 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Uncertainty-Aware Active Search with a Team of Aerial Robots
Oct 11, 2024Rapid search and rescue is critical to maximizing survival rates following natural disasters. However, these efforts are challenged by the need to search large disaster zones, lack of reliability in the communications infrastructure, and a priori unknown numbers of objects of interest (OOIs), such as injured survivors. Aerial robots are increasingly being deployed for search and rescue due to their high mobility, but there remains a gap in deploying multi-robot autonomous aerial systems for methodical search of large environments. Prior works have relied on preprogrammed paths from human operators or are evaluated only in simulation. We bridge these gaps in the state of the art by developing and demonstrating a decentralized active search system, which biases its trajectories to take additional views of uncertain OOIs. The methodology leverages stochasticity for rapid coverage in communication denied scenarios. When communications are available, robots share poses, goals, and OOI information to accelerate the rate of search. Extensive simulations and hardware experiments in Bloomingdale, OH, are conducted to validate the approach. The results demonstrate the active search approach outperforms greedy coverage-based planning in communication-denied scenarios while maintaining comparable performance in communication-enabled scenarios.
GUTS: Generalized Uncertainty-Aware Thompson Sampling for Multi-Agent Active Search
Apr 04, 2023



Robotic solutions for quick disaster response are essential to ensure minimal loss of life, especially when the search area is too dangerous or too vast for human rescuers. We model this problem as an asynchronous multi-agent active-search task where each robot aims to efficiently seek objects of interest (OOIs) in an unknown environment. This formulation addresses the requirement that search missions should focus on quick recovery of OOIs rather than full coverage of the search region. Previous approaches fail to accurately model sensing uncertainty, account for occlusions due to foliage or terrain, or consider the requirement for heterogeneous search teams and robustness to hardware and communication failures. We present the Generalized Uncertainty-aware Thompson Sampling (GUTS) algorithm, which addresses these issues and is suitable for deployment on heterogeneous multi-robot systems for active search in large unstructured environments. We show through simulation experiments that GUTS consistently outperforms existing methods such as parallelized Thompson Sampling and exhaustive search, recovering all OOIs in 80% of all runs. In contrast, existing approaches recover all OOIs in less than 40% of all runs. We conduct field tests using our multi-robot system in an unstructured environment with a search area of approximately 75,000 sq. m. Our system demonstrates robustness to various failure modes, achieving full recovery of OOIs (where feasible) in every field run, and significantly outperforming our baseline.
SS-MAIL: Self-Supervised Multi-Agent Imitation Learning
Oct 18, 2021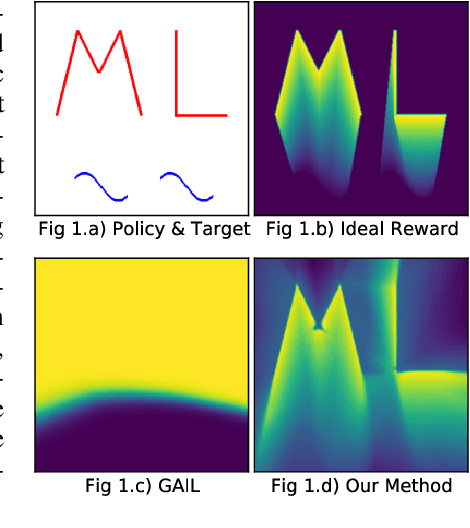
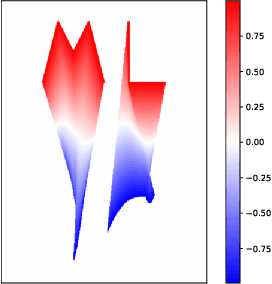
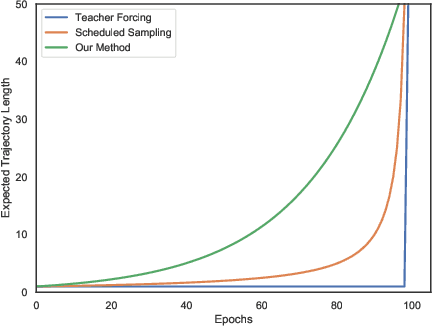
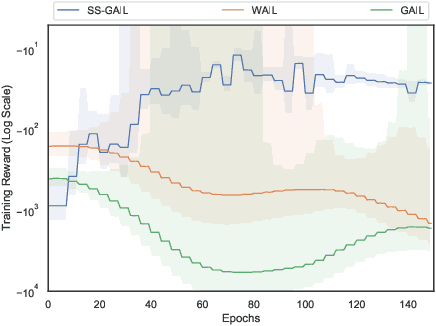
The current landscape of multi-agent expert imitation is broadly dominated by two families of algorithms - Behavioral Cloning (BC) and Adversarial Imitation Learning (AIL). BC approaches suffer from compounding errors, as they ignore the sequential decision-making nature of the trajectory generation problem. Furthermore, they cannot effectively model multi-modal behaviors. While AIL methods solve the issue of compounding errors and multi-modal policy training, they are plagued with instability in their training dynamics. In this work, we address this issue by introducing a novel self-supervised loss that encourages the discriminator to approximate a richer reward function. We employ our method to train a graph-based multi-agent actor-critic architecture that learns a centralized policy, conditioned on a learned latent interaction graph. We show that our method (SS-MAIL) outperforms prior state-of-the-art methods on real-world prediction tasks, as well as on custom-designed synthetic experiments. We prove that SS-MAIL is part of the family of AIL methods by providing a theoretical connection to cost-regularized apprenticeship learning. Moreover, we leverage the self-supervised formulation to introduce a novel teacher forcing-based curriculum (Trajectory Forcing) that improves sample efficiency by progressively increasing the length of the generated trajectory. The SS-MAIL framework improves multi-agent imitation capabilities by stabilizing the policy training, improving the reward shaping capabilities, as well as providing the ability for modeling multi-modal trajectories.
Predicting Human Strategies in Simulated Search and Rescue Task
Nov 19, 2020
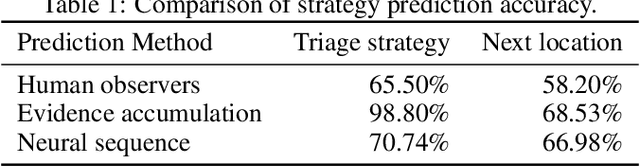

In a search and rescue scenario, rescuers may have different knowledge of the environment and strategies for exploration. Understanding what is inside a rescuer's mind will enable an observer agent to proactively assist them with critical information that can help them perform their task efficiently. To this end, we propose to build models of the rescuers based on their trajectory observations to predict their strategies. In our efforts to model the rescuer's mind, we begin with a simple simulated search and rescue task in Minecraft with human participants. We formulate neural sequence models to predict the triage strategy and the next location of the rescuer. As the neural networks are data-driven, we design a diverse set of artificial "faux human" agents for training, to test them with limited human rescuer trajectory data. To evaluate the agents, we compare it to an evidence accumulation method that explicitly incorporates all available background knowledge and provides an intended upper bound for the expected performance. Further, we perform experiments where the observer/predictor is human. We show results in terms of prediction accuracy of our computational approaches as compared with that of human observers.
f-IRL: Inverse Reinforcement Learning via State Marginal Matching
Nov 09, 2020


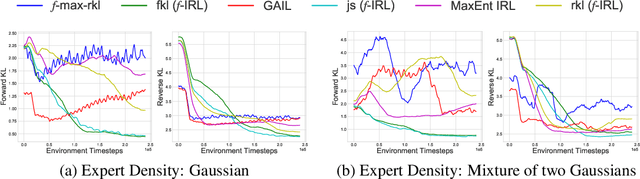
Imitation learning is well-suited for robotic tasks where it is difficult to directly program the behavior or specify a cost for optimal control. In this work, we propose a method for learning the reward function (and the corresponding policy) to match the expert state density. Our main result is the analytic gradient of any f-divergence between the agent and expert state distribution w.r.t. reward parameters. Based on the derived gradient, we present an algorithm, f-IRL, that recovers a stationary reward function from the expert density by gradient descent. We show that f-IRL can learn behaviors from a hand-designed target state density or implicitly through expert observations. Our method outperforms adversarial imitation learning methods in terms of sample efficiency and the required number of expert trajectories on IRL benchmarks. Moreover, we show that the recovered reward function can be used to quickly solve downstream tasks, and empirically demonstrate its utility on hard-to-explore tasks and for behavior transfer across changes in dynamics.
A Method for Computing Class-wise Universal Adversarial Perturbations
Dec 01, 2019
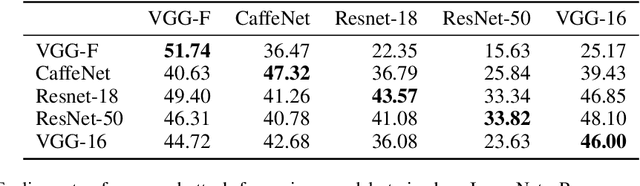


We present an algorithm for computing class-specific universal adversarial perturbations for deep neural networks. Such perturbations can induce misclassification in a large fraction of images of a specific class. Unlike previous methods that use iterative optimization for computing a universal perturbation, the proposed method employs a perturbation that is a linear function of weights of the neural network and hence can be computed much faster. The method does not require any training data and has no hyper-parameters. The attack obtains 34% to 51% fooling rate on state-of-the-art deep neural networks on ImageNet and transfers across models. We also study the characteristics of the decision boundaries learned by standard and adversarially trained models to understand the universal adversarial perturbations.