 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo GFlowNets Transfer? Case Study on the Game of 24/42
Mar 03, 2025Generating diverse solutions is key to human-like reasoning, yet autoregressive language models focus on single accurate responses, limiting creativity. GFlowNets optimize solution generation as a flow network, promising greater diversity. Our case study shows their limited zero-shot transferability by fine-tuning small and medium-sized large language models on the Game of 24 and testing them on the Game of 42 datasets. Results revealed that GFlowNets struggle to maintain solution diversity and accuracy, highlighting key limitations in their cross-task generalization and the need for future research in improved transfer learning capabilities.
Pruning as a Defense: Reducing Memorization in Large Language Models
Feb 18, 2025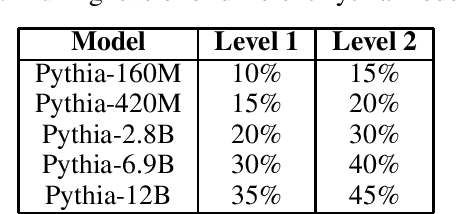
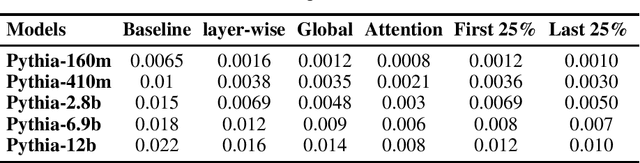
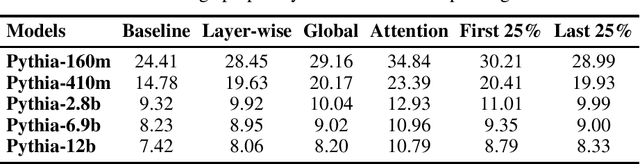
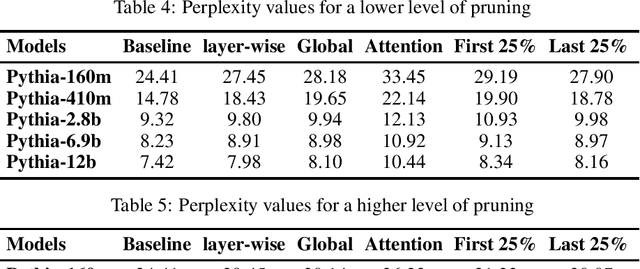
Large language models have been shown to memorize significant portions of their training data, which they can reproduce when appropriately prompted. This work investigates the impact of simple pruning techniques on this behavior. Our findings reveal that pruning effectively reduces the extent of memorization in LLMs, demonstrating its potential as a foundational approach for mitigating membership inference attacks.
Are VLMs Really Blind
Oct 29, 2024Vision Language Models excel in handling a wide range of complex tasks, including Optical Character Recognition (OCR), Visual Question Answering (VQA), and advanced geometric reasoning. However, these models fail to perform well on low-level basic visual tasks which are especially easy for humans. Our goal in this work was to determine if these models are truly "blind" to geometric reasoning or if there are ways to enhance their capabilities in this area. Our work presents a novel automatic pipeline designed to extract key information from images in response to specific questions. Instead of just relying on direct VQA, we use question-derived keywords to create a caption that highlights important details in the image related to the question. This caption is then used by a language model to provide a precise answer to the question without requiring external fine-tuning.
Beyond Captioning: Task-Specific Prompting for Improved VLM Performance in Mathematical Reasoning
Oct 08, 2024



Vision-Language Models (VLMs) have transformed tasks requiring visual and reasoning abilities, such as image retrieval and Visual Question Answering (VQA). Despite their success, VLMs face significant challenges with tasks involving geometric reasoning, algebraic problem-solving, and counting. These limitations stem from difficulties effectively integrating multiple modalities and accurately interpreting geometry-related tasks. Various works claim that introducing a captioning pipeline before VQA tasks enhances performance. We incorporated this pipeline for tasks involving geometry, algebra, and counting. We found that captioning results are not generalizable, specifically with larger VLMs primarily trained on downstream QnA tasks showing random performance on math-related challenges. However, we present a promising alternative: task-based prompting, enriching the prompt with task-specific guidance. This approach shows promise and proves more effective than direct captioning methods for math-heavy problems.
Confidence Is All You Need for MI Attacks
Nov 26, 2023
In this evolving era of machine learning security, membership inference attacks have emerged as a potent threat to the confidentiality of sensitive data. In this attack, adversaries aim to determine whether a particular point was used during the training of a target model. This paper proposes a new method to gauge a data point's membership in a model's training set. Instead of correlating loss with membership, as is traditionally done, we have leveraged the fact that training examples generally exhibit higher confidence values when classified into their actual class. During training, the model is essentially being 'fit' to the training data and might face particular difficulties in generalization to unseen data. This asymmetry leads to the model achieving higher confidence on the training data as it exploits the specific patterns and noise present in the training data. Our proposed approach leverages the confidence values generated by the machine learning model. These confidence values provide a probabilistic measure of the model's certainty in its predictions and can further be used to infer the membership of a given data point. Additionally, we also introduce another variant of our method that allows us to carry out this attack without knowing the ground truth(true class) of a given data point, thus offering an edge over existing label-dependent attack methods.
Classification of COVID-19 Patients with their Severity Level from Chest CT Scans using Transfer Learning
May 27, 2022
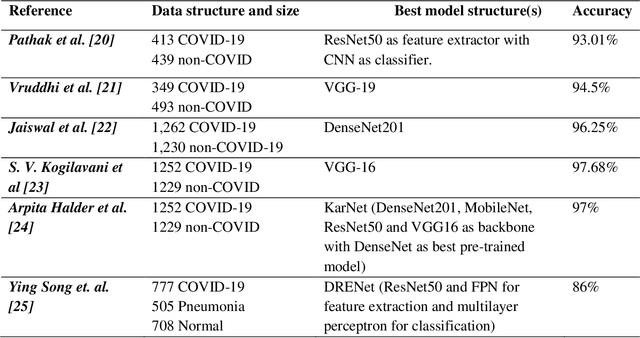


Background and Objective: During pandemics, the use of artificial intelligence (AI) approaches combined with biomedical science play a significant role in reducing the burden on the healthcare systems and physicians. The rapid increment in cases of COVID-19 has led to an increase in demand for hospital beds and other medical equipment. However, since medical facilities are limited, it is recommended to diagnose patients as per the severity of the infection. Keeping this in mind, we share our research in detecting COVID-19 as well as assessing its severity using chest-CT scans and Deep Learning pre-trained models. Dataset: We have collected a total of 1966 CT Scan images for three different class labels, namely, Non-COVID, Severe COVID, and Non-Severe COVID, out of which 714 CT images belong to the Non-COVID category, 713 CT images are for Non-Severe COVID category and 539 CT images are of Severe COVID category. Methods: All of the images are initially pre-processed using the Contrast Limited Histogram Equalization (CLAHE) approach. The pre-processed images are then fed into the VGG-16 network for extracting features. Finally, the retrieved characteristics are categorized and the accuracy is evaluated using a support vector machine (SVM) with 10-fold cross-validation (CV). Result and Conclusion: In our study, we have combined well-known strategies for pre-processing, feature extraction, and classification which brings us to a remarkable success rate of disease and its severity recognition with an accuracy of 96.05% (97.7% for Non-Severe COVID-19 images and 93% for Severe COVID-19 images). Our model can therefore help radiologists detect COVID-19 and the extent of its severity.
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021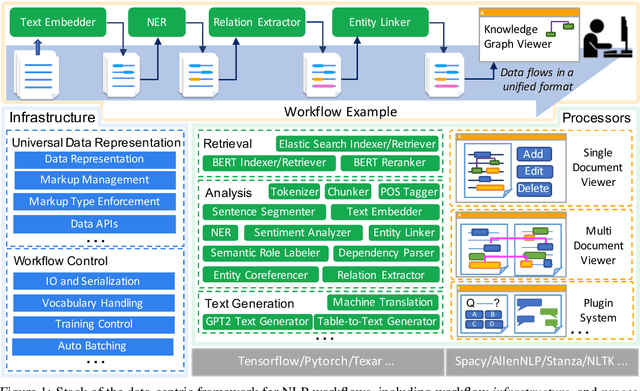
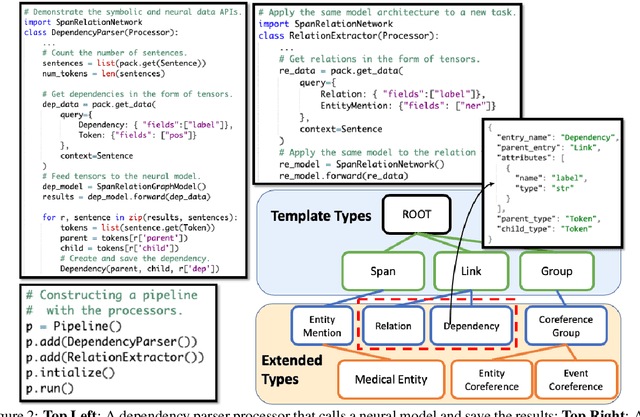
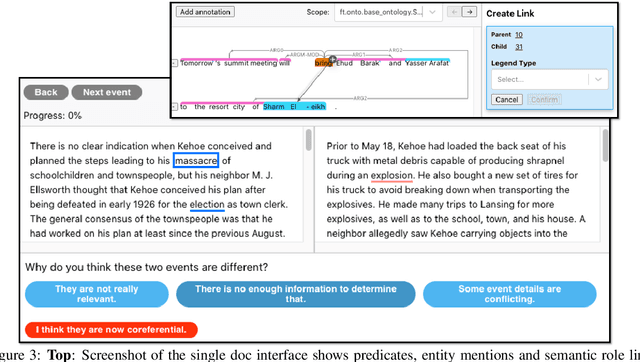

Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Learning to Deceive with Attention-Based Explanations
Sep 17, 2019
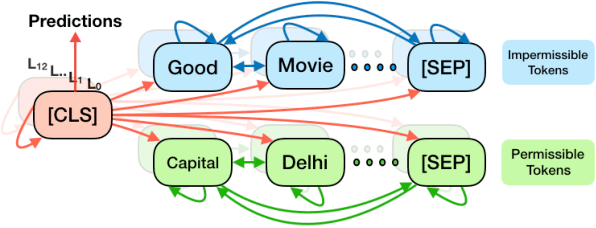

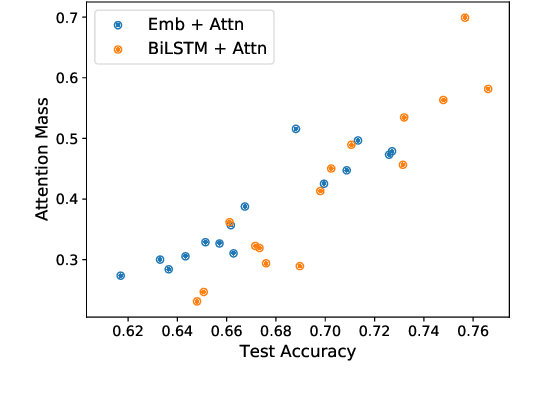
Attention mechanisms are ubiquitous components in neural architectures applied in natural language processing. In addition to yielding gains in predictive accuracy, researchers often claim that attention weights confer interpretability, purportedly useful both for providing insights to practitioners and for explaining why a model makes its decisions to stakeholders. We call the latter use of attention mechanisms into question, demonstrating a simple method for training models to produce deceptive attention masks, diminishing the total weight assigned to designated impermissible tokens, even as the models are shown to nevertheless rely on these features to drive predictions. Across multiple models and datasets, our approach manipulates attention weights while paying surprisingly little cost in accuracy. Although our results do not rule out potential insights due to organically-trained attention, they cast doubt on attention's reliability as a tool for auditing algorithms, as in the context of fairness and accountability.
AmazonQA: A Review-Based Question Answering Task
Aug 20, 2019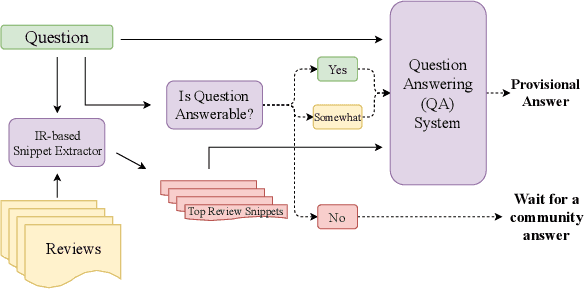
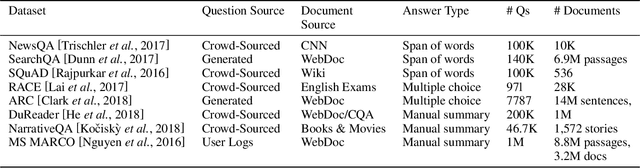
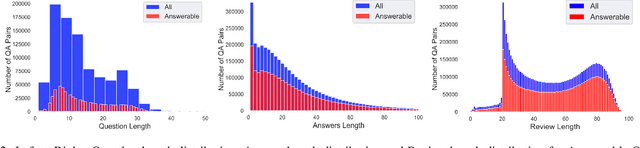
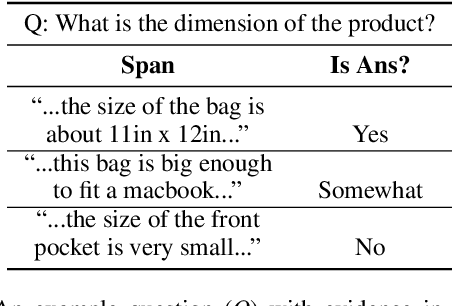
Every day, thousands of customers post questions on Amazon product pages. After some time, if they are fortunate, a knowledgeable customer might answer their question. Observing that many questions can be answered based upon the available product reviews, we propose the task of review-based QA. Given a corpus of reviews and a question, the QA system synthesizes an answer. To this end, we introduce a new dataset and propose a method that combines information retrieval techniques for selecting relevant reviews (given a question) and "reading comprehension" models for synthesizing an answer (given a question and review). Our dataset consists of 923k questions, 3.6M answers and 14M reviews across 156k products. Building on the well-known Amazon dataset, we collect additional annotations, marking each question as either answerable or unanswerable based on the available reviews. A deployed system could first classify a question as answerable and then attempt to generate an answer. Notably, unlike many popular QA datasets, here, the questions, passages, and answers are all extracted from real human interactions. We evaluate numerous models for answer generation and propose strong baselines, demonstrating the challenging nature of this new task.