 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Valid Action Suppression in Unmasked Policy Gradient Algorithms
Mar 10, 2026In reinforcement learning environments with state-dependent action validity, action masking consistently outperforms penalty-based handling of invalid actions, yet existing theory only shows that masking preserves the policy gradient theorem. We identify a distinct failure mode of unmasked training: it systematically suppresses valid actions at states the agent has not yet visited. This occurs because gradients pushing down invalid actions at visited states propagate through shared network parameters to unvisited states where those actions are valid. We prove that for softmax policies with shared features, when an action is invalid at visited states but valid at an unvisited state $s^*$, the probability $π(a \mid s^*)$ is bounded by exponential decay due to parameter sharing and the zero-sum identity of softmax logits. This bound reveals that entropy regularization trades off between protecting valid actions and sample efficiency, a tradeoff that masking eliminates. We validate empirically that deep networks exhibit the feature alignment condition required for suppression, and experiments on Craftax, Craftax-Classic, and MiniHack confirm the predicted exponential suppression and demonstrate that feasibility classification enables deployment without oracle masks.
Algorithmic Prompt Generation for Diverse Human-like Teaming and Communication with Large Language Models
Apr 04, 2025



Understanding how humans collaborate and communicate in teams is essential for improving human-agent teaming and AI-assisted decision-making. However, relying solely on data from large-scale user studies is impractical due to logistical, ethical, and practical constraints, necessitating synthetic models of multiple diverse human behaviors. Recently, agents powered by Large Language Models (LLMs) have been shown to emulate human-like behavior in social settings. But, obtaining a large set of diverse behaviors requires manual effort in the form of designing prompts. On the other hand, Quality Diversity (QD) optimization has been shown to be capable of generating diverse Reinforcement Learning (RL) agent behavior. In this work, we combine QD optimization with LLM-powered agents to iteratively search for prompts that generate diverse team behavior in a long-horizon, multi-step collaborative environment. We first show, through a human-subjects experiment (n=54 participants), that humans exhibit diverse coordination and communication behavior in this domain. We then show that our approach can effectively replicate trends from human teaming data and also capture behaviors that are not easily observed without collecting large amounts of data. Our findings highlight the combination of QD and LLM-powered agents as an effective tool for studying teaming and communication strategies in multi-agent collaboration.
LogiCity: Advancing Neuro-Symbolic AI with Abstract Urban Simulation
Nov 01, 2024



Recent years have witnessed the rapid development of Neuro-Symbolic (NeSy) AI systems, which integrate symbolic reasoning into deep neural networks. However, most of the existing benchmarks for NeSy AI fail to provide long-horizon reasoning tasks with complex multi-agent interactions. Furthermore, they are usually constrained by fixed and simplistic logical rules over limited entities, making them far from real-world complexities. To address these crucial gaps, we introduce LogiCity, the first simulator based on customizable first-order logic (FOL) for an urban-like environment with multiple dynamic agents. LogiCity models diverse urban elements using semantic and spatial concepts, such as IsAmbulance(X) and IsClose(X, Y). These concepts are used to define FOL rules that govern the behavior of various agents. Since the concepts and rules are abstractions, they can be universally applied to cities with any agent compositions, facilitating the instantiation of diverse scenarios. Besides, a key feature of LogiCity is its support for user-configurable abstractions, enabling customizable simulation complexities for logical reasoning. To explore various aspects of NeSy AI, LogiCity introduces two tasks, one features long-horizon sequential decision-making, and the other focuses on one-step visual reasoning, varying in difficulty and agent behaviors. Our extensive evaluation reveals the advantage of NeSy frameworks in abstract reasoning. Moreover, we highlight the significant challenges of handling more complex abstractions in long-horizon multi-agent scenarios or under high-dimensional, imbalanced data. With its flexible design, various features, and newly raised challenges, we believe LogiCity represents a pivotal step forward in advancing the next generation of NeSy AI. All the code and data are open-sourced at our website.
SS-MAIL: Self-Supervised Multi-Agent Imitation Learning
Oct 18, 2021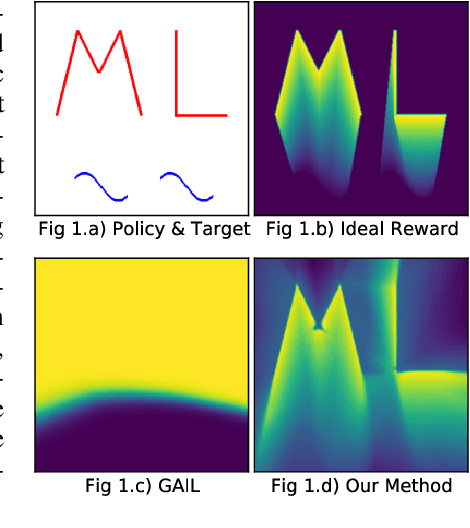
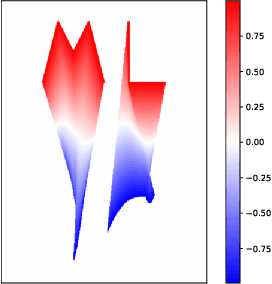
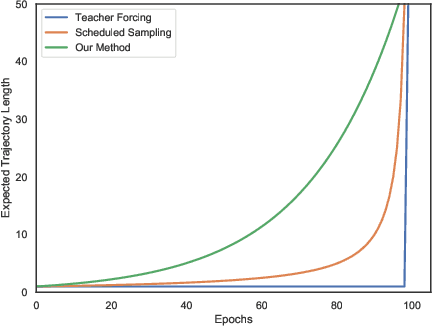
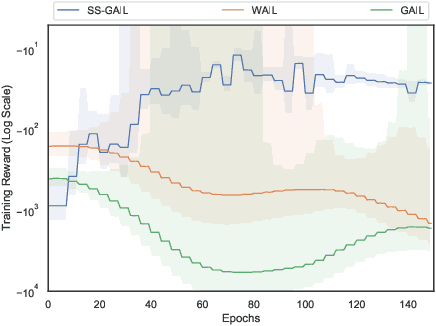
The current landscape of multi-agent expert imitation is broadly dominated by two families of algorithms - Behavioral Cloning (BC) and Adversarial Imitation Learning (AIL). BC approaches suffer from compounding errors, as they ignore the sequential decision-making nature of the trajectory generation problem. Furthermore, they cannot effectively model multi-modal behaviors. While AIL methods solve the issue of compounding errors and multi-modal policy training, they are plagued with instability in their training dynamics. In this work, we address this issue by introducing a novel self-supervised loss that encourages the discriminator to approximate a richer reward function. We employ our method to train a graph-based multi-agent actor-critic architecture that learns a centralized policy, conditioned on a learned latent interaction graph. We show that our method (SS-MAIL) outperforms prior state-of-the-art methods on real-world prediction tasks, as well as on custom-designed synthetic experiments. We prove that SS-MAIL is part of the family of AIL methods by providing a theoretical connection to cost-regularized apprenticeship learning. Moreover, we leverage the self-supervised formulation to introduce a novel teacher forcing-based curriculum (Trajectory Forcing) that improves sample efficiency by progressively increasing the length of the generated trajectory. The SS-MAIL framework improves multi-agent imitation capabilities by stabilizing the policy training, improving the reward shaping capabilities, as well as providing the ability for modeling multi-modal trajectories.