 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Uncertainty-Aware Active Search with a Team of Aerial Robots
Oct 11, 2024Rapid search and rescue is critical to maximizing survival rates following natural disasters. However, these efforts are challenged by the need to search large disaster zones, lack of reliability in the communications infrastructure, and a priori unknown numbers of objects of interest (OOIs), such as injured survivors. Aerial robots are increasingly being deployed for search and rescue due to their high mobility, but there remains a gap in deploying multi-robot autonomous aerial systems for methodical search of large environments. Prior works have relied on preprogrammed paths from human operators or are evaluated only in simulation. We bridge these gaps in the state of the art by developing and demonstrating a decentralized active search system, which biases its trajectories to take additional views of uncertain OOIs. The methodology leverages stochasticity for rapid coverage in communication denied scenarios. When communications are available, robots share poses, goals, and OOI information to accelerate the rate of search. Extensive simulations and hardware experiments in Bloomingdale, OH, are conducted to validate the approach. The results demonstrate the active search approach outperforms greedy coverage-based planning in communication-denied scenarios while maintaining comparable performance in communication-enabled scenarios.
"Influence Sketching": Finding Influential Samples In Large-Scale Regressions
Mar 23, 2017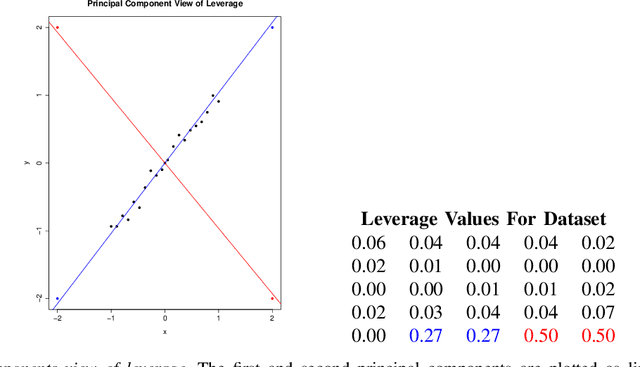
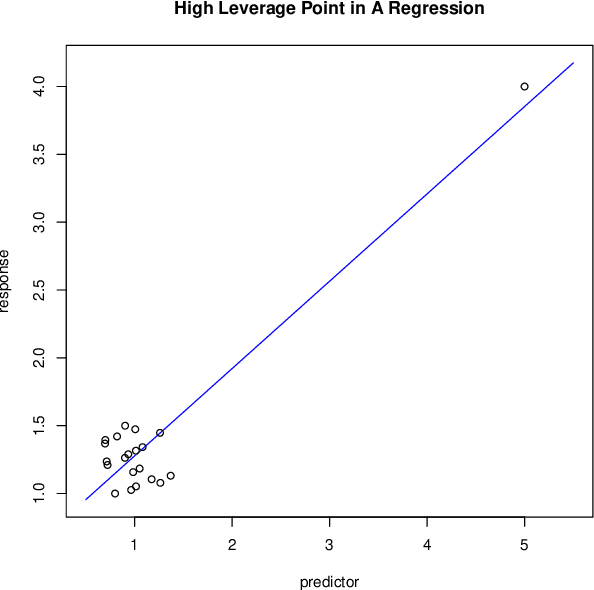

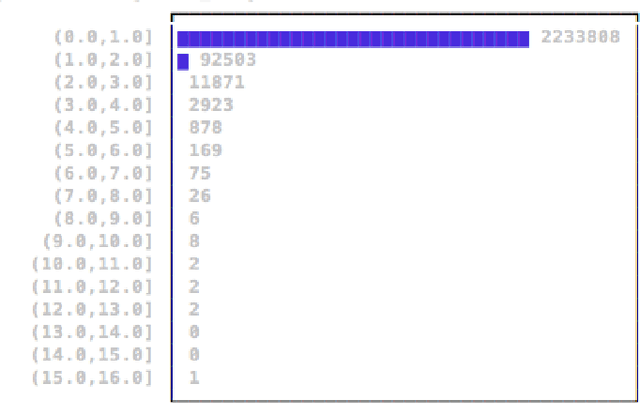
There is an especially strong need in modern large-scale data analysis to prioritize samples for manual inspection. For example, the inspection could target important mislabeled samples or key vulnerabilities exploitable by an adversarial attack. In order to solve the "needle in the haystack" problem of which samples to inspect, we develop a new scalable version of Cook's distance, a classical statistical technique for identifying samples which unusually strongly impact the fit of a regression model (and its downstream predictions). In order to scale this technique up to very large and high-dimensional datasets, we introduce a new algorithm which we call "influence sketching." Influence sketching embeds random projections within the influence computation; in particular, the influence score is calculated using the randomly projected pseudo-dataset from the post-convergence Generalized Linear Model (GLM). We validate that influence sketching can reliably and successfully discover influential samples by applying the technique to a malware detection dataset of over 2 million executable files, each represented with almost 100,000 features. For example, we find that randomly deleting approximately 10% of training samples reduces predictive accuracy only slightly from 99.47% to 99.45%, whereas deleting the same number of samples with high influence sketch scores reduces predictive accuracy all the way down to 90.24%. Moreover, we find that influential samples are especially likely to be mislabeled. In the case study, we manually inspect the most influential samples, and find that influence sketching pointed us to new, previously unidentified pieces of malware.
* fixed additional typos