 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSS-MAIL: Self-Supervised Multi-Agent Imitation Learning
Paper and Code
Oct 18, 2021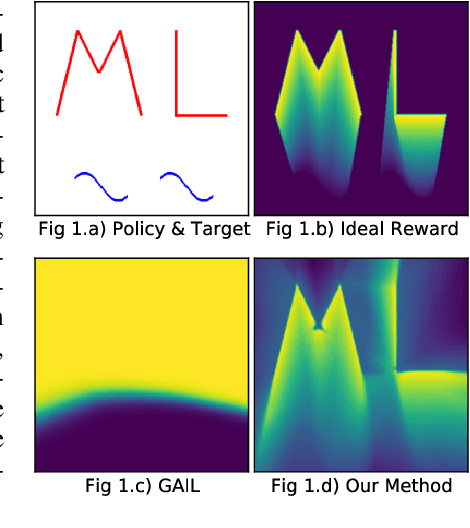
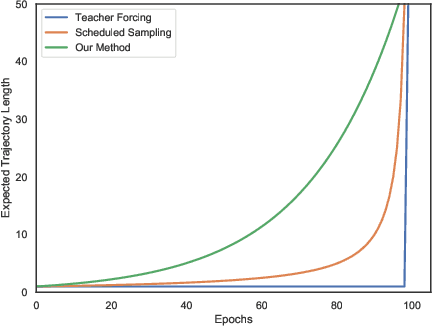
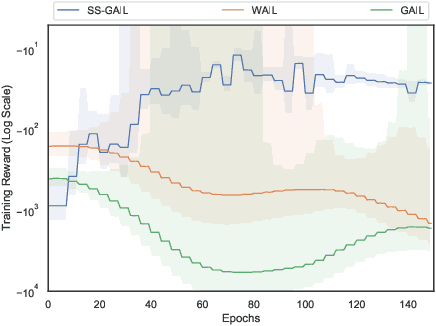
The current landscape of multi-agent expert imitation is broadly dominated by two families of algorithms - Behavioral Cloning (BC) and Adversarial Imitation Learning (AIL). BC approaches suffer from compounding errors, as they ignore the sequential decision-making nature of the trajectory generation problem. Furthermore, they cannot effectively model multi-modal behaviors. While AIL methods solve the issue of compounding errors and multi-modal policy training, they are plagued with instability in their training dynamics. In this work, we address this issue by introducing a novel self-supervised loss that encourages the discriminator to approximate a richer reward function. We employ our method to train a graph-based multi-agent actor-critic architecture that learns a centralized policy, conditioned on a learned latent interaction graph. We show that our method (SS-MAIL) outperforms prior state-of-the-art methods on real-world prediction tasks, as well as on custom-designed synthetic experiments. We prove that SS-MAIL is part of the family of AIL methods by providing a theoretical connection to cost-regularized apprenticeship learning. Moreover, we leverage the self-supervised formulation to introduce a novel teacher forcing-based curriculum (Trajectory Forcing) that improves sample efficiency by progressively increasing the length of the generated trajectory. The SS-MAIL framework improves multi-agent imitation capabilities by stabilizing the policy training, improving the reward shaping capabilities, as well as providing the ability for modeling multi-modal trajectories.