 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPBench: Benchmarking the Knowledge of Large Language Models in Intellectual Property
Apr 22, 2025

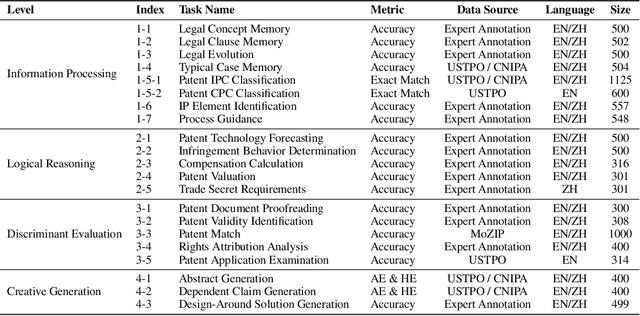
Intellectual Property (IP) is a unique domain that integrates technical and legal knowledge, making it inherently complex and knowledge-intensive. As large language models (LLMs) continue to advance, they show great potential for processing IP tasks, enabling more efficient analysis, understanding, and generation of IP-related content. However, existing datasets and benchmarks either focus narrowly on patents or cover limited aspects of the IP field, lacking alignment with real-world scenarios. To bridge this gap, we introduce the first comprehensive IP task taxonomy and a large, diverse bilingual benchmark, IPBench, covering 8 IP mechanisms and 20 tasks. This benchmark is designed to evaluate LLMs in real-world intellectual property applications, encompassing both understanding and generation. We benchmark 16 LLMs, ranging from general-purpose to domain-specific models, and find that even the best-performing model achieves only 75.8% accuracy, revealing substantial room for improvement. Notably, open-source IP and law-oriented models lag behind closed-source general-purpose models. We publicly release all data and code of IPBench and will continue to update it with additional IP-related tasks to better reflect real-world challenges in the intellectual property domain.
Forecasting Foreign Exchange Rates With Parameter-Free Regression Networks Tuned By Bayesian Optimization
Apr 26, 2022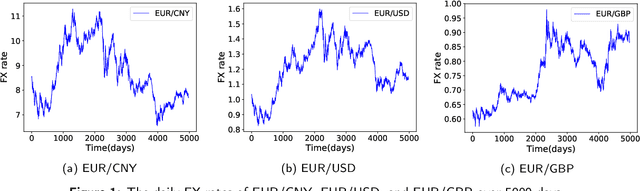



The article is concerned with the problem of multi-step financial time series forecasting of Foreign Exchange (FX) rates. To address this problem, we introduce a parameter-free regression network termed RegPred Net. The exchange rate to forecast is treated as a stochastic process. It is assumed to follow a generalization of Brownian motion and the mean-reverting process referred to as the generalized Ornstein-Uhlenbeck (OU) process, with time-dependent coefficients. Using past observed values of the input time series, these coefficients can be regressed online by the cells of the first half of the network (Reg). The regressed coefficients depend only on - but are very sensitive to - a small number of hyperparameters required to be set by a global optimization procedure for which, Bayesian optimization is an adequate heuristic. Thanks to its multi-layered architecture, the second half of the regression network (Pred) can project time-dependent values for the OU process coefficients and generate realistic trajectories of the time series. Predictions can be easily derived in the form of expected values estimated by averaging values obtained by Monte Carlo simulation. The forecasting accuracy on a 100 days horizon is evaluated for several of the most important FX rates such as EUR/USD, EUR/CNY, and EUR/GBP. Our experimental results show that the RegPred Net significantly outperforms ARMA, ARIMA, LSTMs, and Autoencoder-LSTM models in this task.
Towards Semantic Search for Community Question Answering for Mortgage Officers
Mar 14, 2022



Community Question Answering (CQA) has gained increasing popularity in many domains. Mortgage is a complex and dynamic industry, and a flexible and efficient CQA platform can potentially enhance the quality of service for mortgage officers significantly. We have built a dynamic CQA platform with a state of the art semantic search engine based on recent Natural Language Processing (NLP) techniques to dynamically and collectively capture and transfer the maturity and tribal knowledge of the more experienced workforce to less experienced ones. The search engine allows for both keyword and natural language queries and is based on a fine-tuned domain-adapted Sentence-BERT encoder linearly composed with a TF-IDF vectorizer, and reciprocal-rank fused with a BM25 vectorizer. Domain adaptation and fine-tuning is based on publicly available mortgage corpora. Evaluation is performed on an internally annotated dataset using standard information retrieval metrics such as normalized discounted cumulative gain (nDCG), precision/recall at n, mean reciprocal rank, and mean average precision (MAP). The results indicate that our hybrid, fine-tuned, domain-adapted search engine is a more effective approach in responding to the information needs of our mortgage officers compared to traditional search techniques. We aim to publish the internally-annotated evaluation and training datasets in the near future.
Cross-document Event Identity via Dense Annotation
Sep 14, 2021
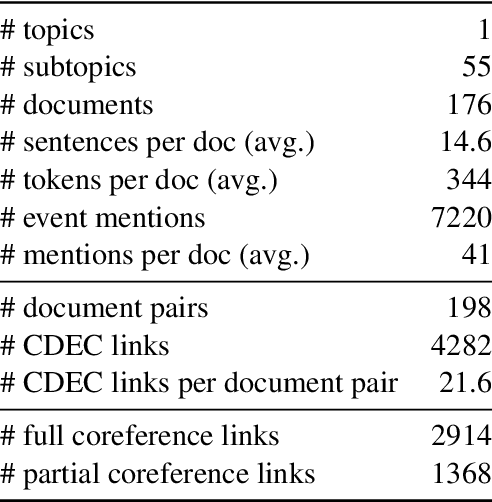


In this paper, we study the identity of textual events from different documents. While the complex nature of event identity is previously studied (Hovy et al., 2013), the case of events across documents is unclear. Prior work on cross-document event coreference has two main drawbacks. First, they restrict the annotations to a limited set of event types. Second, they insufficiently tackle the concept of event identity. Such annotation setup reduces the pool of event mentions and prevents one from considering the possibility of quasi-identity relations. We propose a dense annotation approach for cross-document event coreference, comprising a rich source of event mentions and a dense annotation effort between related document pairs. To this end, we design a new annotation workflow with careful quality control and an easy-to-use annotation interface. In addition to the links, we further collect overlapping event contexts, including time, location, and participants, to shed some light on the relation between identity decisions and context. We present an open-access dataset for cross-document event coreference, CDEC-WN, collected from English Wikinews and open-source our annotation toolkit to encourage further research on cross-document tasks.
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021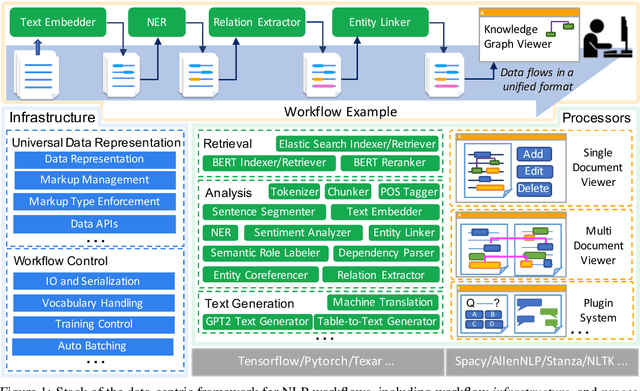
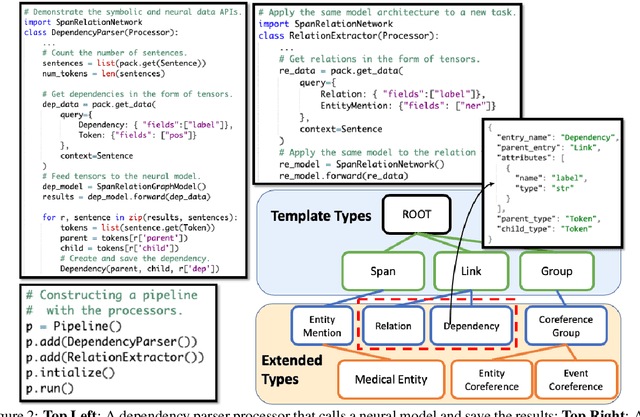
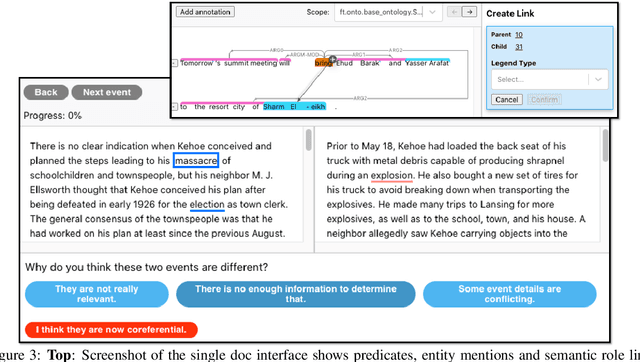

Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
YEDDA: A Lightweight Collaborative Text Span Annotation Tool
May 25, 2018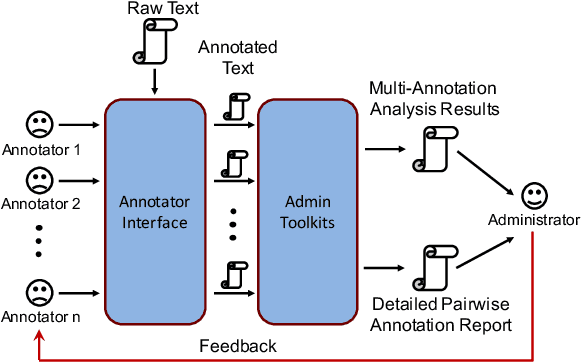
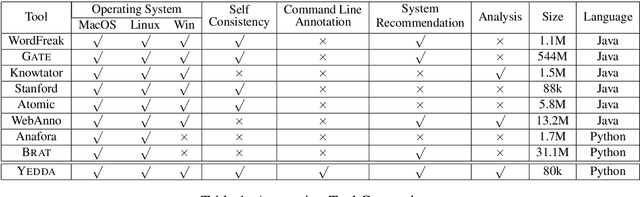

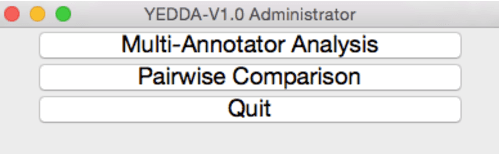
In this paper, we introduce \textsc{Yedda}, a lightweight but efficient and comprehensive open-source tool for text span annotation. \textsc{Yedda} provides a systematic solution for text span annotation, ranging from collaborative user annotation to administrator evaluation and analysis. It overcomes the low efficiency of traditional text annotation tools by annotating entities through both command line and shortcut keys, which are configurable with custom labels. \textsc{Yedda} also gives intelligent recommendations by learning the up-to-date annotated text. An administrator client is developed to evaluate annotation quality of multiple annotators and generate detailed comparison report for each annotator pair. Experiments show that the proposed system can reduce the annotation time by half compared with existing annotation tools. And the annotation time can be further compressed by 16.47\% through intelligent recommendation.
Person Identification from Partial Gait Cycle Using Fully Convolutional Neural Network
Apr 23, 2018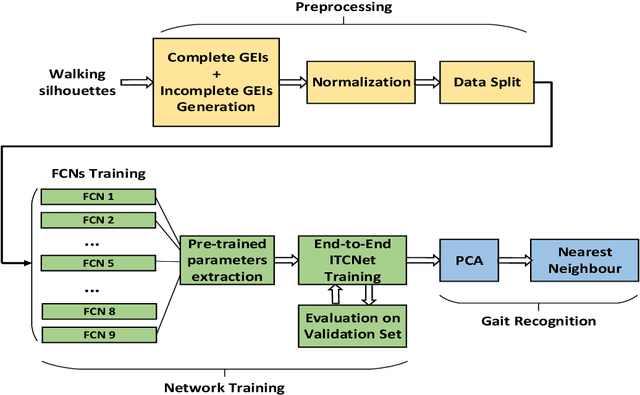
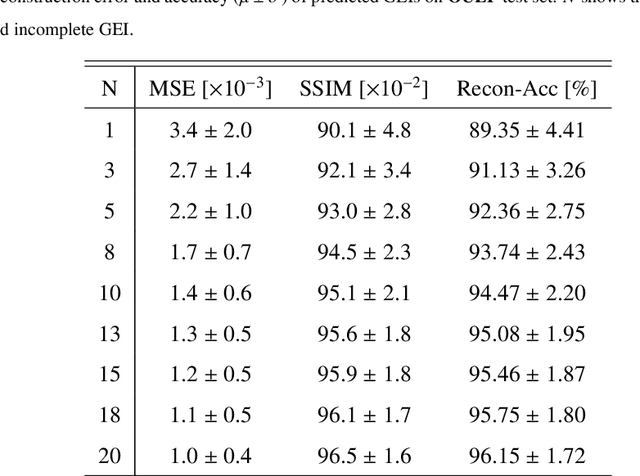
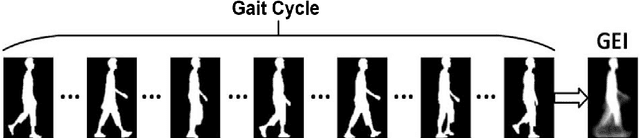
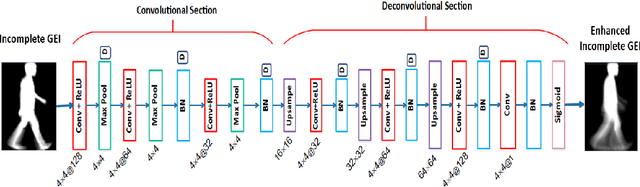
Gait as a biometric property for person identification plays a key role in video surveillance and security applications. In gait recognition, normally, gait feature such as Gait Energy Image (GEI) is extracted from one full gait cycle. However in many circumstances, such a full gait cycle might not be available due to occlusion. Thus, the GEI is not complete giving rise to a degrading in gait-based person identification rate. In this paper, we address this issue by proposing a novel method to identify individuals from gait feature when a few (or even single) frame(s) is available. To do so, we propose a deep learning-based approach to transform incomplete GEI to the corresponding complete GEI obtained from a full gait cycle. More precisely, this transformation is done gradually by training several auto encoders independently and then combining these as a uniform model. Experimental results on two public gait datasets, namely OULP and Casia-B demonstrate the validity of the proposed method in dealing with very incomplete gait cycles.