 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Optimal Context Length for Hybrid Retrieval-augmented Multi-document Summarization
Apr 17, 2025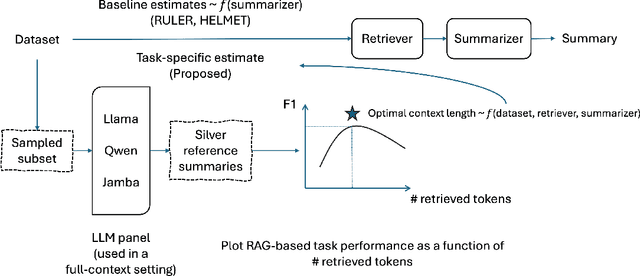

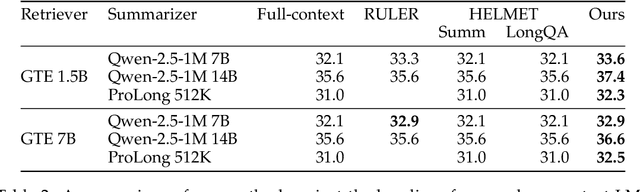

Recent advances in long-context reasoning abilities of language models led to interesting applications in large-scale multi-document summarization. However, prior work has shown that these long-context models are not effective at their claimed context windows. To this end, retrieval-augmented systems provide an efficient and effective alternative. However, their performance can be highly sensitive to the choice of retrieval context length. In this work, we present a hybrid method that combines retrieval-augmented systems with long-context windows supported by recent language models. Our method first estimates the optimal retrieval length as a function of the retriever, summarizer, and dataset. On a randomly sampled subset of the dataset, we use a panel of LLMs to generate a pool of silver references. We use these silver references to estimate the optimal context length for a given RAG system configuration. Our results on the multi-document summarization task showcase the effectiveness of our method across model classes and sizes. We compare against length estimates from strong long-context benchmarks such as RULER and HELMET. Our analysis also highlights the effectiveness of our estimation method for very long-context LMs and its generalization to new classes of LMs.
Scaling Multi-Document Event Summarization: Evaluating Compression vs. Full-Text Approaches
Feb 10, 2025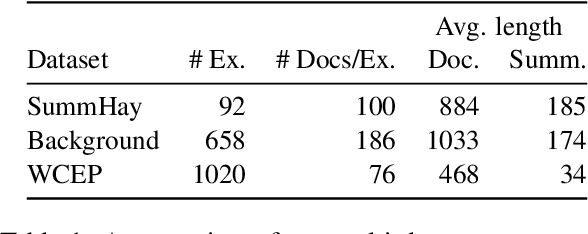



Automatically summarizing large text collections is a valuable tool for document research, with applications in journalism, academic research, legal work, and many other fields. In this work, we contrast two classes of systems for large-scale multi-document summarization (MDS): compression and full-text. Compression-based methods use a multi-stage pipeline and often lead to lossy summaries. Full-text methods promise a lossless summary by relying on recent advances in long-context reasoning. To understand their utility on large-scale MDS, we evaluated them on three datasets, each containing approximately one hundred documents per summary. Our experiments cover a diverse set of long-context transformers (Llama-3.1, Command-R, Jamba-1.5-Mini) and compression methods (retrieval-augmented, hierarchical, incremental). Overall, we find that full-text and retrieval methods perform the best in most settings. With further analysis into the salient information retention patterns, we show that compression-based methods show strong promise at intermediate stages, even outperforming full-context. However, they suffer information loss due to their multi-stage pipeline and lack of global context. Our results highlight the need to develop hybrid approaches that combine compression and full-text approaches for optimal performance on large-scale multi-document summarization.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Calibrated Seq2seq Models for Efficient and Generalizable Ultra-fine Entity Typing
Nov 01, 2023



Ultra-fine entity typing plays a crucial role in information extraction by predicting fine-grained semantic types for entity mentions in text. However, this task poses significant challenges due to the massive number of entity types in the output space. The current state-of-the-art approaches, based on standard multi-label classifiers or cross-encoder models, suffer from poor generalization performance or inefficient inference. In this paper, we present CASENT, a seq2seq model designed for ultra-fine entity typing that predicts ultra-fine types with calibrated confidence scores. Our model takes an entity mention as input and employs constrained beam search to generate multiple types autoregressively. The raw sequence probabilities associated with the predicted types are then transformed into confidence scores using a novel calibration method. We conduct extensive experiments on the UFET dataset which contains over 10k types. Our method outperforms the previous state-of-the-art in terms of F1 score and calibration error, while achieving an inference speedup of over 50 times. Additionally, we demonstrate the generalization capabilities of our model by evaluating it in zero-shot and few-shot settings on five specialized domain entity typing datasets that are unseen during training. Remarkably, our model outperforms large language models with 10 times more parameters in the zero-shot setting, and when fine-tuned on 50 examples, it significantly outperforms ChatGPT on all datasets. Our code, models and demo are available at https://github.com/yanlinf/CASENT.
Background Summarization of Event Timelines
Oct 24, 2023Generating concise summaries of news events is a challenging natural language processing task. While journalists often curate timelines to highlight key sub-events, newcomers to a news event face challenges in catching up on its historical context. In this paper, we address this need by introducing the task of background news summarization, which complements each timeline update with a background summary of relevant preceding events. We construct a dataset by merging existing timeline datasets and asking human annotators to write a background summary for each timestep of each news event. We establish strong baseline performance using state-of-the-art summarization systems and propose a query-focused variant to generate background summaries. To evaluate background summary quality, we present a question-answering-based evaluation metric, Background Utility Score (BUS), which measures the percentage of questions about a current event timestep that a background summary answers. Our experiments show the effectiveness of instruction fine-tuned systems such as Flan-T5, in addition to strong zero-shot performance using GPT-3.5.
Hierarchical Event Grounding
Feb 08, 2023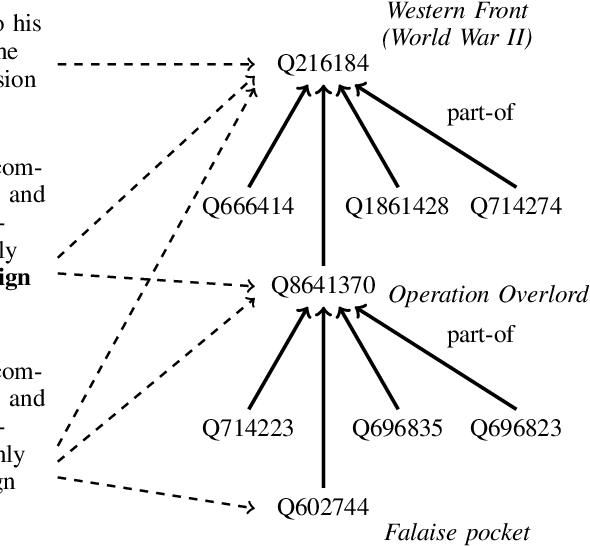
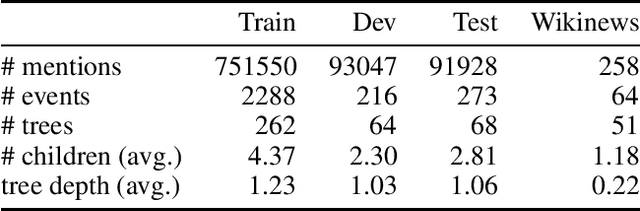
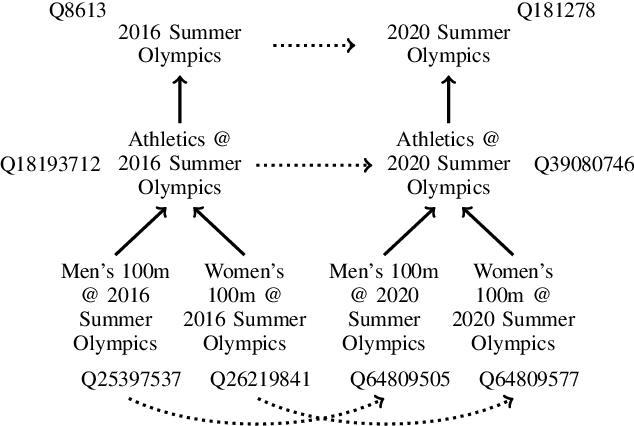
Event grounding aims at linking mention references in text corpora to events from a knowledge base (KB). Previous work on this task focused primarily on linking to a single KB event, thereby overlooking the hierarchical aspects of events. Events in documents are typically described at various levels of spatio-temporal granularity (Glavas et al. 2014). These hierarchical relations are utilized in downstream tasks of narrative understanding and schema construction. In this work, we present an extension to the event grounding task that requires tackling hierarchical event structures from the KB. Our proposed task involves linking a mention reference to a set of event labels from a subevent hierarchy in the KB. We propose a retrieval methodology that leverages event hierarchy through an auxiliary hierarchical loss (Murty et al. 2018). On an automatically created multilingual dataset from Wikipedia and Wikidata, our experiments demonstrate the effectiveness of the hierarchical loss against retrieve and re-rank baselines (Wu et al. 2020; Pratapa, Gupta, and Mitamura 2022). Furthermore, we demonstrate the systems' ability to aid hierarchical discovery among unseen events.
Multilingual Event Linking to Wikidata
Apr 13, 2022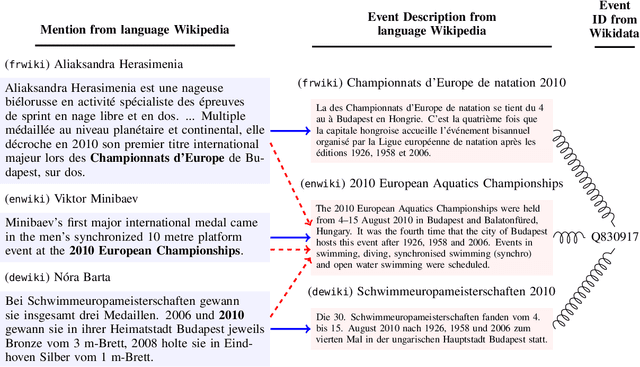
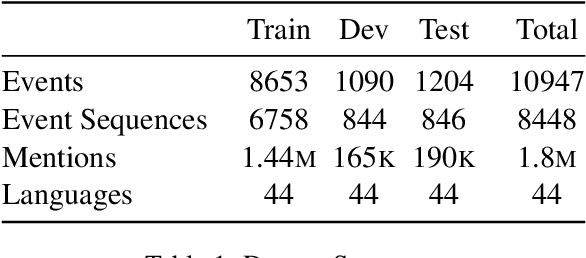


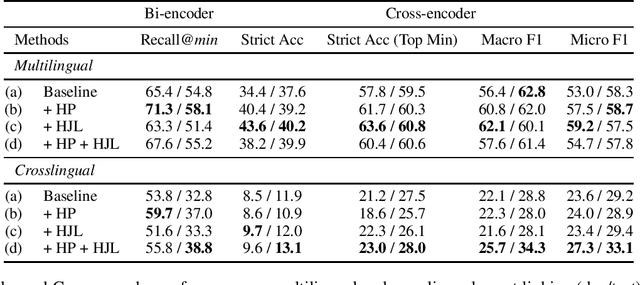
We present a task of multilingual linking of events to a knowledge base. We automatically compile a large-scale dataset for this task, comprising of 1.8M mentions across 44 languages referring to over 10.9K events from Wikidata. We propose two variants of the event linking task: 1) multilingual, where event descriptions are from the same language as the mention, and 2) crosslingual, where all event descriptions are in English. On the two proposed tasks, we compare multiple event linking systems including BM25+ (Lv and Zhai, 2011) and multilingual adaptations of the biencoder and crossencoder architectures from BLINK (Wu et al., 2020). In our experiments on the two task variants, we find both biencoder and crossencoder models significantly outperform the BM25+ baseline. Our results also indicate that the crosslingual task is in general more challenging than the multilingual task. To test the out-of-domain generalization of the proposed linking systems, we additionally create a Wikinews-based evaluation set. We present qualitative analysis highlighting various aspects captured by the proposed dataset, including the need for temporal reasoning over context and tackling diverse event descriptions across languages.
Cross-document Event Identity via Dense Annotation
Sep 14, 2021
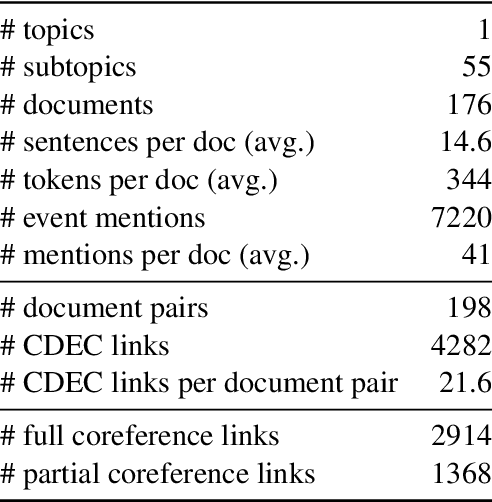


In this paper, we study the identity of textual events from different documents. While the complex nature of event identity is previously studied (Hovy et al., 2013), the case of events across documents is unclear. Prior work on cross-document event coreference has two main drawbacks. First, they restrict the annotations to a limited set of event types. Second, they insufficiently tackle the concept of event identity. Such annotation setup reduces the pool of event mentions and prevents one from considering the possibility of quasi-identity relations. We propose a dense annotation approach for cross-document event coreference, comprising a rich source of event mentions and a dense annotation effort between related document pairs. To this end, we design a new annotation workflow with careful quality control and an easy-to-use annotation interface. In addition to the links, we further collect overlapping event contexts, including time, location, and participants, to shed some light on the relation between identity decisions and context. We present an open-access dataset for cross-document event coreference, CDEC-WN, collected from English Wikinews and open-source our annotation toolkit to encourage further research on cross-document tasks.
Evaluating the Morphosyntactic Well-formedness of Generated Texts
Mar 30, 2021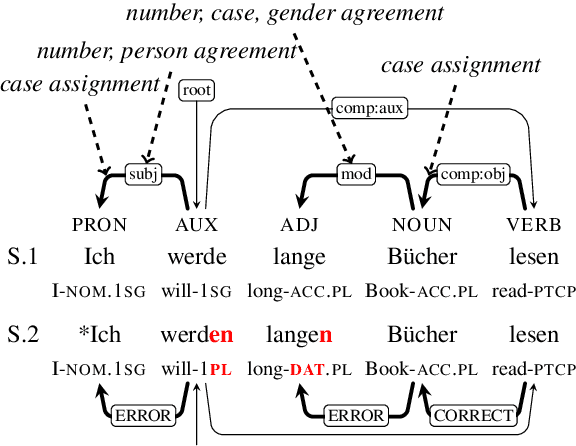

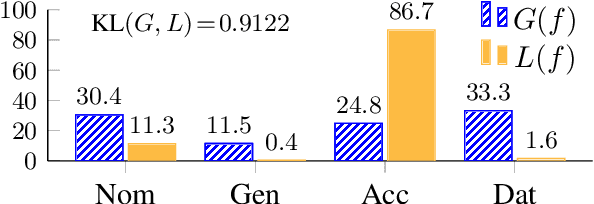

Text generation systems are ubiquitous in natural language processing applications. However, evaluation of these systems remains a challenge, especially in multilingual settings. In this paper, we propose L'AMBRE -- a metric to evaluate the morphosyntactic well-formedness of text using its dependency parse and morphosyntactic rules of the language. We present a way to automatically extract various rules governing morphosyntax directly from dependency treebanks. To tackle the noisy outputs from text generation systems, we propose a simple methodology to train robust parsers. We show the effectiveness of our metric on the task of machine translation through a diachronic study of systems translating into morphologically-rich languages.
Automatic Extraction of Rules Governing Morphological Agreement
Oct 06, 2020

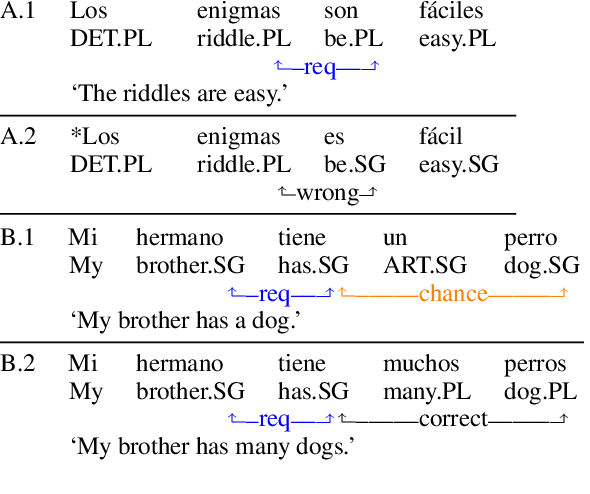
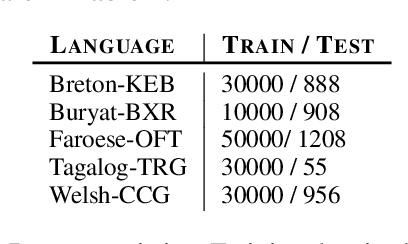
Creating a descriptive grammar of a language is an indispensable step for language documentation and preservation. However, at the same time it is a tedious, time-consuming task. In this paper, we take steps towards automating this process by devising an automated framework for extracting a first-pass grammatical specification from raw text in a concise, human- and machine-readable format. We focus on extracting rules describing agreement, a morphosyntactic phenomenon at the core of the grammars of many of the world's languages. We apply our framework to all languages included in the Universal Dependencies project, with promising results. Using cross-lingual transfer, even with no expert annotations in the language of interest, our framework extracts a grammatical specification which is nearly equivalent to those created with large amounts of gold-standard annotated data. We confirm this finding with human expert evaluations of the rules that our framework produces, which have an average accuracy of 78%. We release an interface demonstrating the extracted rules at https://neulab.github.io/lase/.