 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Reduction Scheme for Constrained Contextual Bandits with Adversarial Contexts via Regression
Feb 04, 2026We study constrained contextual bandits (CCB) with adversarially chosen contexts, where each action yields a random reward and incurs a random cost. We adopt the standard realizability assumption: conditioned on the observed context, rewards and costs are drawn independently from fixed distributions whose expectations belong to known function classes. We consider the continuing setting, in which the algorithm operates over the entire horizon even after the budget is exhausted. In this setting, the objective is to simultaneously control regret and cumulative constraint violation. Building on the seminal SquareCB framework of Foster et al. (2018), we propose a simple and modular algorithmic scheme that leverages online regression oracles to reduce the constrained problem to a standard unconstrained contextual bandit problem with adaptively defined surrogate reward functions. In contrast to most prior work on CCB, which focuses on stochastic contexts, our reduction yields improved guarantees for the more general adversarial context setting, together with a compact and transparent analysis.
Optimal Anytime Algorithms for Online Convex Optimization with Adversarial Constraints
Oct 26, 2025We propose an anytime online algorithm for the problem of learning a sequence of adversarial convex cost functions while approximately satisfying another sequence of adversarial online convex constraints. A sequential algorithm is called \emph{anytime} if it provides a non-trivial performance guarantee for any intermediate timestep $t$ without requiring prior knowledge of the length of the entire time horizon $T$. Our proposed algorithm achieves optimal performance bounds without resorting to the standard doubling trick, which has poor practical performance due to multiple restarts. Our core technical contribution is the use of time-varying Lyapunov functions to keep track of constraint violations. This must be contrasted with prior works that used a fixed Lyapunov function tuned to the known horizon length $T$. The use of time-varying Lyapunov function poses unique analytical challenges as properties, such as \emph{monotonicity}, on which the prior proofs rest, no longer hold. By introducing a new analytical technique, we show that our algorithm achieves $O(\sqrt{t})$ regret and $\tilde{O}(\sqrt{t})$ cumulative constraint violation bounds for any $t\geq 1$. We extend our results to the dynamic regret setting, achieving bounds that adapt to the path length of the comparator sequence without prior knowledge of its total length. We also present an adaptive algorithm in the optimistic setting, whose performance gracefully scales with the cumulative prediction error. We demonstrate the practical utility of our algorithm through numerical experiments involving the online shortest path problem.
Universal Dynamic Regret and Constraint Violation Bounds for Constrained Online Convex Optimization
Oct 02, 2025We consider a generalization of the celebrated Online Convex Optimization (OCO) framework with online adversarial constraints. We present two algorithms having simple modular structures that yield universal dynamic regret and cumulative constraint violation bounds, improving upon the state-of-the-art results. Our results hold in the most general case when both the cost and constraint functions are chosen arbitrarily by an adversary, and the constraint functions need not contain any common feasible point. The results are established by reducing the constrained learning problem to an instance of the standard OCO problem with specially constructed surrogate cost functions.
Online Learning for Approximately-Convex Functions with Long-term Adversarial Constraints
Aug 23, 2025We study an online learning problem with long-term budget constraints in the adversarial setting. In this problem, at each round $t$, the learner selects an action from a convex decision set, after which the adversary reveals a cost function $f_t$ and a resource consumption function $g_t$. The cost and consumption functions are assumed to be $\alpha$-approximately convex - a broad class that generalizes convexity and encompasses many common non-convex optimization problems, including DR-submodular maximization, Online Vertex Cover, and Regularized Phase Retrieval. The goal is to design an online algorithm that minimizes cumulative cost over a horizon of length $T$ while approximately satisfying a long-term budget constraint of $B_T$. We propose an efficient first-order online algorithm that guarantees $O(\sqrt{T})$ $\alpha$-regret against the optimal fixed feasible benchmark while consuming at most $O(B_T \log T)+ \tilde{O}(\sqrt{T})$ resources in both full-information and bandit feedback settings. In the bandit feedback setting, our approach yields an efficient solution for the $\texttt{Adversarial Bandits with Knapsacks}$ problem with improved guarantees. We also prove matching lower bounds, demonstrating the tightness of our results. Finally, we characterize the class of $\alpha$-approximately convex functions and show that our results apply to a broad family of problems.
Beyond $\tilde{O}(\sqrt{T})$ Constraint Violation for Online Convex Optimization with Adversarial Constraints
May 10, 2025We revisit the Online Convex Optimization problem with adversarial constraints (COCO) where, in each round, a learner is presented with a convex cost function and a convex constraint function, both of which may be chosen adversarially. The learner selects actions from a convex decision set in an online fashion, with the goal of minimizing both regret and the cumulative constraint violation (CCV) over a horizon of $T$ rounds. The best-known policy for this problem achieves $O(\sqrt{T})$ regret and $\tilde{O}(\sqrt{T})$ CCV. In this paper, we present a surprising improvement that achieves a significantly smaller CCV by trading it off with regret. Specifically, for any bounded convex cost and constraint functions, we propose an online policy that achieves $\tilde{O}(\sqrt{dT}+ T^\beta)$ regret and $\tilde{O}(dT^{1-\beta})$ CCV, where $d$ is the dimension of the decision set and $\beta \in [0,1]$ is a tunable parameter. We achieve this result by first considering the special case of $\textsf{Constrained Expert}$ problem where the decision set is a probability simplex and the cost and constraint functions are linear. Leveraging a new adaptive small-loss regret bound, we propose an efficient policy for the $\textsf{Constrained Expert}$ problem, that attains $O(\sqrt{T\ln N}+T^{\beta})$ regret and $\tilde{O}(T^{1-\beta} \ln N)$ CCV, where $N$ is the number of experts. The original problem is then reduced to the $\textsf{Constrained Expert}$ problem via a covering argument. Finally, with an additional smoothness assumption, we propose an efficient gradient-based policy attaining $O(T^{\max(\frac{1}{2},\beta)})$ regret and $\tilde{O}(T^{1-\beta})$ CCV.
Online Bidding Algorithms with Strict Return on Spend (ROS) Constraint
Feb 08, 2025Auto-bidding problem under a strict return-on-spend constraint (ROSC) is considered, where an algorithm has to make decisions about how much to bid for an ad slot depending on the revealed value, and the hidden allocation and payment function that describes the probability of winning the ad-slot depending on its bid. The objective of an algorithm is to maximize the expected utility (product of ad value and probability of winning the ad slot) summed across all time slots subject to the total expected payment being less than the total expected utility, called the ROSC. A (surprising) impossibility result is derived that shows that no online algorithm can achieve a sub-linear regret even when the value, allocation and payment function are drawn i.i.d. from an unknown distribution. The problem is non-trivial even when the revealed value remains constant across time slots, and an algorithm with regret guarantee that is optimal up to logarithmic factor is derived.
$O(\sqrt{T})$ Static Regret and Instance Dependent Constraint Violation for Constrained Online Convex Optimization
Feb 07, 2025The constrained version of the standard online convex optimization (OCO) framework, called COCO is considered, where on every round, a convex cost function and a convex constraint function are revealed to the learner after it chooses the action for that round. The objective is to simultaneously minimize the static regret and cumulative constraint violation (CCV). An algorithm is proposed that guarantees a static regret of $O(\sqrt{T})$ and a CCV of $\min\{\cV, O(\sqrt{T}\log T) \}$, where $\cV$ depends on the distance between the consecutively revealed constraint sets, the shape of constraint sets, dimension of action space and the diameter of the action space. For special cases of constraint sets, $\cV=O(1)$. Compared to the state of the art results, static regret of $O(\sqrt{T})$ and CCV of $O(\sqrt{T}\log T)$, that were universal, the new result on CCV is instance dependent, which is derived by exploiting the geometric properties of the constraint sets.
Projection-free Algorithms for Online Convex Optimization with Adversarial Constraints
Jan 28, 2025



We study a generalization of the Online Convex Optimization (OCO) framework with time-varying adversarial constraints. In this problem, after selecting a feasible action from the convex decision set $X,$ a convex constraint function is revealed alongside the cost function in each round. Our goal is to design a computationally efficient learning policy that achieves a small regret with respect to the cost functions and a small cumulative constraint violation (CCV) with respect to the constraint functions over a horizon of length $T$. It is well-known that the projection step constitutes the major computational bottleneck of the standard OCO algorithms. However, for many structured decision sets, linear functions can be efficiently optimized over the decision set. We propose a *projection-free* online policy which makes a single call to a Linear Program (LP) solver per round. Our method outperforms state-of-the-art projection-free online algorithms with adversarial constraints, achieving improved bounds of $\tilde{O}(T^{\frac{3}{4}})$ for both regret and CCV. The proposed algorithm is conceptually simple - it first constructs a surrogate cost function as a non-negative linear combination of the cost and constraint functions. Then, it passes the surrogate costs to a new, adaptive version of the online conditional gradient subroutine, which we propose in this paper.
Tight Bounds for Online Convex Optimization with Adversarial Constraints
May 15, 2024
A well-studied generalization of the standard online convex optimization (OCO) is constrained online convex optimization (COCO). In COCO, on every round, a convex cost function and a convex constraint function are revealed to the learner after the action for that round is chosen. The objective is to design an online policy that simultaneously achieves a small regret while ensuring small cumulative constraint violation (CCV) against an adaptive adversary. A long-standing open question in COCO is whether an online policy can simultaneously achieve $O(\sqrt{T})$ regret and $O(\sqrt{T})$ CCV without any restrictive assumptions. For the first time, we answer this in the affirmative and show that an online policy can simultaneously achieve $O(\sqrt{T})$ regret and $\tilde{O}(\sqrt{T})$ CCV. We establish this result by effectively combining the adaptive regret bound of the AdaGrad algorithm with Lyapunov optimization - a classic tool from control theory. Surprisingly, the analysis is short and elegant.
Zero-shot Active Learning Using Self Supervised Learning
Jan 03, 2024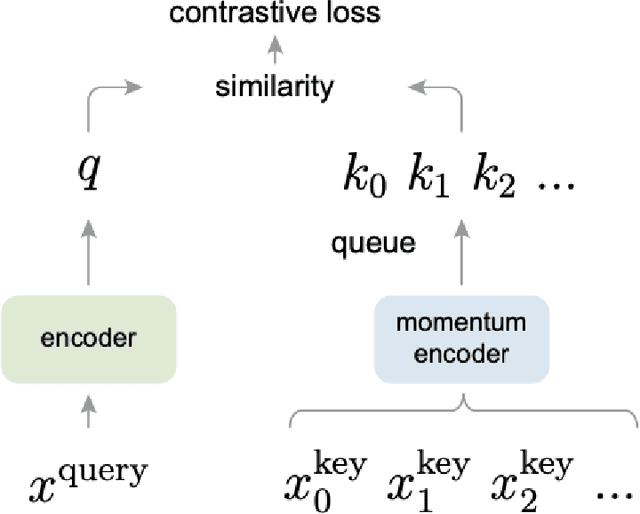
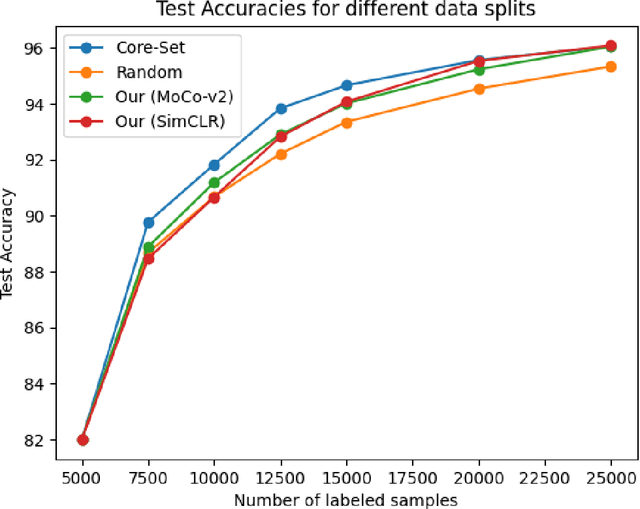
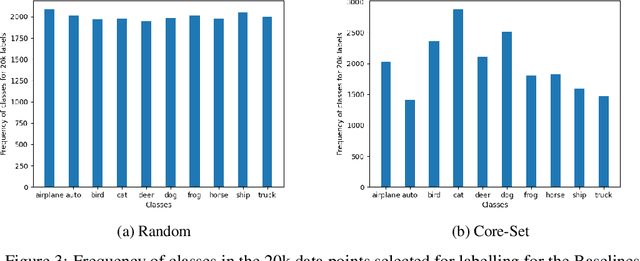
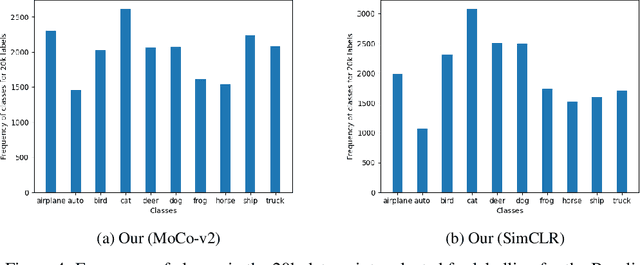
Deep learning algorithms are often said to be data hungry. The performance of such algorithms generally improve as more and more annotated data is fed into the model. While collecting unlabelled data is easier (as they can be scraped easily from the internet), annotating them is a tedious and expensive task. Given a fixed budget available for data annotation, Active Learning helps selecting the best subset of data for annotation, such that the deep learning model when trained over that subset will have maximum generalization performance under this budget. In this work, we aim to propose a new Active Learning approach which is model agnostic as well as one doesn't require an iterative process. We aim to leverage self-supervised learnt features for the task of Active Learning. The benefit of self-supervised learning, is that one can get useful feature representation of the input data, without having any annotation.