 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable deep learning improves human mental models of self-driving cars
Nov 27, 2024Self-driving cars increasingly rely on deep neural networks to achieve human-like driving. However, the opacity of such black-box motion planners makes it challenging for the human behind the wheel to accurately anticipate when they will fail, with potentially catastrophic consequences. Here, we introduce concept-wrapper network (i.e., CW-Net), a method for explaining the behavior of black-box motion planners by grounding their reasoning in human-interpretable concepts. We deploy CW-Net on a real self-driving car and show that the resulting explanations refine the human driver's mental model of the car, allowing them to better predict its behavior and adjust their own behavior accordingly. Unlike previous work using toy domains or simulations, our study presents the first real-world demonstration of how to build authentic autonomous vehicles (AVs) that give interpretable, causally faithful explanations for their decisions, without sacrificing performance. We anticipate our method could be applied to other safety-critical systems with a human in the loop, such as autonomous drones and robotic surgeons. Overall, our study suggests a pathway to explainability for autonomous agents as a whole, which can help make them more transparent, their deployment safer, and their usage more ethical.
SS-MAIL: Self-Supervised Multi-Agent Imitation Learning
Oct 18, 2021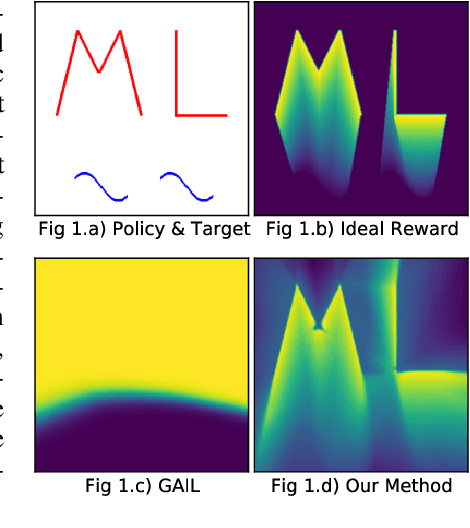
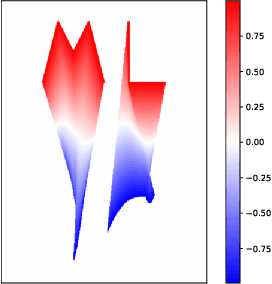
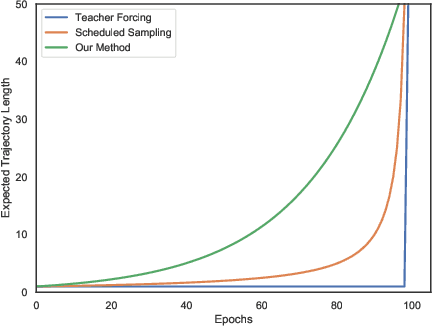
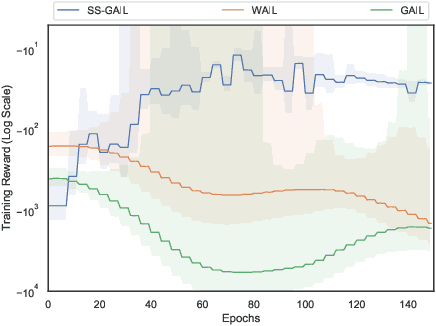
The current landscape of multi-agent expert imitation is broadly dominated by two families of algorithms - Behavioral Cloning (BC) and Adversarial Imitation Learning (AIL). BC approaches suffer from compounding errors, as they ignore the sequential decision-making nature of the trajectory generation problem. Furthermore, they cannot effectively model multi-modal behaviors. While AIL methods solve the issue of compounding errors and multi-modal policy training, they are plagued with instability in their training dynamics. In this work, we address this issue by introducing a novel self-supervised loss that encourages the discriminator to approximate a richer reward function. We employ our method to train a graph-based multi-agent actor-critic architecture that learns a centralized policy, conditioned on a learned latent interaction graph. We show that our method (SS-MAIL) outperforms prior state-of-the-art methods on real-world prediction tasks, as well as on custom-designed synthetic experiments. We prove that SS-MAIL is part of the family of AIL methods by providing a theoretical connection to cost-regularized apprenticeship learning. Moreover, we leverage the self-supervised formulation to introduce a novel teacher forcing-based curriculum (Trajectory Forcing) that improves sample efficiency by progressively increasing the length of the generated trajectory. The SS-MAIL framework improves multi-agent imitation capabilities by stabilizing the policy training, improving the reward shaping capabilities, as well as providing the ability for modeling multi-modal trajectories.
Hierarchical Average Reward Policy Gradient Algorithms
Nov 20, 2019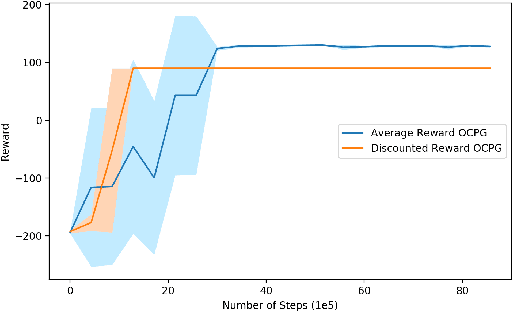

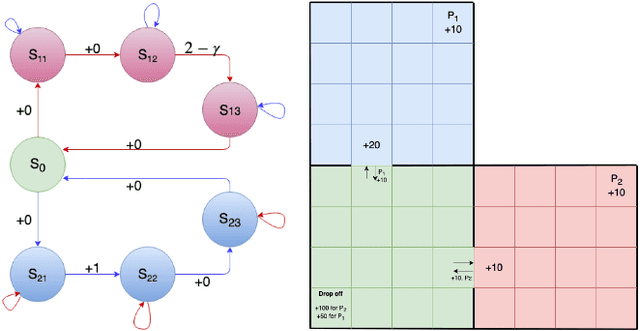
Option-critic learning is a general-purpose reinforcement learning (RL) framework that aims to address the issue of long term credit assignment by leveraging temporal abstractions. However, when dealing with extended timescales, discounting future rewards can lead to incorrect credit assignments. In this work, we address this issue by extending the hierarchical option-critic policy gradient theorem for the average reward criterion. Our proposed framework aims to maximize the long-term reward obtained in the steady-state of the Markov chain defined by the agent's policy. Furthermore, we use an ordinary differential equation based approach for our convergence analysis and prove that the parameters of the intra-option policies, termination functions, and value functions, converge to their corresponding optimal values, with probability one. Finally, we illustrate the competitive advantage of learning options, in the average reward setting, on a grid-world environment with sparse rewards.