APO (MaNGA) survey, with performance comparable to a supervised baseline trained directly on IFU data.
Causal Risk Minimization for High-Dimensional Treatments
May 26, 2026Predicting the effect of interventions with many possible variations, e.g., therapeutic content that affects mental health outcomes or an earnings call transcript that drives movement in share price, is useful across several domains. However, classical causal estimators tend to assume that all possible interventions are observed, which is infeasible when interventions vary widely, for instance, in the space of all text strings. We adapt a well-known approach of recasting causal inference as a learning problem, to address high-dimensional treatment spaces. Specifically, under standard assumptions like no unobserved confounding, we show that causal error decomposes into a series of moment-balancing errors of increasing order, and design objectives that directly improve causal estimation. We also show how to project the effect of a high-dimensional treatment onto lower-dimensional treatment attributes, which allows a single model to answer several causal questions without additional attribute-specific training. We empirically evaluate our estimators in settings with high-dimensional continuous, discrete, and text treatments, the last of which used a semi-synthetic dataset of Amazon Reviews. Our experiments demonstrate the benefit of higher-order balance error optimization and competitive performance of projected causal estimates with attribute-specific estimators.
Predicting Large Model Test Losses with a Noisy Quadratic System
May 09, 2026We introduce a predictive model that estimates the pre-training loss of large models from model size (N), batch size (B) and number of weight updates (K). This is the first loss prediction model that can handle changing batch size. The model outperforms Chinchilla's loss model, a model of the test loss using the batch size and number of tokens, in terms of projecting the loss at extrapolated compute budgets (up to 1000 folds). A natural use of the model is to find optimal N, B, K configurations under explicit and compound resource constraints like time, memory and compute. In our experiments, the model-selected configurations are close to ground-truth optimal. Our work advocates for loss prediction as a better alternative to heuristic-based laws, which are growing in complexity. The implementation is available on https://github.com/chuningxdy/Noisy-Quadratic-System.
Measuring Scientific Capabilities of Language Models with a Systems Biology Dry Lab
Jul 02, 2025
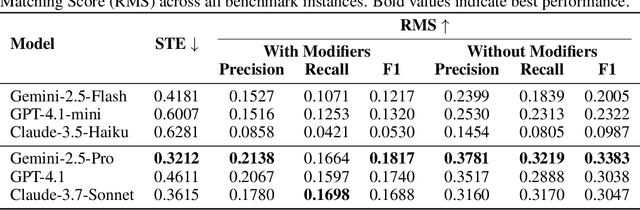
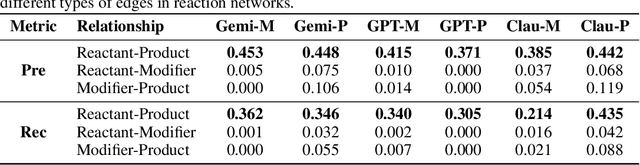
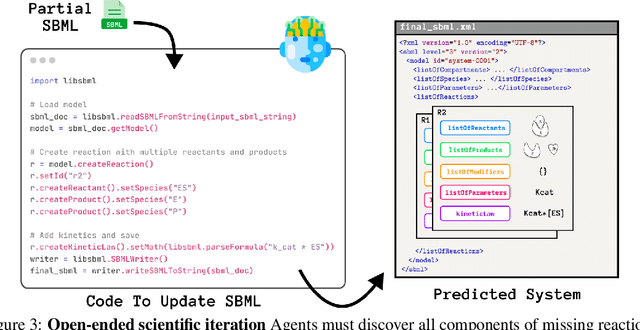
Designing experiments and result interpretations are core scientific competencies, particularly in biology, where researchers perturb complex systems to uncover the underlying systems. Recent efforts to evaluate the scientific capabilities of large language models (LLMs) fail to test these competencies because wet-lab experimentation is prohibitively expensive: in expertise, time and equipment. We introduce SciGym, a first-in-class benchmark that assesses LLMs' iterative experiment design and analysis abilities in open-ended scientific discovery tasks. SciGym overcomes the challenge of wet-lab costs by running a dry lab of biological systems. These models, encoded in Systems Biology Markup Language, are efficient for generating simulated data, making them ideal testbeds for experimentation on realistically complex systems. We evaluated six frontier LLMs on 137 small systems, and released a total of 350 systems. Our evaluation shows that while more capable models demonstrated superior performance, all models' performance declined significantly as system complexity increased, suggesting substantial room for improvement in the scientific capabilities of LLM agents.
BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model
May 29, 2025
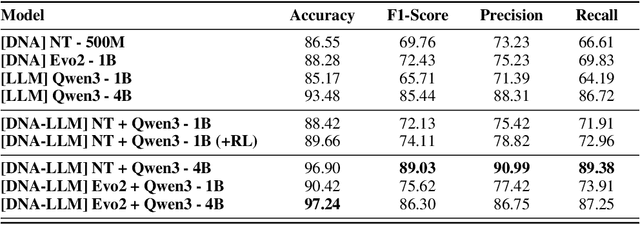


Unlocking deep, interpretable biological reasoning from complex genomic data is a major AI challenge hindering scientific discovery. Current DNA foundation models, despite strong sequence representation, struggle with multi-step reasoning and lack inherent transparent, biologically intuitive explanations. We introduce BioReason, a pioneering architecture that, for the first time, deeply integrates a DNA foundation model with a Large Language Model (LLM). This novel connection enables the LLM to directly process and reason with genomic information as a fundamental input, fostering a new form of multimodal biological understanding. BioReason's sophisticated multi-step reasoning is developed through supervised fine-tuning and targeted reinforcement learning, guiding the system to generate logical, biologically coherent deductions. On biological reasoning benchmarks including KEGG-based disease pathway prediction - where accuracy improves from 88% to 97% - and variant effect prediction, BioReason demonstrates an average 15% performance gain over strong single-modality baselines. BioReason reasons over unseen biological entities and articulates decision-making through interpretable, step-by-step biological traces, offering a transformative approach for AI in biology that enables deeper mechanistic insights and accelerates testable hypothesis generation from genomic data. Data, code, and checkpoints are publicly available at https://github.com/bowang-lab/BioReason
Enumerate-Conjecture-Prove: Formally Solving Answer-Construction Problems in Math Competitions
May 24, 2025Mathematical reasoning lies at the heart of artificial intelligence, underpinning applications in education, program verification, and research-level mathematical discovery. Mathematical competitions, in particular, present two challenging problem types: theorem-proving, requiring rigorous proofs of stated conclusions, and answer-construction, involving hypothesizing and formally verifying mathematical objects. Large Language Models (LLMs) effectively generate creative candidate answers but struggle with formal verification, while symbolic provers ensure rigor but cannot efficiently handle creative conjecture generation. We introduce the Enumerate-Conjecture-Prove (ECP) framework, a modular neuro-symbolic method integrating LLM-based enumeration and pattern-driven conjecturing with formal theorem proving. We present ConstructiveBench, a dataset of 3,431 answer-construction problems in various math competitions with verified Lean formalizations. On the ConstructiveBench dataset, ECP improves the accuracy of answer construction from the Chain-of-Thought (CoT) baseline of 14.54% to 45.06% with the gpt-4.1-mini model. Moreover, combining with ECP's constructed answers, the state-of-the-art DeepSeek-Prover-V2-7B model generates correct proofs for 858 of the 3,431 constructive problems in Lean, achieving 25.01% accuracy, compared to 9.86% for symbolic-only baselines. Our code and dataset are publicly available at GitHub and HuggingFace, respectively.
Reasoning to Learn from Latent Thoughts
Mar 24, 2025Compute scaling for language model (LM) pretraining has outpaced the growth of human-written texts, leading to concerns that data will become the bottleneck to LM scaling. To continue scaling pretraining in this data-constrained regime, we propose that explicitly modeling and inferring the latent thoughts that underlie the text generation process can significantly improve pretraining data efficiency. Intuitively, our approach views web text as the compressed final outcome of a verbose human thought process and that the latent thoughts contain important contextual knowledge and reasoning steps that are critical to data-efficient learning. We empirically demonstrate the effectiveness of our approach through data-constrained continued pretraining for math. We first show that synthetic data approaches to inferring latent thoughts significantly improve data efficiency, outperforming training on the same amount of raw data (5.7\% $\rightarrow$ 25.4\% on MATH). Furthermore, we demonstrate latent thought inference without a strong teacher, where an LM bootstraps its own performance by using an EM algorithm to iteratively improve the capability of the trained LM and the quality of thought-augmented pretraining data. We show that a 1B LM can bootstrap its performance across at least three iterations and significantly outperform baselines trained on raw data, with increasing gains from additional inference compute when performing the E-step. The gains from inference scaling and EM iterations suggest new opportunities for scaling data-constrained pretraining.
On the Efficiency of ERM in Feature Learning
Nov 18, 2024Given a collection of feature maps indexed by a set $\mathcal{T}$, we study the performance of empirical risk minimization (ERM) on regression problems with square loss over the union of the linear classes induced by these feature maps. This setup aims at capturing the simplest instance of feature learning, where the model is expected to jointly learn from the data an appropriate feature map and a linear predictor. We start by studying the asymptotic quantiles of the excess risk of sequences of empirical risk minimizers. Remarkably, we show that when the set $\mathcal{T}$ is not too large and when there is a unique optimal feature map, these quantiles coincide, up to a factor of two, with those of the excess risk of the oracle procedure, which knows a priori this optimal feature map and deterministically outputs an empirical risk minimizer from the associated optimal linear class. We complement this asymptotic result with a non-asymptotic analysis that quantifies the decaying effect of the global complexity of the set $\mathcal{T}$ on the excess risk of ERM, and relates it to the size of the sublevel sets of the suboptimality of the feature maps. As an application of our results, we obtain new guarantees on the performance of the best subset selection procedure in sparse linear regression under general assumptions.
End-To-End Causal Effect Estimation from Unstructured Natural Language Data
Jul 09, 2024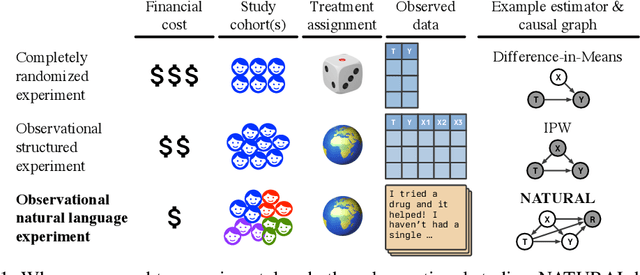
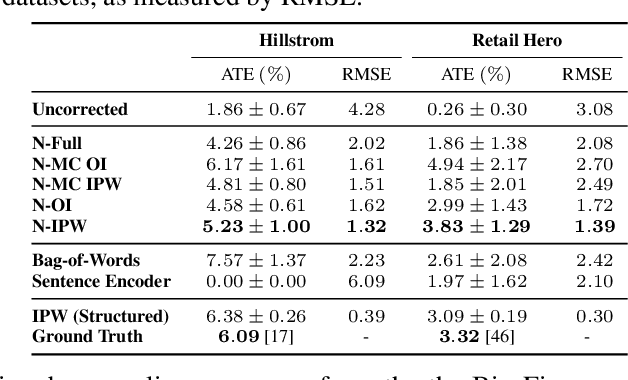
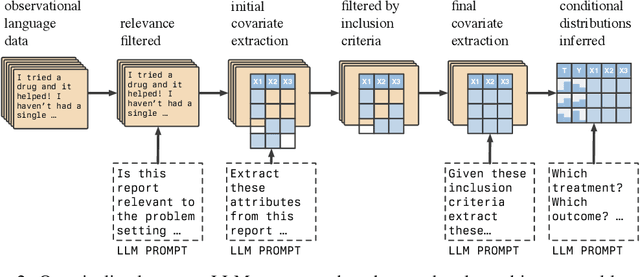

Knowing the effect of an intervention is critical for human decision-making, but current approaches for causal effect estimation rely on manual data collection and structuring, regardless of the causal assumptions. This increases both the cost and time-to-completion for studies. We show how large, diverse observational text data can be mined with large language models (LLMs) to produce inexpensive causal effect estimates under appropriate causal assumptions. We introduce NATURAL, a novel family of causal effect estimators built with LLMs that operate over datasets of unstructured text. Our estimators use LLM conditional distributions (over variables of interest, given the text data) to assist in the computation of classical estimators of causal effect. We overcome a number of technical challenges to realize this idea, such as automating data curation and using LLMs to impute missing information. We prepare six (two synthetic and four real) observational datasets, paired with corresponding ground truth in the form of randomized trials, which we used to systematically evaluate each step of our pipeline. NATURAL estimators demonstrate remarkable performance, yielding causal effect estimates that fall within 3 percentage points of their ground truth counterparts, including on real-world Phase 3/4 clinical trials. Our results suggest that unstructured text data is a rich source of causal effect information, and NATURAL is a first step towards an automated pipeline to tap this resource.
APPL: A Prompt Programming Language for Harmonious Integration of Programs and Large Language Model Prompts
Jun 19, 2024Large Language Models (LLMs) have become increasingly capable of handling diverse tasks with the aid of well-crafted prompts and integration of external tools, but as task complexity rises, the workflow involving LLMs can be complicated and thus challenging to implement and maintain. To address this challenge, we propose APPL, A Prompt Programming Language that acts as a bridge between computer programs and LLMs, allowing seamless embedding of prompts into Python functions, and vice versa. APPL provides an intuitive and Python-native syntax, an efficient parallelized runtime with asynchronous semantics, and a tracing module supporting effective failure diagnosis and replaying without extra costs. We demonstrate that APPL programs are intuitive, concise, and efficient through three representative scenarios: Chain-of-Thought with self-consistency (CoT-SC), ReAct tool use agent, and multi-agent chat. Experiments on three parallelizable workflows further show that APPL can effectively parallelize independent LLM calls, with a significant speedup ratio that almost matches the estimation.