 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecure Generalization through Stochastic Bidirectional Parameter Updates Using Dual-Gradient Mechanism
Apr 03, 2025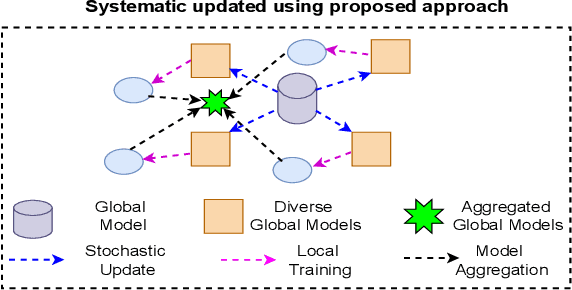
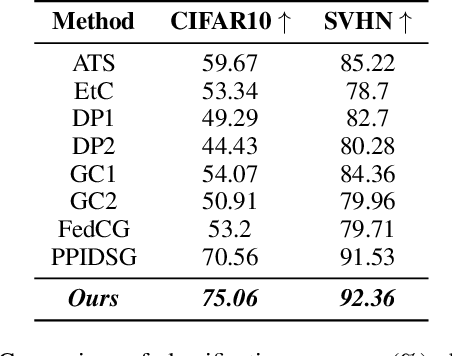
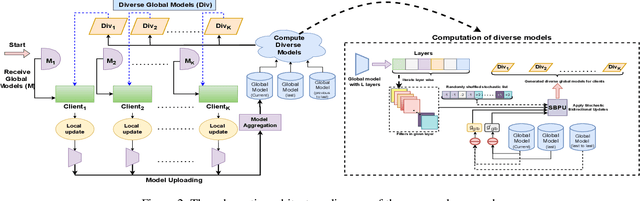
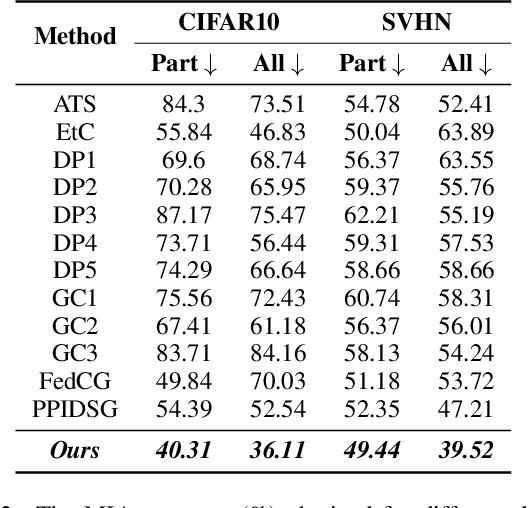
Federated learning (FL) has gained increasing attention due to privacy-preserving collaborative training on decentralized clients, mitigating the need to upload sensitive data to a central server directly. Nonetheless, recent research has underscored the risk of exposing private data to adversaries, even within FL frameworks. In general, existing methods sacrifice performance while ensuring resistance to privacy leakage in FL. We overcome these issues and generate diverse models at a global server through the proposed stochastic bidirectional parameter update mechanism. Using diverse models, we improved the generalization and feature representation in the FL setup, which also helped to improve the robustness of the model against privacy leakage without hurting the model's utility. We use global models from past FL rounds to follow systematic perturbation in parameter space at the server to ensure model generalization and resistance against privacy attacks. We generate diverse models (in close neighborhoods) for each client by using systematic perturbations in model parameters at a fine-grained level (i.e., altering each convolutional filter across the layers of the model) to improve the generalization and security perspective. We evaluated our proposed approach on four benchmark datasets to validate its superiority. We surpassed the state-of-the-art methods in terms of model utility and robustness towards privacy leakage. We have proven the effectiveness of our method by evaluating performance using several quantitative and qualitative results.
Confidence Is All You Need for MI Attacks
Nov 26, 2023
In this evolving era of machine learning security, membership inference attacks have emerged as a potent threat to the confidentiality of sensitive data. In this attack, adversaries aim to determine whether a particular point was used during the training of a target model. This paper proposes a new method to gauge a data point's membership in a model's training set. Instead of correlating loss with membership, as is traditionally done, we have leveraged the fact that training examples generally exhibit higher confidence values when classified into their actual class. During training, the model is essentially being 'fit' to the training data and might face particular difficulties in generalization to unseen data. This asymmetry leads to the model achieving higher confidence on the training data as it exploits the specific patterns and noise present in the training data. Our proposed approach leverages the confidence values generated by the machine learning model. These confidence values provide a probabilistic measure of the model's certainty in its predictions and can further be used to infer the membership of a given data point. Additionally, we also introduce another variant of our method that allows us to carry out this attack without knowing the ground truth(true class) of a given data point, thus offering an edge over existing label-dependent attack methods.