 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormulation Comparison for Timeline Construction using LLMs
Mar 01, 2024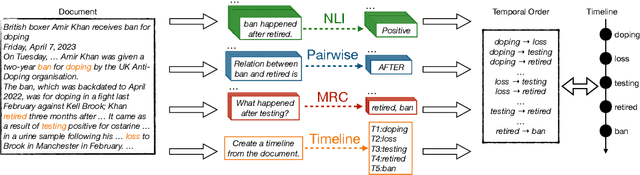
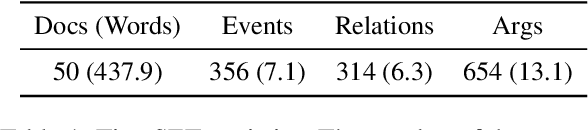

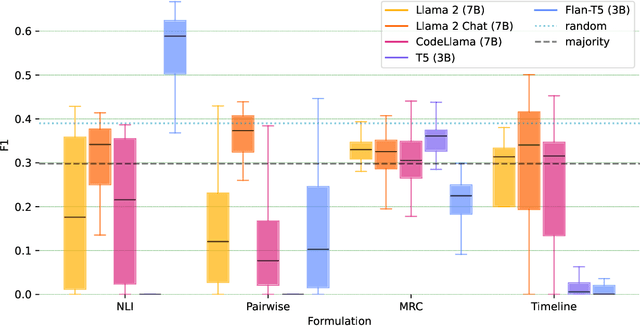
Constructing a timeline requires identifying the chronological order of events in an article. In prior timeline construction datasets, temporal orders are typically annotated by either event-to-time anchoring or event-to-event pairwise ordering, both of which suffer from missing temporal information. To mitigate the issue, we develop a new evaluation dataset, TimeSET, consisting of single-document timelines with document-level order annotation. TimeSET features saliency-based event selection and partial ordering, which enable a practical annotation workload. Aiming to build better automatic timeline construction systems, we propose a novel evaluation framework to compare multiple task formulations with TimeSET by prompting open LLMs, i.e., Llama 2 and Flan-T5. Considering that identifying temporal orders of events is a core subtask in timeline construction, we further benchmark open LLMs on existing event temporal ordering datasets to gain a robust understanding of their capabilities. Our experiments show that (1) NLI formulation with Flan-T5 demonstrates a strong performance among others, while (2) timeline construction and event temporal ordering are still challenging tasks for few-shot LLMs. Our code and data are available at https://github.com/kimihiroh/timeset.
Cross-document Event Identity via Dense Annotation
Sep 14, 2021
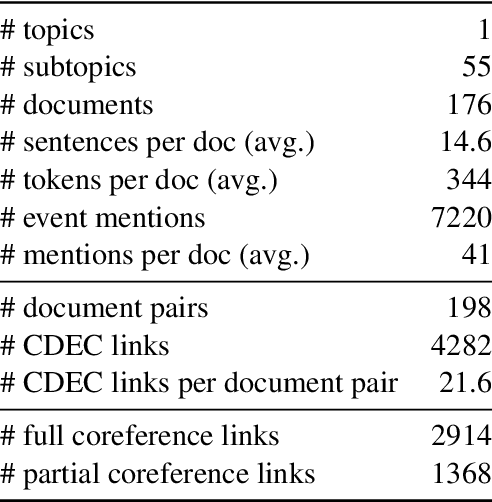


In this paper, we study the identity of textual events from different documents. While the complex nature of event identity is previously studied (Hovy et al., 2013), the case of events across documents is unclear. Prior work on cross-document event coreference has two main drawbacks. First, they restrict the annotations to a limited set of event types. Second, they insufficiently tackle the concept of event identity. Such annotation setup reduces the pool of event mentions and prevents one from considering the possibility of quasi-identity relations. We propose a dense annotation approach for cross-document event coreference, comprising a rich source of event mentions and a dense annotation effort between related document pairs. To this end, we design a new annotation workflow with careful quality control and an easy-to-use annotation interface. In addition to the links, we further collect overlapping event contexts, including time, location, and participants, to shed some light on the relation between identity decisions and context. We present an open-access dataset for cross-document event coreference, CDEC-WN, collected from English Wikinews and open-source our annotation toolkit to encourage further research on cross-document tasks.