 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuTeGen: An LLM-Based Agentic Framework for Generation and Optimization of High-Performance GPU Kernels using CuTe
Apr 01, 2026High-performance GPU kernels are critical to modern machine learning systems, yet developing efficient implementations remains a challenging, expert-driven process due to the tight coupling between algorithmic structure, memory hierarchy usage, and hardware-specific optimizations. Recent work has explored using large language models (LLMs) to generate GPU kernels automatically, but generated implementations often struggle to maintain correctness and achieve competitive performance across iterative refinements. We present CuTeGen, an agentic framework for automated generation and optimization of GPU kernels that treats kernel development as a structured generate--test--refine workflow. Unlike approaches that rely on one-shot generation or large-scale search over candidate implementations, CuTeGen focuses on progressive refinement of a single evolving kernel through execution-based validation, structured debugging, and staged optimization. A key design choice is to generate kernels using the CuTe abstraction layer, which exposes performance-critical structures such as tiling and data movement while providing a more stable representation for iterative modification. To guide performance improvement, CuTeGen incorporates workload-aware optimization prompts and delayed integration of profiling feedback. Experimental results on matrix multiplication and activation workloads demonstrate that the framework produces functionally correct kernels and achieves competitive performance relative to optimized library implementations.
Beyond Message Passing: A Symbolic Alternative for Expressive and Interpretable Graph Learning
Feb 18, 2026Graph Neural Networks (GNNs) have become essential in high-stakes domains such as drug discovery, yet their black-box nature remains a significant barrier to trustworthiness. While self-explainable GNNs attempt to bridge this gap, they often rely on standard message-passing backbones that inherit fundamental limitations, including the 1-Weisfeiler-Lehman (1-WL) expressivity barrier and a lack of fine-grained interpretability. To address these challenges, we propose SymGraph, a symbolic framework designed to transcend these constraints. By replacing continuous message passing with discrete structural hashing and topological role-based aggregation, our architecture theoretically surpasses the 1-WL barrier, achieving superior expressiveness without the overhead of differentiable optimization. Extensive empirical evaluations demonstrate that SymGraph achieves state-of-the-art performance, outperforming existing self-explainable GNNs. Notably, SymGraph delivers 10x to 100x speedups in training time using only CPU execution. Furthermore, SymGraph generates rules with superior semantic granularity compared to existing rule-based methods, offering great potential for scientific discovery and explainable AI.
Neural Proposals, Symbolic Guarantees: Neuro-Symbolic Graph Generation with Hard Constraints
Feb 18, 2026We challenge black-box purely deep neural approaches for molecules and graph generation, which are limited in controllability and lack formal guarantees. We introduce Neuro-Symbolic Graph Generative Modeling (NSGGM), a neurosymbolic framework that reapproaches molecule generation as a scaffold and interaction learning task with symbolic assembly. An autoregressive neural model proposes scaffolds and refines interaction signals, and a CPU-efficient SMT solver constructs full graphs while enforcing chemical validity, structural rules, and user-specific constraints, yielding molecules that are correct by construction and interpretable control that pure neural methods cannot provide. NSGGM delivers strong performance on both unconstrained generation and constrained generation tasks, demonstrating that neuro-symbolic modeling can match state-of-the-art generative performance while offering explicit controllability and guarantees. To evaluate more nuanced controllability, we also introduce a Logical-Constraint Molecular Benchmark, designed to test strict hard-rule satisfaction in workflows that require explicit, interpretable specifications together with verifiable compliance.
$τ^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Jun 09, 2025Existing benchmarks for conversational AI agents simulate single-control environments, where only the AI agent can use tools to interact with the world, while the user remains a passive information provider. This differs from real-world scenarios like technical support, where users need to actively participate in modifying the state of the (shared) world. In order to address this gap, we introduce $\tau^2$-bench, with four key contributions: 1) A novel Telecom dual-control domain modeled as a Dec-POMDP, where both agent and user make use of tools to act in a shared, dynamic environment that tests both agent coordination and communication, 2) A compositional task generator that programmatically creates diverse, verifiable tasks from atomic components, ensuring domain coverage and controlled complexity, 3) A reliable user simulator tightly coupled with the environment, whose behavior is constrained by tools and observable states, improving simulation fidelity, 4) Fine-grained analysis of agent performance through multiple ablations including separating errors arising from reasoning vs communication/coordination. In particular, our experiments show significant performance drops when agents shift from no-user to dual-control, highlighting the challenges of guiding users. Overall, $\tau^2$-bench provides a controlled testbed for agents that must both reason effectively and guide user actions.
Extracting Interpretable Logic Rules from Graph Neural Networks
Mar 25, 2025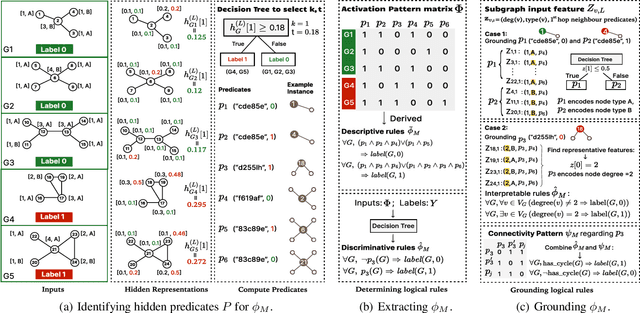

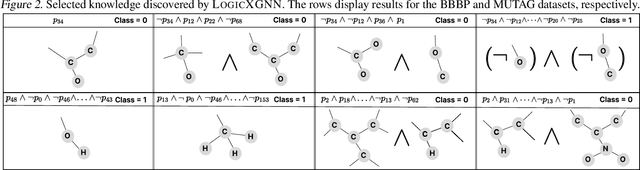
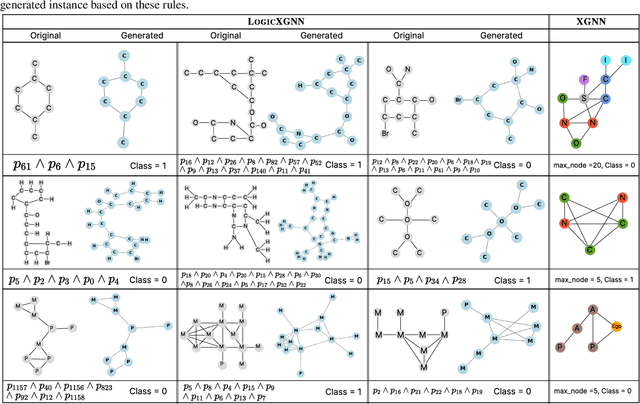
Graph neural networks (GNNs) operate over both input feature spaces and combinatorial graph structures, making it challenging to understand the rationale behind their predictions. As GNNs gain widespread popularity and demonstrate success across various domains, such as drug discovery, studying their interpretability has become a critical task. To address this, many explainability methods have been proposed, with recent efforts shifting from instance-specific explanations to global concept-based explainability. However, these approaches face several limitations, such as relying on predefined concepts and explaining only a limited set of patterns. To address this, we propose a novel framework, LOGICXGNN, for extracting interpretable logic rules from GNNs. LOGICXGNN is model-agnostic, efficient, and data-driven, eliminating the need for predefined concepts. More importantly, it can serve as a rule-based classifier and even outperform the original neural models. Its interpretability facilitates knowledge discovery, as demonstrated by its ability to extract detailed and accurate chemistry knowledge that is often overlooked by existing methods. Another key advantage of LOGICXGNN is its ability to generate new graph instances in a controlled and transparent manner, offering significant potential for applications such as drug design. We empirically demonstrate these merits through experiments on real-world datasets such as MUTAG and BBBP.
Learning Interpretable Logic Rules from Deep Vision Models
Mar 13, 2025

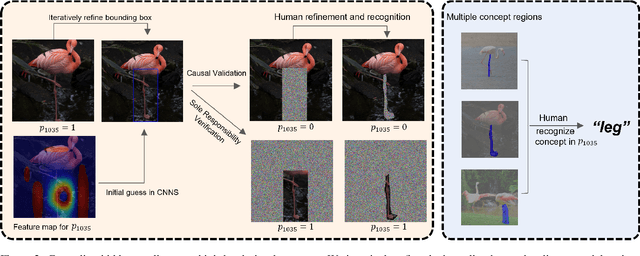

We propose a general framework called VisionLogic to extract interpretable logic rules from deep vision models, with a focus on image classification tasks. Given any deep vision model that uses a fully connected layer as the output head, VisionLogic transforms neurons in the last layer into predicates and grounds them into vision concepts using causal validation. In this way, VisionLogic can provide local explanations for single images and global explanations for specific classes in the form of logic rules. Compared to existing interpretable visualization tools such as saliency maps, VisionLogic addresses several key challenges, including the lack of causal explanations, overconfidence in visualizations, and ambiguity in interpretation. VisionLogic also facilitates the study of visual concepts encoded by predicates, particularly how they behave under perturbation -- an area that remains underexplored in the field of hidden semantics. Apart from providing better visual explanations and insights into the visual concepts learned by the model, we show that VisionLogic retains most of the neural network's discriminative power in an interpretable and transparent manner. We envision it as a bridge between complex model behavior and human-understandable explanations, providing trustworthy and actionable insights for real-world applications.
Proving Olympiad Inequalities by Synergizing LLMs and Symbolic Reasoning
Feb 19, 2025



Large language models (LLMs) can prove mathematical theorems formally by generating proof steps (\textit{a.k.a.} tactics) within a proof system. However, the space of possible tactics is vast and complex, while the available training data for formal proofs is limited, posing a significant challenge to LLM-based tactic generation. To address this, we introduce a neuro-symbolic tactic generator that synergizes the mathematical intuition learned by LLMs with domain-specific insights encoded by symbolic methods. The key aspect of this integration is identifying which parts of mathematical reasoning are best suited to LLMs and which to symbolic methods. While the high-level idea of neuro-symbolic integration is broadly applicable to various mathematical problems, in this paper, we focus specifically on Olympiad inequalities (Figure~1). We analyze how humans solve these problems and distill the techniques into two types of tactics: (1) scaling, handled by symbolic methods, and (2) rewriting, handled by LLMs. In addition, we combine symbolic tools with LLMs to prune and rank the proof goals for efficient proof search. We evaluate our framework on 161 challenging inequalities from multiple mathematics competitions, achieving state-of-the-art performance and significantly outperforming existing LLM and symbolic approaches without requiring additional training data.
RAG-Verus: Repository-Level Program Verification with LLMs using Retrieval Augmented Generation
Feb 07, 2025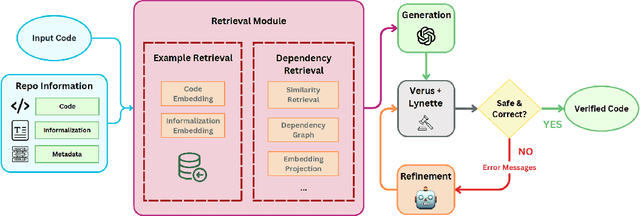
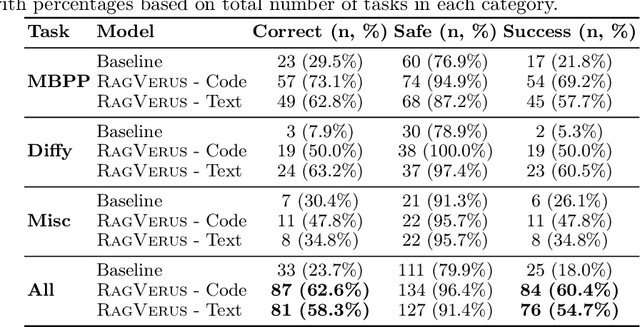
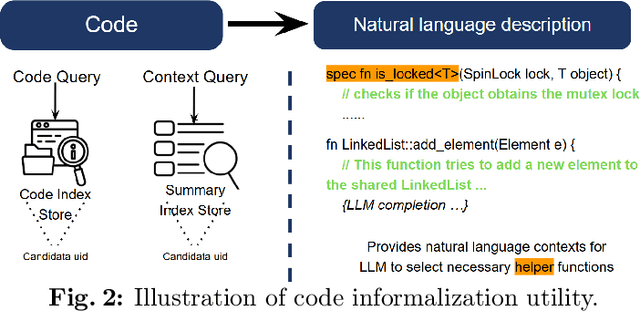
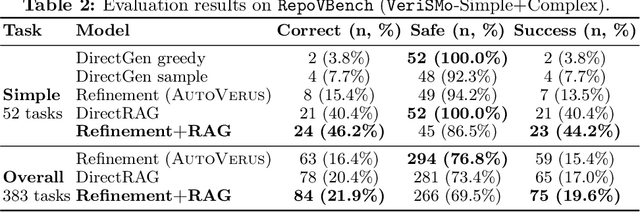
Scaling automated formal verification to real-world projects requires resolving cross-module dependencies and global contexts, which are challenges overlooked by existing function-centric methods. We introduce RagVerus, a framework that synergizes retrieval-augmented generation with context-aware prompting to automate proof synthesis for multi-module repositories, achieving a 27% relative improvement on our novel RepoVBench benchmark -- the first repository-level dataset for Verus with 383 proof completion tasks. RagVerus triples proof pass rates on existing benchmarks under constrained language model budgets, demonstrating a scalable and sample-efficient verification.
Decoding Interpretable Logic Rules from Neural Networks
Jan 14, 2025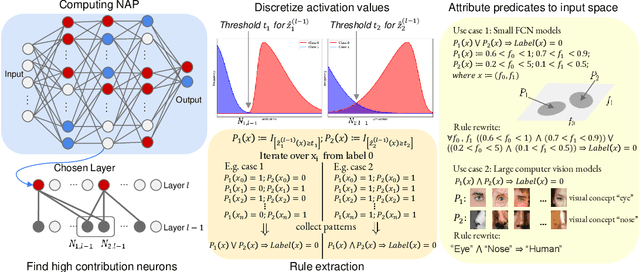
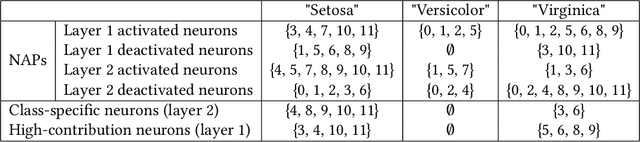
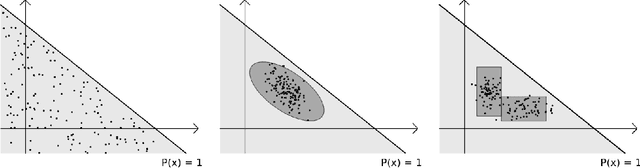
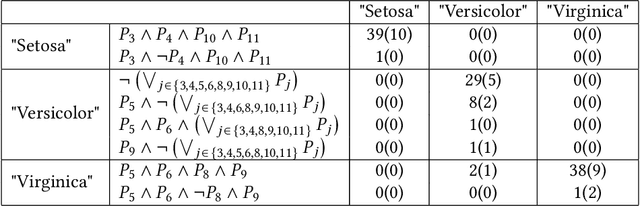
As deep neural networks continue to excel across various domains, their black-box nature has raised concerns about transparency and trust. In particular, interpretability has become increasingly essential for applications that demand high safety and knowledge rigor, such as drug discovery, autonomous driving, and genomics. However, progress in understanding even the simplest deep neural networks - such as fully connected networks - has been limited, despite their role as foundational elements in state-of-the-art models like ResNet and Transformer. In this paper, we address this challenge by introducing NeuroLogic, a novel approach for decoding interpretable logic rules from neural networks. NeuroLogic leverages neural activation patterns to capture the model's critical decision-making processes, translating them into logical rules represented by hidden predicates. Thanks to its flexible design in the grounding phase, NeuroLogic can be adapted to a wide range of neural networks. For simple fully connected neural networks, hidden predicates can be grounded in certain split patterns of original input features to derive decision-tree-like rules. For large, complex vision neural networks, NeuroLogic grounds hidden predicates into high-level visual concepts that are understandable to humans. Our empirical study demonstrates that NeuroLogic can extract global and interpretable rules from state-of-the-art models such as ResNet, a task at which existing work struggles. We believe NeuroLogic can help pave the way for understanding the black-box nature of neural networks.
Decoupling Training-Free Guided Diffusion by ADMM
Nov 18, 2024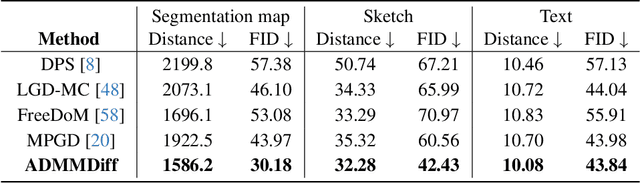
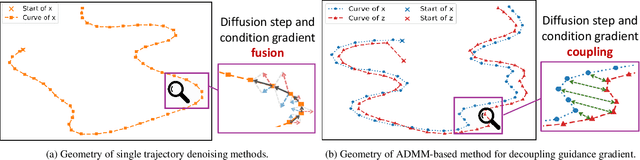


In this paper, we consider the conditional generation problem by guiding off-the-shelf unconditional diffusion models with differentiable loss functions in a plug-and-play fashion. While previous research has primarily focused on balancing the unconditional diffusion model and the guided loss through a tuned weight hyperparameter, we propose a novel framework that distinctly decouples these two components. Specifically, we introduce two variables ${x}$ and ${z}$, to represent the generated samples governed by the unconditional generation model and the guidance function, respectively. This decoupling reformulates conditional generation into two manageable subproblems, unified by the constraint ${x} = {z}$. Leveraging this setup, we develop a new algorithm based on the Alternating Direction Method of Multipliers (ADMM) to adaptively balance these components. Additionally, we establish the equivalence between the diffusion reverse step and the proximal operator of ADMM and provide a detailed convergence analysis of our algorithm under certain mild assumptions. Our experiments demonstrate that our proposed method ADMMDiff consistently generates high-quality samples while ensuring strong adherence to the conditioning criteria. It outperforms existing methods across a range of conditional generation tasks, including image generation with various guidance and controllable motion synthesis.